数据读取之逻辑读简单解析--关于BUFFER CACHE
数据读取之逻辑读简单解析--BUFFER CACHE
ROWID OBJECT_NAME OBJECT_ID STATUS
------------------ ------------ ---------- -------
AAAFSJAAEAAAACrAAA UNDO$ 15 VALID
使用下面语句查出相应行的FILE_ID,BLOCK_ID,关于ROWID,详见:http://blog.csdn.net/q947817003/article/details/11490051
col object_name for a12
col colname for a10
select a.rowid,a.object_id,a.file_id,a.block_id,a.row_num,b.object_name,a.colname from
(select rowid,
dbms_rowid.rowid_object(rowid) object_id,
dbms_rowid.rowid_relative_fno(rowid) file_id,
dbms_rowid.rowid_block_number(rowid) block_id,
dbms_rowid.rowid_row_number(rowid) row_num,
&colname as colname from &tablename t) a,
dba_objects b
where a.object_id=b.object_id;
运行上述语句,按提示输入:&colname 列名 ;&tablename 表名即可显示类似以下信息: 我这里是输入 test 表的object_name列
ROWID OBJECT_ID FILE_ID BLOCK_ID ROW_NUM OBJECT_NAME COLNAME
------------------ ---------- ---------- ---------- ---------- ------------ ----------
AAAFSJAAEAAAACrAAD 21641 4 171 3 TEST I_USER1
AAAFSJAAEAAAACrAAC 21641 4 171 2 TEST CON$
AAAFSJAAEAAAACrAAB 21641 4 171 1 TEST ICOL$
AAAFSJAAEAAAACrAAA 21641 4 171 0 TEST UNDO$
#############################
BH :buffer header 存放有文件号 block#等摘要信息,与数据块头的信息类似功能。BH buffer header----block_buffers块个数是一一对应的,事实上相等。BH buffer header的大小在我的实验环境是264byte,9I据说是 188byte
CBC :多个BH组成 Cache Buffer Chain (CBC) --一般情况下一个
buffers block是BUFFER CACHE中存放数据库具体数据的块--默认8K-等于数据库块
数据读取方式:BUFFER CACHE中一次只能读一块;磁盘上可以一次读多个连续的块
NAME TYPE VALUE
------------------------------------ -----------
db_cache_size big integer 48M
如果是动态SGA管理,应该查:select * from v$sga_dynamic_components;
SYS@ bys3>show parameter db_block_s
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192
需要使用到的查询语句:
[oracle@bys3 admin]$ pwd ---存放在$ORACLE_HOME的/rdbms/admin目录下
/u01/app/oracle/product/11.2.0/dbhome_1/rdbms/admin
[oracle@bys3 admin]$ cat show_para.sql 脚本具体内容如下:感谢guoyJoe大师的脚本哈哈
col p_name for a40
col p_DESCRIPTION for a50
col p_value for a30
set linesize 10000
SELECT i.ksppinm p_name, i.ksppdesc p_description, CV.ksppstvl p_VALUE, CV.ksppstdf isdefault, DECODE (BITAND (CV.ksppstvf, 7),1, 'MODIFIED',4, 'SYSTEM_MOD', 'FALSE') ismodified, DECODE (BITAND (CV.ksppstvf, 2), 2, 'TRUE', 'FALSE') isadjusted
FROM sys.x$ksppi i, sys.x$ksppcv CV
WHERE i.inst_id = USERENV ('Instance') AND CV.inst_id = USERENV ('Instance') AND i.indx = CV.indx AND upper(i.ksppinm) LIKE upper('%&p%') ORDER BY REPLACE (i.ksppinm, '_', '');
运行此脚本,查询隐含参数:
SYS@ bys3>@?/rdbms/admin/show_para
Enter value for p: hash_buckets
_db_block_hash_buckets 16384 -两个8192大小
Enter value for p: block_buffers
_db_block_buffers 5952
重启后依然是这个值
#############################
BH的大小计算-- 即db_cache_size的大小减去block_buffers*8K --这里数据库的默认块大小是8K
SYS@ bys3>select (48*1024-5952*8)*1024/5952 abytes from dual;
ABYTES
----------
264.258065 --这里是264byte,9I据说是 188byte.
#############################
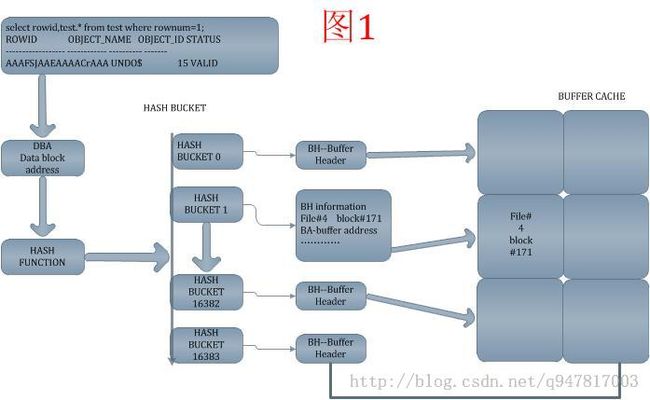
-->>首先查出第一行数据的ROWID--使用有dbms_rowid.ROWID_BLOCK_NUMBER(rowid),
-->>根据ROWID得出DBA
-->>到SGA中BUFFER CACHE查找此数据。
-->>首先把DBA信息使用内部HASH函数进行运算
-->>根据生成值找到相应HASH BUCKER(包含首、尾BH地址) --共享池
-->>BH buffer header --内部表x$bh,在BH中找到BA信息 buffer address
-->>根据BH中的BA信息,就找到了BUFFER CACHE中存放所要查询数据块具体数据的内存块
-->>返回数据至相应的查询进程;一次逻辑读到此完成。
一、实验数据准备--查出一条数据的ROWID,及FILE_ID,BLOCK_ID等信息
BYS@ bys3>select rowid,test.* from test where rownum=1;ROWID OBJECT_NAME OBJECT_ID STATUS
------------------ ------------ ---------- -------
AAAFSJAAEAAAACrAAA UNDO$ 15 VALID
使用下面语句查出相应行的FILE_ID,BLOCK_ID,关于ROWID,详见:http://blog.csdn.net/q947817003/article/details/11490051
col object_name for a12
col colname for a10
select a.rowid,a.object_id,a.file_id,a.block_id,a.row_num,b.object_name,a.colname from
(select rowid,
dbms_rowid.rowid_object(rowid) object_id,
dbms_rowid.rowid_relative_fno(rowid) file_id,
dbms_rowid.rowid_block_number(rowid) block_id,
dbms_rowid.rowid_row_number(rowid) row_num,
&colname as colname from &tablename t) a,
dba_objects b
where a.object_id=b.object_id;
运行上述语句,按提示输入:&colname 列名 ;&tablename 表名即可显示类似以下信息: 我这里是输入 test 表的object_name列
ROWID OBJECT_ID FILE_ID BLOCK_ID ROW_NUM OBJECT_NAME COLNAME
------------------ ---------- ---------- ---------- ---------- ------------ ----------
AAAFSJAAEAAAACrAAD 21641 4 171 3 TEST I_USER1
AAAFSJAAEAAAACrAAC 21641 4 171 2 TEST CON$
AAAFSJAAEAAAACrAAB 21641 4 171 1 TEST ICOL$
AAAFSJAAEAAAACrAAA 21641 4 171 0 TEST UNDO$
#############################
二、关于BH buffer header,buckets,block_buffers介绍: --可结合下面图1对比
1.概念介绍
HASH BUCKET 在共享池中 一种数据结构-数组,双向链表,指针指向BH;正常情况下,buckets的数量大约是block_buffers的两倍多BH :buffer header 存放有文件号 block#等摘要信息,与数据块头的信息类似功能。BH buffer header----block_buffers块个数是一一对应的,事实上相等。BH buffer header的大小在我的实验环境是264byte,9I据说是 188byte
CBC :多个BH组成 Cache Buffer Chain (CBC) --一般情况下一个
buffers block是BUFFER CACHE中存放数据库具体数据的块--默认8K-等于数据库块
数据读取方式:BUFFER CACHE中一次只能读一块;磁盘上可以一次读多个连续的块
2.BH buffer header,buckets,block_buffers个数查询:
SYS@ bys3>show parameter db_cache_sNAME TYPE VALUE
------------------------------------ -----------
db_cache_size big integer 48M
如果是动态SGA管理,应该查:select * from v$sga_dynamic_components;
SYS@ bys3>show parameter db_block_s
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192
需要使用到的查询语句:
[oracle@bys3 admin]$ pwd ---存放在$ORACLE_HOME的/rdbms/admin目录下
/u01/app/oracle/product/11.2.0/dbhome_1/rdbms/admin
[oracle@bys3 admin]$ cat show_para.sql 脚本具体内容如下:感谢guoyJoe大师的脚本哈哈
col p_name for a40
col p_DESCRIPTION for a50
col p_value for a30
set linesize 10000
SELECT i.ksppinm p_name, i.ksppdesc p_description, CV.ksppstvl p_VALUE, CV.ksppstdf isdefault, DECODE (BITAND (CV.ksppstvf, 7),1, 'MODIFIED',4, 'SYSTEM_MOD', 'FALSE') ismodified, DECODE (BITAND (CV.ksppstvf, 2), 2, 'TRUE', 'FALSE') isadjusted
FROM sys.x$ksppi i, sys.x$ksppcv CV
WHERE i.inst_id = USERENV ('Instance') AND CV.inst_id = USERENV ('Instance') AND i.indx = CV.indx AND upper(i.ksppinm) LIKE upper('%&p%') ORDER BY REPLACE (i.ksppinm, '_', '');
运行此脚本,查询隐含参数:
SYS@ bys3>@?/rdbms/admin/show_para
Enter value for p: hash_buckets
_db_block_hash_buckets 16384 -两个8192大小
Enter value for p: block_buffers
_db_block_buffers 5952
重启后依然是这个值
#############################
3.BH buffer header大小
BH buffer header----block_buffers块个数是一一对应的,事实上相等BH的大小计算-- 即db_cache_size的大小减去block_buffers*8K --这里数据库的默认块大小是8K
SYS@ bys3>select (48*1024-5952*8)*1024/5952 abytes from dual;
ABYTES
----------
264.258065 --这里是264byte,9I据说是 188byte.
#############################
三.结合图1,解析发出查询语句,ORACLE如何读数据?
select a from b where rownum=1;语句发出后,-->>首先查出第一行数据的ROWID--使用有dbms_rowid.ROWID_BLOCK_NUMBER(rowid),
-->>根据ROWID得出DBA
-->>到SGA中BUFFER CACHE查找此数据。
-->>首先把DBA信息使用内部HASH函数进行运算
-->>根据生成值找到相应HASH BUCKER(包含首、尾BH地址) --共享池
-->>BH buffer header --内部表x$bh,在BH中找到BA信息 buffer address
-->>根据BH中的BA信息,就找到了BUFFER CACHE中存放所要查询数据块具体数据的内存块
-->>返回数据至相应的查询进程;一次逻辑读到此完成。
作者:q947817003 发表于2013-12-5 13:55:44 原文链接
阅读:90 评论:0 查看评论