Zookeeper【最新版V3.4.6】- 翻译系列 1: FAQ
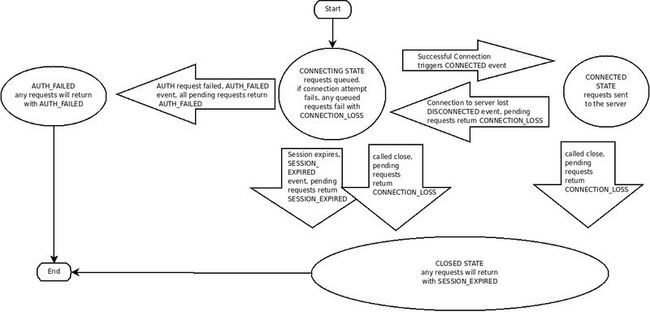
ZooKeeper客户端可以通过创建一个ZooKeeper的句柄,从而与ZooKeeper服务建立一个会话(session)。会话创建之后,句柄的初始状态为CONNECTING状态,此时客户端句柄会尝试与ZooKeeper服务器建立连接,此服务器会指明此句柄将状态设置为CONNECTED。在常规操作中只会有这两种状态,如果有任何不可恢复的错误发生,比如会话失效、权限验证失败、应用强制关闭句柄等等,此句柄状态会转变为CLOSED状态。下图展现了客户端句柄可能出现的状态转换:
What are the state transitions of ZooKeeper?
为了创建一个客户端会话,应用程序代码必须提供一个连接字符串,此字符串包括一系列以逗号分开的“主机名:端口”对,每个“主机名:端口”均对应一个ZooKeeper服务器(例如:127.0.0.1:3000,128.0.0.1:2001)。ZooKeeper的客户端句柄会随机挑选一个ZooKeeper服务器并尝试与之创建连接。如果连接建立失败,或因为任何原因客户端与此服务器断开连接,此客户端都会自动尝试列表中的下一个服务器,直到连接建立。
3.2版本新添加:一个可选后缀“chroot”也可以添加在连接字符串末尾,那么在所有与此根路径相关的路径解释时都会执行此指令(与unix的chmod指令相似)。例如若连接字符串为“127.0.0.1:3000,127.0.0.1:3002/app/a”,那么客户端会将根目录建立在/app/a路径中。所有路径的根目录都会被重定向到此目录。如/foo/bar路径的读写操作都会被重定向到/app/a/foo/bar路径(从服务器端看是这样的)。这项新添加的功能在多应用公用ZooKeeper时非常有用,此功能使每个应用都能更简便的处理路径指定,就好像每个应用都在使用“/”路径一样。
当客户端从ZooKeeper服务获取到一个句柄,那么ZooKeeper服务会创建一个ZooKeeper会话,此会话以64bit的数字表示。之后ZooKeeper服务将此会话分配给客户端。如果客户端下次连接到其他的ZooKeeper服务器,那么客户端会将先前获取到的会话ID作为连接握手的一部分发送。出于安全考虑,ZooKeeper服务器会为每个会话ID创建一个所有ZooKeeper服务器都可以检验的密码,此密码会在客户端建立会话时随着会话ID一同发送给客户端。那么客户端会在下次与新的ZooKeeper服务器建立会话时将此密码与会话ID一同发送。
客户端创建ZooKeeper会话时会发送一个会话超时时间毫秒值参数,客户端发送一个请求的超时时间,服务器会响应一个它可以给客户端的超时时间。当前的实现要求此值最小必须为心跳时间(心跳时间在服务器配置文件中指定)的二倍,最大不得超过为心跳时间的二十倍。ZooKeeper客户端API允许协商超时时间。
当客户端会话与ZK服务断开连接之后,客户端会搜索创建此会话的服务器列表。若最终此会话与至少一个ZK服务器重新建立连接,那么此会话会被重新转换为CONNECTED状态;若在超时时间之内不能重新建立连接则此会话会被转换为expired状态。我们不建议你为断开连接的会话重新建立新的会话,因为ZK客户端库会自动为你的会话重新建立连接。特别是我们已经启发式的将ZK客户端库建立为处理类似于"羊群效应"这种情况,你最好只在收到会话失效通知的情况下才重新建立会话。
会话失效是由ZK服务器管理的而不是客户端,当客户端创建一个会话时,它会按上文描述的那样提供一个会话超时时间,ZK服务器会根据此值决定当前会话是否超时。若在超时时间之内ZK服务器没有收到客户端的消息(除了心跳),则ZK服务器会判定此会话超时无效。在会话无效之后,ZK服务器会删除所有此会话创建的瞬时节点并且立即通知其他每个监视这些节点且未断开连接的客户端(他们监视的瞬时节点已不存在了)。此时这个失效会话与ZK集群仍然处于断开连接状态,此会话客户端不会收到上述通知除非此客户端又重新建立了到ZK集群的连接。此客户端会一直处于未连接状态直到与ZK集群的TCP连接重新被建立,此时这个失效会话的监视者将会收到一个会话失效("session expired")通知。
下述为一个超时会话在它的监视者眼中的状态转换实例:
“connected”:会话建立且客户端与ZK集群成功建立连接。
…… 客户端与集群分开。
“disconnected”:客户端已与ZK集群失去联系。
…… 时间消逝,ZK集群判定会话失效之后,由于客户端已失去联系因此客户端不知道发生的一切。
…… 时间消逝,客户端重新获取与ZK服务器之间网络层的联系。
“expired”:最终客户端与ZK服务器重新建立连接,然后客户端被通知此会话已失效(为什么客户端不能自己先判断一下会话是否超时,以减少向ZK服务器的多余请求呢?)。
ZK会话建立的另一个参数叫做默认监视者。在客户端有任何状态改变发生时监视者(在ZK服务器端)都会得到通知,例如,如果客户端与ZK服务器实现联系则客户端(?)会得到通知,或者如果客户端会话失效也会得到通知等等。监视者将客户端的初始状态当做未连接状态(disconnected:在任何状态改变事件被客户端库发送至监视者之前)。在新连接建立时,发送至监视者的第一个事件通常都是会话连接建立事件。
会话的保持活跃请求是由客户端发起的。如果会话空闲了一段时间并且将要超时失效,客户端会发送一个PING请求以保持连接存活。PING请求不仅仅会让ZK服务器知道客户端仍然还活着并且它也会让客户端验证它与ZK服务器之间的联系仍然也活着(ZK服务器也有可能宕机)。PING的时间间隔应该是足够保守以保证能够在合理的时间内察觉到一个死链(ZK服务器宕机)并且及时的重新与一个新ZK服务器建立连接。
一旦客户端与ZK服务器之间的连接建立(connected),从根本上来说当一个同步或异步的操作执行时客户端库导致连接失去(C里面是返回结束码,java里面是抛出异常 -- 参加API文档)的情况有两种:
应用程序在一个不再有效的会话上调用一个操作。
当还有未完成的ZK服务器异步操作请求时,ZK客户端断开了与ZK服务器的连接。
3.2版本新添加 -- SessionMovedException:有一个客户端不可见的内部异常叫做SessionMovedException,此异常会在ZK服务器收到了一个指定会话的连接请求,但此会话已经在其他服务器上重新建立了连接时发生。此异常发生通常是因为一个客户端向一个ZK服务器发送一个请求,但是网络包延迟导致客户端超时而与一个新的服务器建立连接。之后当这个延迟了的网络包最终慢吞吞到达最初的ZK服务器时,ZK服务器检测到此会话已经被移动到另外一个ZK服务器上面并且关闭连接。客户端通常不会发现此异常因为他们不会从旧的连接中读取数据(这些旧连接通常都是已关闭的)。此异常出现的一种情况是当两个客户端都尝试使用同一个会话ID和密码与ZK服务器建立相同的连接。这两个客户端中的一个会成功建立连接而另外一个则会被断开连接。
ZooKeeper监视(Watches)
ZooKeeper中的所有读操作(getDate(), getChildren(), exists())都有一个设置监视者的选项。ZooKeeper中监视者的定义为:一个监视事件是一次性的触发器,此触发器会在监视数据发生改变时被触发并发送给设置此监视器的客户端。以下为一个监视器定义的三个关键点:
一次性触发器:当数据改变时一个监视事件会被发送给客户端。例如,如果一个客户端执行了getDate("/znode1", true)并且之后 /znode1 上的数据被改变会删除,此客户端会接受到一个 /node1 的监视事件。如果此节点又改变了,则此时间不会再发生,除非此客户端又执行了一次getDate("/znode1", true)并且设置了一个新的监视器。
发生往客户端:这说明一个监视事件是发送往客户端A的,但是当另一个客户端B执行数据更新时,在客户端B收到从服务器返回的更新操作成功代码时,客户端A的监视事件也许还没有到达客户端A呢。监视事件是被异步的发送往监视者的。ZooKeeper提供了一个顺序上的保证:如果客户端A没有看到这个监视事件,那么客户端A它永远也看不到这个改变(是这个新数据它看不到么,即使主动请求?)。网络延迟或其他因素或许会导致多个客户端在不同时间看到监视时间和更新的返回码。关键在于不同的客户端看到的所有数据都有一个一致的顺序。
被设置了监视器的数据:这表示一个节点会有多种改变,ZooKeeper有两种监视:数据监视和子节点监视。getData()和exists()可以设置数据监视器,getChildren()可以设置子节点监视器。因此setData()会激活数据监视器,而create()会激活子节点监视器,一个成功的delete()操作会激活两种监视器,因为此操作会删除数据和所有子节点。
监视器被客户端所连接的ZK服务器所持有,这允许监视器可以被轻松的设置、维持和发送。当此客户端连接到一个新的ZK服务器,监视器会被以任何会话事件激活(?)。当客户端与ZK服务器断开连接则它不会再收到任何监视事件。当客户端重新建立连接,先前注册的监视器都会被重新注册并且根据需要被激活。通常这一系列操作都是透明进行的,有一种情况下,监视器也许会出现失误:监视的节点在先前客户端断开连接期间已经被创建和删除。
ZooKeeper对监视器的保证
对于监视器,ZooKeeper有以下保证:
监视事件会与其他的事件、异步响应有序排列,ZooKeeper客户端库会保证任何事都会按需发送(即无论怎么延迟等等,ZK客户端库都会按需将这些事件交给应用)。
客户端会在看到一个ZNode的新数据之前先接收到先前在此ZNode上注册的监视事件。
监视事件的顺序会按照ZK服务器所看到的数据更新数据发送(即那个节点先更新,那个节点的监视事件先到达应用)。
ZK监视器中应该记住的事:
监视器是一次性触发器,如果你想收到更多的监视通知,你必须一次又一次的注册监视器。
监视器是一次性触发的,并且在获取到监视事件之前也许会存在一些延迟,因此你也许不会看到在ZK服务器中节点数据的全部改变。你要对这种情况做好准备:在你接收到监视事件并注册新事件之前,此节点的数据已经改变过多次。(你一般也不必在意这种情况 -- 反正都是读取最新的数据,但是好歹你也得明白。)
相同的触发事件仅仅会引起一次监视事件,也就是说如果你执行多次getData()并绑定了相同的监视器,之后如果此数据被更新,那么你先前绑定的多个监视器仅会被触发一次。
当你与服务器断开连接时(如当服务器宕机),你不会获取到任何监视事件除非连接又重新建立。因为这个原因会话事件会被发送到所有未处理的监视句柄。使用会话事件进入安全模式:在断开连接期间你不会收到任何监视事件,因此你的程序应该在此期间小心从事。—— 这个搞不明白什么意思,好像我理解错了。。。
ZooKeeper使用ACL进行权限控制
ZK使用ACL来控制指定ZNode的访问,ACL的实现与Unix文件访问许可非常相似:它用许可bit位来表示一个ZNode上各种操作的允许或不允许。与标准Unix许可不同的是,一个ZK节点的访问权限并不为特定的三种用户(拥有者、用户组、全局)范围限制。ZK并没有一个节点拥有者的概念,ZK通过指定ID和这些ID相关联的许可来进行权限限制。要注意的是一个ACL只与指定的ZNode有关,尤其注意的是,这个ACL并不作用于子节点,如果/app仅对于ip:172.0.0.1可读但是/app/status却可以对所有IP都可见。因为ACL并不会覆盖子节点的ACL。
ZK支持可插拔的权限模块,ID使用scheme:id这种格式指定。例如:ip:127.0.0.1。ACL是以(scheme:expression, perms)对组成。例如 (ip:19.22.0.0/16, READ) 将读权限交给任何IP地址以19.22开始的客户端。
ACL权限
ZooKeeper支持下列权限:
CREATE:你可以创建一个子节点
READ:你可以读取数据,并且可以读取子节点列表
WRITE:你可以写入数据
DELETE:你可以删除一个子节点
ADMIN:你可以改变ACL
CREATE和DELETE权限已经从WRITE中提取出来了,这样做是为了更加细微的权限控制。CREATE和DELETE分割出来的原因是:你想让一个客户端只能修改一个ZNode中的数据但是不能创建或删除子节点。ADMIN权限的存在是因为ZK没有ZNode拥有者这个概念,因此ADMIN权限可以扮演拥有者这个角色。ZK不支持LOOKUP权限,ZK内在的设定所有用户都有LOOKUP权限,这允许你可以查看ZNode的状态,但是你只能看这么多。(问题是,如果你想要在一个并不存在的ZNode上调用zoo_exists(),那么并没有权限列表进行判断是否有权限,因此ZK才内含所有人都有LOOKUP权限)。
ACL的固定模式
ZooKeeper有下列的固定模式
world:有个单一的ID,anyone,表示任何人。
auth:不使用任何ID,表示任何通过验证的用户(是通过ZK验证的用户?连接到此ZK服务器的用户?)。
digest:使用 用户名:密码 字符串生成MD5哈希值作为ACL标识符ID。权限的验证通过直接发送用户名密码字符串的方式完成,
ip:使用客户端主机ip地址作为一个ACL标识符,ACL表达式是以 addr/bits 这种格式表示的。ZK服务器会将addr的前bits位与客户端地址的前bits位来进行匹配验证权限。
确保全局一致性
ZooKeeper是一个高性能的、可伸缩的服务。读写操作都被设计为尽可能快的。尽管读操作通常都比写操作要快很多,读写同样快的原因是对于读操作而言,ZK会返回更旧的数据,反过来而言,这正是由于ZooKeeper的一致性保证。
顺序保证:客户端的更新操作会按照客户端发送这些更新请求的顺序完成。
原子性:更新要么成功要么失败 -- 不会出现部分成功或失败。
单一系统映像:客户端无论连接在ZK集群的那个服务器上,永远只会看到同一副映像。
可靠性:一旦一次更新完成,那么此更新将一直存在直到下一次更新覆盖此次更新。这个保证有两种必然结果:如果客户端得到一个成功返回码,那么更新操作就说明已被成功执行。如果出现失败(通信错误、超时等等)那么客户端将不会知道此次更新是否已经被应用到ZK服务器。我们采取一些办法来最小化失败造成的影响,但是我们只能保证只有在得到那个成功返回码时才说明更新成功。(—— 感觉有问题,总之就是这个意思了)。任何由客户端通过读请求或成功更新操作发送的更新请求将用于不会被回滚,即便是在服务器宕机恢复期间。
及时性:ZK系统的客户端视图可以保证在一定时间范围内是实时的,在这几十秒内,系统的更新会对所有客户端都可见。否则客户端就应该检查一下它所连接的ZK服务是否已终止。
使用这些一致性保证,我们能很容易的在客户端构建更高层次的功能,比如领袖选举、队列、可回滚读写锁等等。
提示:有时候开发者会误认为ZooKeeper能够确保一些ZK本不能确保的事,那就是"客户端视图之间的同步"。ZooKeeper并不保证在任何时候任何情况下,两个不同的客户端都会获取到ZooKeeper数据的同一份视图。由于一些比如网络延迟等因素,一个客户端也许会在另一个客户端接受到更新通知之前完成更新(有问题)。例如,如果有两个客户端A和B,如果客户端A将节点/a的值从0变为1,然后告诉B去读取此值,此时客户端有可能还是读到0而不是1,这取决于B连接在那台服务器上和网络的延迟等等。如果此值的同步对A和B都非常重要,那么客户端B应该在执行读操作之前调用一次sync()方法。
Java Binding(还有C呢,我不用它)
ZK客户端库中有两个包组成了ZK binding功能:org.apache.zookeeper和org.apache.zookeeper.data。其余的包是被其内部使用的或者仅仅是服务器实现的一部分,开发者不必了解。org.apache.zookeeper.data包由一些被简单的用作容器的普通类组成。
ZooKeeper的java客户端库的主类是ZooKeeper类,此类的构造方法们之间仅仅在可选的会话ID和密码参数有无有差别。ZK支持程应用程序恢复会话,一个java程序可以将它的会话ID和密码持久化保存在硬盘介质中,重启之后可以使用会话ID和密码重新恢复此会话。
当一个ZooKeeper对象初始化时,它也会创建两个线程:一个IO线程和一个事件线程。所有的IO操作都通过IO线程进行,所有的事件回调都在事件线程中进行。会话的维护工作比如连接重建和心跳机制都在IO线程上完成,同步方法调用也是在IO线程上完成。所有的异步方法响应和监视事件都由事件线程处理。下面列出这种做法的结果和好处:
所有的异步调用和监视事件回调都可以一次一个的很容易的排列。调用者可以做它想做的任何处理,此时不会有其他回调操作进行。
回调操作不会阻塞IO线程的进行,也不会阻塞同步请求的进行。
同步调用也许不会按正确的顺序返回。例如,假设一个客户端做下列请求:客户端发起了被监视的节点/a的一个异步读操作(此节点的更新导致监视事件发生),在这个异步读回调操作完成时客户端又对节点/a发起了一个同步读操作。如果在这个异步读和同步读两个时间段中间此数据发生了改变,客户端库会接收到表示/a节点更新的监视事件,也许此时异步读回调操作还没有完成,但是此时再发起同步读则会因为监视事件已经发送,因此此客户端能够读到最新的数据,而异步读操作读到的是旧数据(这个例子迷迷糊糊的。。。)
最后,ZK客户端的关闭过程也很简单:当ZooKeeper对象被主动关闭或者收到一个致命的事件(SESSION_EXPIRED和AUTO_FAILED),ZooKeeper对象就会变为无效状态。关闭时,两个线程都会被关闭并且之后任何在此ZooKeeper之上的操作都是未知结果的,这种操作应该被避免。
异常处理:ZK操作时有可能会出现异常KeeperException,如果在此异常上调用code()方法会获取到特定的错误码。你可以查看API文档查看具体的异常详情和不同错误码代表什么意思。
半天时间没保存。。
How should I handle the CONNECTION_LOSS error?
CONNECTION_LOSS means the link between the client and server was broken. It doesn't necessarily mean that the request failed. If you are doing a create request and the link was broken after the request reached the server and before the response was returned, the create request will succeed. If the link was broken before the packet went onto the wire, the create request failed. Unfortunately, there is no way for the client library to know, so it returns CONNECTION_LOSS. The programmer must figure out if the request succeeded or needs to be retried. Usually this is done in an application specific way. Examples of success detection include checking for the presence of a file to be created or checking the value of a znode to be modified.
When a client (session) becomes partitioned from the ZK serving cluster it will begin searching the list of servers that were specified during session creation. Eventually, when connectivity between the client and at least one of the servers is re-established, the session will either again transition to the "connected" state (if reconnected within the session timeout value) or it will transition to the "expired" state (if reconnected after the session timeout). The ZK client library will handle reconnect for you automatically. In particular we have heuristics built into the client library to handle things like "herd effect", etc... Only create a new session when you are notified of session expiration (mandatory).
How should I handle SESSION_EXPIRED?
SESSION_EXPIRED automatically closes the ZooKeeper handle. In a correctly operating cluster, you should never see SESSION_EXPIRED. It means that the client was partitioned off from the ZooKeeper service for more the the session timeout and ZooKeeper decided that the client died. Because the ZooKeeper service is ground truth, the client should consider itself dead and go into recovery. If the client is only reading state from ZooKeeper, recovery means just reconnecting. In more complex applications, recovery means recreating ephemeral nodes, vying for leadership roles, and reconstructing published state.
Library writers should be conscious of the severity of the expired state and not try to recover from it. Instead libraries should return a fatal error. Even if the library is simply reading from ZooKeeper, the user of the library may also be doing other things with ZooKeeper that requires more complex recovery.
Session expiration is managed by the ZooKeeper cluster itself, not by the client. When the ZK client establishes a session with the cluster it provides a "timeout" value. This value is used by the cluster to determine when the client's session expires. Expirations happens when the cluster does not hear from the client within the specified session timeout period (i.e. no heartbeat). At session expiration the cluster will delete any/all ephemeral nodes owned by that session and immediately notify any/all connected clients of the change (anyone watching those znodes). At this point the client of the expired session is still disconnected from the cluster, it will not be notified of the session expiration until/unless it is able to re-establish a connection to the cluster. The client will stay in disconnected state until the TCP connection is re-established with the cluster, at which point the watcher of the expired session will receive the "session expired" notification.
Example state transitions for an expired session as seen by the expired session's watcher:
'connected' : session is established and client is communicating with cluster (client/server communication is operating properly)
.... client is partitioned from the cluster
'disconnected' : client has lost connectivity with the cluster
.... time elapses, after 'timeout' period the cluster expires the session, nothing is seen by client as it is disconnected from cluster
.... time elapses, the client regains network level connectivity with the cluster
'expired' : eventually the client reconnects to the cluster, it is then notified of the expiration
Is there an easy way to expire a session for testing?
Yes, a ZooKeeper handle can take a session id and password. This constructor is used to recover a session after total application failure. For example, an application can connect to ZooKeeper, save the session id and password to a file, terminate, restart, read the session id and password, and reconnect to ZooKeeper without loosing the session and the corresponding ephemeral nodes. It is up to the programmer to ensure that the session id and password isn't passed around to multiple instances of an application, otherwise problems can result.
In the case of testing we want to cause a problem, so to explicitly expire a session an application connects to ZooKeeper, saves the session id and password, creates another ZooKeeper handle with that id and password, and then closes the new handle. Since both handles reference the same session, the close on second handle will invalidate the session causing a SESSION_EXPIRED on the first handle.
Why doesn't the NodeChildrenChanged and NodeDataChanged watch events return more information about the change?
When a ZooKeeper server generates the change events, it knows exactly what the change is. In our initial implementation of ZooKeeper we returned this information with the change event, but it turned out that it was impossible to use correctly. There may be a correct way to use it, but we have never seen a case of correct usage. The problem is that watches are used to find out about the latest change. (Otherwise, you would just do periodic gets.) The thing that most programmers seem to miss, when they ask for this feature, is that watches are one time triggers. Observe the following case of data change: a process does a getData on "/a" with watch set to true and gets "v1", another process changes "/a" to "v2" and shortly there after changes "/a" to "v3". The first process would see that "/a" was changed to "v2", but wouldn't know that "/a" is now "/v3".
What are the options-process for upgrading ZooKeeper?
There are two primary ways of doing this; 1) full restart or 2) rolling restart.
In the full restart case you can stage your updated code/configuration/etc..., stop all of the servers in the ensemble, switch code/configuration, and restart the ZooKeeper ensemble. If you do this programmatically (scripts typically, ie not by hand) the restart can be done on order of seconds. As a result the clients will lose connectivity to the ZooKeeper cluster during this time, however it looks to the clients just like a network partition. All existing client sessions are maintained and re-established as soon as the ZooKeeper ensemble comes back up. Obviously one drawback to this approach is that if you encounter any issues (it's always a good idea to test/stage these changes on a test harness) the cluster may be down for longer than expected.
The second option, preferable for many users, is to do a "rolling restart". In this case you upgrade one server in the ZooKeeper ensemble at a time; bring down the server, upgrade the code/configuration/etc..., then restart the server. The server will automatically rejoin the quorum, update it's internal state with the current ZK leader, and begin serving client sessions. As a result of doing a rolling restart, rather than a full restart, the administrator can monitor the ensemble as the upgrade progresses, perhaps rolling back if any issues are encountered.
How do I size a ZooKeeper ensemble (cluster)?
In general when determining the number of ZooKeeper serving nodes to deploy (the size of an ensemble) you need to think in terms of reliability, and not performance.
Reliability:
A single ZooKeeper server (standalone) is essentially a coordinator with no reliability (a single serving node failure brings down the ZK service).
A 3 server ensemble (you need to jump to 3 and not 2 because ZK works based on simple majority voting) allows for a single server to fail and the service will still be available.
So if you want reliability go with at least 3. We typically recommend having 5 servers in "online" production serving environments. This allows you to take 1 server out of service (say planned maintenance) and still be able to sustain an unexpected outage of one of the remaining servers w/o interruption of the service.
Performance:
Write performance actually decreases as you add ZK servers, while read performance increases modestly:http://zookeeper.apache.org/doc/current/zookeeperOver.html#Performance
See this page for a survey Patrick Hunt (http://twitter.com/phunt) did looking at operational latency with both standalone server and an ensemble of size 3. You'll notice that a single core machine running a standalone ZK ensemble (1 server) is still able to process 15k requests per second. This is orders of magnitude greater than what most applications require (if they are using ZooKeeper correctly - ie as a coordination service, and not as a replacement for a database, filestore, cache, etc...)
Can I run an ensemble cluster behind a load balancer?
There are two types of servers failures in distributed system from socket I/O perspective.
server down due to hardware failures and OS panic/hang, Zookeeper daemon hang, temporary/permanent network outage, network switch anomaly, etc: client cannot figure out failures immediately since there is no responding entities. As a result, zookeeper clients must rely on timeout to identify failures.
Dead zookeeper process (daemon): since OS will respond to closed TCP port, client will get "connection refused" upon socket connect or "peer reset" on socket I/O. Client immediately notice that the other end failed.
在每一种情况之下,zkCLinet 怎样去响应Server,在每一种情况。
Here's how ZK clients respond to servers in each case.
In this case (former), ZK client rely on heartbeat algorithm. ZK clients detects server failures in 2/3 of recv timeout (Zookeeper_init), and then it retries the same IP at every recv timeout period if only one of ensemble is given. If more than two ensemble IP are given, ZK clients will try next IP immediately.
In this scenario, ZK client will immediately detect failure, and will retry connecting every second assuming only one ensemble IP is given. If multiple ensemble IP is given (most installation falls into this category), ZK client retries next IP immediately.
Notice that in both cases, when more than one ensemble IP is specified, ZK clients retry next IP immediately with no delay.
On some installations, it is preferable to run an ensemble cluster behind a load balancer such as hardware L4 switch, TCP reverse proxy, or DNS round-robin because such setup allows users to simply use one hostname or IP (or VIP) for ensemble cluster, and some detects server failures as well.
But there are subtle differences on how these load balancers will react upon server failures.
Hardware L4 load balancer: this setup involves one IP and a hostname. L4 switch usually does heartbeat on its own, and thus removes non-responding host from its IP list. But this also relies on the same timeout scheme for fault detection. L4 may redirect you to a unresponsive server. If hardware LB detect server failures fast enough, this setup will always redirect you to live ensemble server.
DNS round robin: this setup involves one hostname and a list of IPs. ZK clients correctly make used of a list of IPs returned by DNS query. Thus this setup works the same way as multiple hostname (IP) argument to zookeeper_init. The drawback is that when an ensemble cluster configuration changes like server addition/removal, it may take a while to propagate the DNS entry change in all DNS servers and DNS client caching (nscd for example) TTL issue.
In conclusion, DNS RR works as good as a list of ensemble IP arguments except cluster reconfiguration case.
It turns out that there is a minor problem with DNS RR. If you are using a tool such as zktop.py, it does not take care of a list of host IP returned by a DNS server.
What happens to ZK sessions while the cluster is down?
每当 cluster 集群down掉以后,Zookeeper的Session是五的超时。
Imagine that a client is connected to ZK with a 5 second session timeout, and the administrator brings the entire ZK cluster down for an upgrade. The cluster is down for several minutes, and then is restarted.
在这一个章节,client能够重新连接并且刷新session,应为session 超时将会被领导所触发。
In this scenario, the client is able to reconnect and refresh its session. Because session timeouts are tracked by the leader, the session starts counting down again with a fresh timeout when the cluster is restarted. So, as long as the client connects within the first 5 seconds after a leader is elected,
it will reconnect without an expiration, and any ephemeral nodes it had prior to the downtime will be maintained.The same behavior is exhibited when the leader crashes and a new one is elected. In the limit, if the leader is flip-flopping back and forth quickly, sessions will never expire since their timers are getting constantly reset.