多备份创始人解析如何搞定TB级数据上云备份保护
大规模数据备份保护现状
从多备份目前10万多用户中发掘的大型客户看,业务规模稍微大一点,日志,DB归档,在线编辑,生产加工产生的数据,设计类文档,及日常运营的累积的数据等就轻松超过TB级。而对于TB级数据,有几种场景定义和区别:
单个节点的数据量上TB级
总量上TB级,但分布在多个节点
总量上TB,但单个文件量上百GB
总量上TB, 文件数规模很大,上万千,甚至过亿
总量上TB,类型不一样,有的是DB备份后的压缩文件,有的是图片,有的是文档类
TB级数据是用户产生,从用户中来,到用户中去,比如视频,图片等UGC内容,对于这类冷的数据,逐步也需要进行归档冷备起来
对 于目前以上6种情况,我们了解到,绝大部分企业,并没有做比较系统的保护,或者说做了系统的保护,但都是在本地环境做的,一旦遇到人为原因,软件缺陷,或 者存储故障等,数据丢失的风险相当大; 有相当能力的,自己做了异地或自己做云存储备份方案,但在灵活,系统化的,扩展性,成本方面并没有优势,毕竟对企业来说这不是核心运营的业务。
目前市面上的一些现有解决方案的特点:
策略一般就是全量+增量结合,选用专用的存储设备,接上高速的光纤通道,配上专用的系统维护人员,这类方案在本地有足够的优势,备份和恢复快,但缺点也是相当的明显,而且从设计理念上来看,以下的几个点基本只有厂家自己革命才能解决:
第1:复杂,配置、部署以及使用操作维护都需要专业的管理人员,基本上在互联网企业看,即使是做完B/C/D轮的,甚至IPO后的企业,出得起钱,也是不会考虑如此方案。
第2:升级扩展复杂,预先估计容量,后续扩展起来相当麻烦,必须的改变存储策略,或重新离线做数据迁移分布。如果初始购买的存储扩展有限,后期还不能很好的升级扩展。
第3:3-5年左右的生命周期,也就是说,数据经过几年后,改造升级,购买新的方案是必须的,这样当数据上到百TB级别,整个工程实施也是相当复杂了。
第4:难于对接互联网+的思路转换, 由于是离线的备份存储方案,如果和业务系统对接,实际上基本上就是不太可能,尤其是目前不少企业开始加强互联网+的运营思路的调整,数据不断会和外部系统进行交换或对接。
第5:贵,特别的贵,如果对原始TB级数据做专业备份保护,投入得数十万,具体到不同的行业,、性能和保护窗口参数稍微提升,投入立即上升到百万级。
当然如果对于非常有资源和有足够多的预算,这一切都看起来都不是问题;而事实上,这类用户还是只有在相当土豪的机构和企业里面才有,就连银行都无法彻底按照严谨的实施和维护方案落实,才会出现接二连三的银行机房烧毁数据丢失,或者宕机几十个小时的情况。
终归原因,对于关键的业务系统的备份保护,不紧紧是上了一套专业的方案,或者做了异地灾备,事情就可以完美解决;更重要的是,还得有操作简单,容易验证,应急性强的方案。
解决思路
多 备份从2013年成立以来,一直以互联网的简单、亲民的服务化思路演化,目前服务过的客户,包括GB级的到TB级,涉及到关键运营业务系统数据库,也包含 企业日常运营产生的文档资料存储备份保护等。经过上PB级的数据训练,多备份从第1代全云的架构方案,到目前迭代的到最新的第2代基于混合云架构的保护方 案。
第2代方案设计的目标主要面向TB级数据保护需求,彻底切分TB级数据6个构成面,并主要分解为如下几个点:
最大化降低备份存储空间,数倍降低企业TCO投入
简化使用门槛,包括配置流程,以及保护策略
数据备份和恢复的速度要在基于云的架构下,足够的快
按需在线扩展,永不停机,足够可靠
支持数据按需流动,真正意义让数据在必要的时候,能动起来
仅由客户全程加密掌控数据,充分保护数据隐私
基于以上6个设计目标,我们从几个方面来剖析多备份是如何做到的
以云为核心,外网IT存储设施混合的本地+云的混合设计模型
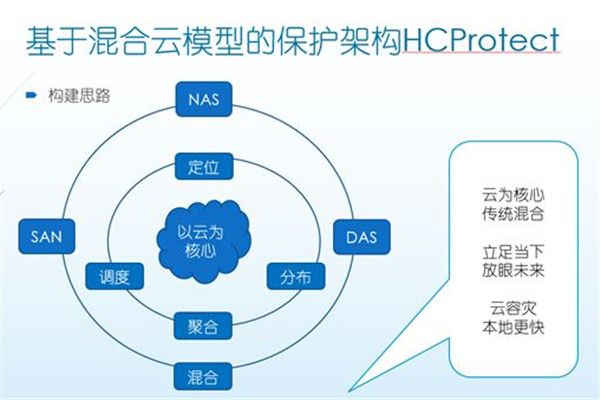
首先,多备份整体架构,围绕云来设计,充分利用云的几个特点
按需扩展,对客户,对多备份自身服务的投入按需增加
可靠,云的计算和存储分布特点,使得系统在计算和存储都具备传统结构不具备的数倍的可靠性
安全,基础云服务商自身在安全方面不计成本,比起自己构建IT设施,来得更加专业
扩展,开放性更好,使得构建的服务,更容易外部系统对接
目前在具体的基础实施平台中,重点包括阿里云,腾讯云,AWS,金山云,微软AZURE,移动云,七牛,百度云等平台,这些都是全球或国内知名的大型云平台。
其次,为了更好融合企业IT场景,以及一些合规规定,多备份在第1代云的基础上,增加了外围对接,支持数据备份存储在本地环境的存储设施,如NAS, SAN 或者节点的另外的磁盘分区等,这样一来有3个好处:
数据可以在本地存储一份,特别是热一点的数据, 其他数据可以部分或者全部上云进行备份保护起来
常规的备份和恢复任务的会第1时间在本地环境完成,数据会在本地完成后,最快的时间同步上云
一些政企合规的数据可以保存在内部,其他的非敏感类的数据可以加密上云。
数据发现,传输,存储等全部采用全增量+时间点版本映射结构设计
具备时间刻度特性的,本地和云两级全增量索引
为了实现更低的存储开销,更快的备份和恢复速度,多备份从索引的设计,数据版本组织策略上都采用全增量模型,并且支持任意时间点的版本和索引的映射,这样就为任一时间点的数据恢复或下载等提供了可行支持。
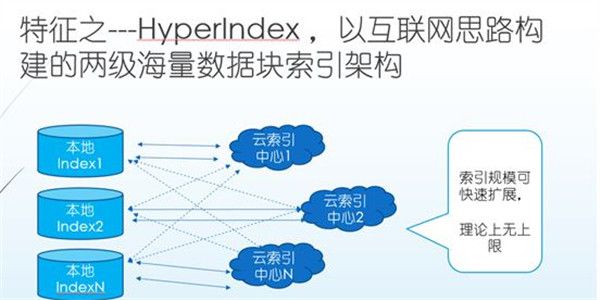
索 引是构成整个系统的关键,数据的变化,无论从本地往云,还是从云往本地,都以来索引来快速找到对应的数据块。而传统的方案里面,索引也存在。多备份的特点 在于,结合了云以后,索引全部采用分区分段构建云索引中心的扩展模型,在量级,动态迁移是传统的方案无法比较的。理论上,客户越多,数据越大,边际效应就 越好,给客户回馈的成本优势就更越明显。
在这里,本地的索引用来快速支持数据的变化检查,云端的索引用于本地失效后的变化检测,以及在线数据服务接口的支持。
在每一次的数据备份时刻,都会记录相应的数据映射关系,这样可以满足任意时间点的数据恢复和使用检索需求。
按 照目前的设计,在本地可以支持2TB的数据索引关系,支持的数据量可以到达PB级,文档(含数据库备份压缩备份归档数据文件)数量可以到达十亿级别规模。 而在云上集中的存储规模理论上受限于云平台本身的存储容量,幸运的是,即使在这一刻,多备份也可以正常运行,原因在于,多备份底层已经支持多个云的分布或 聚合。
本地+云两级全增量策略保护模型,更快,更省的本性
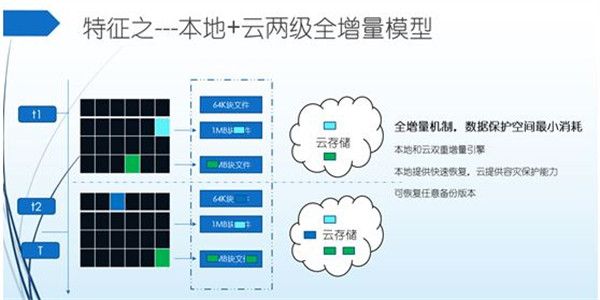
多备份在数据策略化组织这里全部采用增量模型,与传统的定期全量+增量模型在存储空间和效率方面有着显著的区别。一般原始数据在500GB规模的,按照通常的服务沟通模型下来,3个月下来也得有10TB级规模了,如果采用传统的方案,成本将到达百万级投入规模。
多备份依托于云存储的冗余分布特性,在时间和空间分布的可靠性方面已经远远大于本地存储。正因为如此,多备份的增量备份存储策略机制在保持最小的数据开销规模下,每次的备份效率都出奇的高,同样,按照时间点任意恢复数据的时候速度也相当快。
同样,由于其边扫描边备份,实时增量检测,块级存储的增量特性,以及压缩策略智能化,单个几百GB规模的文件,文本和图片视频,还是在数量众多的千万级规模下都可以胜任。
基于云的两级增量模型最大的好处就是在TB级数据规模下,具备超低投入,甚至低至传统方案的1/10 TCO,高速度;同样,具备时间刻度恢复的特点、
端到端AES256加密机制,与Cloud 5分块算术冗余分布机制,让数据足够的安全与可靠

在多备份的整个体系设计中,安全是从端到后台,整体设计全程考虑,不打折扣,严格从机制上保证数据上云的机密性。
数 据从客户端接入数据后,立即进行AES256加密,加密后的数据分布在云存储中,而加密用的密钥则是在安装过程中,由客户端产生并有客户自己保存下来。对 于特别要求可靠的数据,Cloud 5技术可以在保持2倍的成本投入下,进一步在多个不同种类的云存储,或者单个云的多个存储中心之间提高备份数据可靠性,几乎就是永不丢失。
围绕80%的场景设计, 安装设置与维护尽可能快和简单
多 备份在具体的部署方案上,分成控制中心和客户端设计,当然还有无安装模型。目前无论是控制中心,还是客户端都采用80/20场景适应的原则来考虑,在具体 使用流程和参数布局上,全面改变传统的几百个令人发晕的参数配置方案。所有的标准化操作考虑80%的场景覆盖,除了频率,内容设置,速度限制,必要的链接 参数外,其他都不在多备份主流程中。这样在具体的功能组合,流程模板显示,操作菜单,以及按钮都可以保持非常简单的流程和交互设计。
作者介绍:
联 合创始人& CTO - 陈元强 曾就职于宝德、腾讯、盛大(旅游)、宜搜、4399,历任经理、总监等核心研发岗位。主导过国家级IT安全系统研发和实施;负责家庭战略项目的产品研发管 理工作,主导QQ空间大数据分析和腾讯网分布式流量分析平台的研发。在海量用户、数据安全、网络通讯和大数据挖掘等应用领域方面具有丰富的经验。