Mysql中load data infile的使用
LOAD DATA INFILE语法
典型的示例:
如果指定了LOCAL,则文件会被客户主机上的客户端读取,并被发送到服务器。文件会被给予一个完整的路径名称,以指定确切的位置。如果给定的是一个相对的路径名称,则此名称会被理解为相对于启动客户端时所在的目录。
如果LOCAL没有被指定,则文件必须位于服务器主机上,并且被服务器直接读取。
当在服务器主机上为文件定位时,服务器使用以下规则:
如果给定了一个绝对的路径名称,则服务器使用此路径名称。
如果给定了带有一个或多个引导组件的相对路径名称,则服务器会搜索相对于服务器数据目录的文件。
如果给定了一个不带引导组件的文件名称,则服务器会在默认数据库的数据库目录中寻找文件。
注意,这些规则意味着名为./myfile.txt的文件会从服务器数据目录中被读取,而名为myfile.txt的同样的文件会从默认数据库的数据库目录中读取。
从客户端使用绝对路径load数据
您可以使用IGNORE 1 LINES来跳过一个包含列名称的起始标题行:
如果您指定了REPLACE,则输入行会替换原有行(换句话说,与原有行一样,对一个主索引或唯一索引具有相同值的行)。
如果您指定IGNORE,则把原有行复制到唯一关键字值的输入行被跳过。
如果您这两个选项都不指定,则运行情况根据LOCAL关键词是否被指定而定。不使用LOCAL时,当出现重复关键字值时,会发生错误,并且剩下的文本文件被忽略。使用LOCAL时,默认的运行情况和IGNORE被指定时的情况相同;这是因为在运行中间,服务器没有办法中止文件的传输。
索引的影响
如果您对一个空的MyISAM表使用LOAD DATA INFILE,则所有的非唯一索引会被创建在一个独立批中(对于REPAIR TABLE)。当您有许多索引时,这通常会使LOAD DATA INFILE大大加快。通常,LOAD DATA INFILE的速度会非常快,但是在某些极端情况下,您可以在把文件载入到表中之前使用ALTER TABLE...DISABLE KEYS关闭LOAD DATA INFILE,或者在载入文件之后使用ALTER TABLE...ENABLE KEYS再次创建索引,使创建索引的速度更快。
FIELDS和LINES的默认值
如果您不指定FIELDS子句,则默认值为假设您写下如下语句时的值:
FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\'
如果您不指定LINES子句,则默认值为假设您写下如下语句时的值:
LINES TERMINATED BY '\n' STARTING BY ''
换句话说,当读取输入值时,默认值会使LOAD DATA INFILE按如下方式运行:
在新行处寻找行的边界。
不会跳过任何行前缀。
在制表符处把行分解为字段。
不希望字段被包含在任何引号字符之中。
出现制表符、新行、或在‘\’前有‘\’时,理解为作为字段值一部分的文字字符。
相反的,当编写输出值时,默认值会使SELECT...INTO OUTFILE按如下方式运行:
在字段之间写入制表符。
不把字段包含在任何引号字符中。
当字段值中出现制表符、新行或‘\’时,使用‘\’进行转义。
在行的末端写入新行。
注意,要写入FIELDS ESCAPED BY ‘\\’,您必须为待读取的值指定两个反斜杠,作为一个单反斜杠使用。
备注:如果您已经在Windows系统中生成了文本文件,您可能必须使用LINES TERMINATED BY ‘\r\n’来正确地读取文件,因为Windows程序通常使用两个字符作为一个行终止符。部分程序,当编写文件时,可能会使用\r作为行终止符。要读取这样的文件,应使用LINES TERMINATED BY ‘\r’。
STARTING LINES选项
如果所有您希望读入的行都含有一个您希望忽略的共用前缀,则您可以使用'prefix_string'来跳过前缀(和前缀前的字符)。如果某行不包括前缀,则整个行被跳过。注释:prefix_string会出现在一行的中间。
以下面的test.txt为文件源
xxx"row",1
something xxx"row",2
使用以下sql导入数据
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test LINES STARTING BY "xxx";
最后并只得到数据("row",1)和("row",2)。
TERMINATED LINES选项
如果jokes被由%%组成的行分隔,要读取包含jokes的文件,您可以这么操作:
LOAD DATA INFILE '/tmp/jokes.txt' INTO TABLE jokes FIELDS TERMINATED BY '' LINES TERMINATED BY '\n%%\n' (joke);
TERMINATED,ENCLOSED,ESCAPED FIELD选项
TERMINATED用于控制字段的分隔符,可以为多个字符。
ENCLOSED BY用于用于控制字段的引号,必须为单一字符,如果您忽略了词语OPTIONALLY,则所有的字段都被包含在ENCLOSED BY字符串中,如果您指定了OPTINALLY,则ENCLOSED BY字符只被用于包含具有字符串数据类型(比如CHAR, BINARY, TEXT或ENUM)的列中的值.
SELECT...INTO OUTFILE导出数据,ENCLOSED BY '"',忽略OPTIONALLY
"1","a string","100.20"
SELECT...INTO OUTFILE导出数据,ENCLOSED BY '"',指定OPTIONALLY
1,"a string",100.20
ESCAPED BY用于转义,FIELDS ESCAPED BY值必须为单一字符。
如果FIELDS ESCAPED BY字符为空字符,则没有字符被转义,并且NULL被作为NULL输出,而不是\N。去指定一个空的转义符不是一个好办法,特别是如果数据的字段值包含任何刚给定的清单中的字符时,更不能这么做。
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt' [REPLACE | IGNORE] INTO TABLE tbl_name [FIELDS [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char' ] ] [LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ] [IGNORE number LINES] [(col_name_or_user_var,...)] [SET col_name = expr,...)]
LOAD DATA INFILE语句用于高速地从一个文本文件中读取行,并装入一个表中。文件名称必须为一个文字字符串。
典型的示例:
LOAD DATA LOCAL INFILE 'data.txt' INTO TABLE tbl_name FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n'
如果只想载入一个表的部分列,则应指定一个列清单:
LOAD DATA LOCAL INFILE 'persondata.txt' INTO TABLE persondata (col1,col2);
文件的路径
如果指定了LOCAL,则被认为与连接的客户端有关:如果指定了LOCAL,则文件会被客户主机上的客户端读取,并被发送到服务器。文件会被给予一个完整的路径名称,以指定确切的位置。如果给定的是一个相对的路径名称,则此名称会被理解为相对于启动客户端时所在的目录。
如果LOCAL没有被指定,则文件必须位于服务器主机上,并且被服务器直接读取。
当在服务器主机上为文件定位时,服务器使用以下规则:
如果给定了一个绝对的路径名称,则服务器使用此路径名称。
如果给定了带有一个或多个引导组件的相对路径名称,则服务器会搜索相对于服务器数据目录的文件。
如果给定了一个不带引导组件的文件名称,则服务器会在默认数据库的数据库目录中寻找文件。
注意,这些规则意味着名为./myfile.txt的文件会从服务器数据目录中被读取,而名为myfile.txt的同样的文件会从默认数据库的数据库目录中读取。
从客户端使用绝对路径load数据
LOAD DATA LOCAL INFILE '/import/data.txt' INTO TABLE db2.my_table;
从服务器里使用相对路径load数据
下面的LOAD DATA语句会从db1数据库目录中读取文件data.txt,因为db1是当前数据库。即使语句明确把文件载入到db2数据库中的表里,也会从db1目录中读取。USE db1; LOAD DATA INFILE 'data.txt' INTO TABLE db2.my_table;
IGNORE number LINES选项
IGNORE number LINES选项可以被用于在文件的开始处忽略行。您可以使用IGNORE 1 LINES来跳过一个包含列名称的起始标题行:
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test IGNORE 1 LINES;
REPLACE和IGNORE
有些输入记录把原有的记录复制到唯一关键字值上。REPLACE和IGNORE关键字用于控制这些输入记录的操作。如果您指定了REPLACE,则输入行会替换原有行(换句话说,与原有行一样,对一个主索引或唯一索引具有相同值的行)。
如果您指定IGNORE,则把原有行复制到唯一关键字值的输入行被跳过。
如果您这两个选项都不指定,则运行情况根据LOCAL关键词是否被指定而定。不使用LOCAL时,当出现重复关键字值时,会发生错误,并且剩下的文本文件被忽略。使用LOCAL时,默认的运行情况和IGNORE被指定时的情况相同;这是因为在运行中间,服务器没有办法中止文件的传输。
索引的影响
如果您对一个空的MyISAM表使用LOAD DATA INFILE,则所有的非唯一索引会被创建在一个独立批中(对于REPAIR TABLE)。当您有许多索引时,这通常会使LOAD DATA INFILE大大加快。通常,LOAD DATA INFILE的速度会非常快,但是在某些极端情况下,您可以在把文件载入到表中之前使用ALTER TABLE...DISABLE KEYS关闭LOAD DATA INFILE,或者在载入文件之后使用ALTER TABLE...ENABLE KEYS再次创建索引,使创建索引的速度更快。
FIELDS和LINES的默认值
如果您不指定FIELDS子句,则默认值为假设您写下如下语句时的值:
FIELDS TERMINATED BY '\t' ENCLOSED BY '' ESCAPED BY '\\'
如果您不指定LINES子句,则默认值为假设您写下如下语句时的值:
LINES TERMINATED BY '\n' STARTING BY ''
换句话说,当读取输入值时,默认值会使LOAD DATA INFILE按如下方式运行:
在新行处寻找行的边界。
不会跳过任何行前缀。
在制表符处把行分解为字段。
不希望字段被包含在任何引号字符之中。
出现制表符、新行、或在‘\’前有‘\’时,理解为作为字段值一部分的文字字符。
相反的,当编写输出值时,默认值会使SELECT...INTO OUTFILE按如下方式运行:
在字段之间写入制表符。
不把字段包含在任何引号字符中。
当字段值中出现制表符、新行或‘\’时,使用‘\’进行转义。
在行的末端写入新行。
注意,要写入FIELDS ESCAPED BY ‘\\’,您必须为待读取的值指定两个反斜杠,作为一个单反斜杠使用。
备注:如果您已经在Windows系统中生成了文本文件,您可能必须使用LINES TERMINATED BY ‘\r\n’来正确地读取文件,因为Windows程序通常使用两个字符作为一个行终止符。部分程序,当编写文件时,可能会使用\r作为行终止符。要读取这样的文件,应使用LINES TERMINATED BY ‘\r’。
STARTING LINES选项
如果所有您希望读入的行都含有一个您希望忽略的共用前缀,则您可以使用'prefix_string'来跳过前缀(和前缀前的字符)。如果某行不包括前缀,则整个行被跳过。注释:prefix_string会出现在一行的中间。
以下面的test.txt为文件源
xxx"row",1
something xxx"row",2
使用以下sql导入数据
LOAD DATA INFILE '/tmp/test.txt' INTO TABLE test LINES STARTING BY "xxx";
最后并只得到数据("row",1)和("row",2)。
TERMINATED LINES选项
如果jokes被由%%组成的行分隔,要读取包含jokes的文件,您可以这么操作:
LOAD DATA INFILE '/tmp/jokes.txt' INTO TABLE jokes FIELDS TERMINATED BY '' LINES TERMINATED BY '\n%%\n' (joke);
TERMINATED,ENCLOSED,ESCAPED FIELD选项
TERMINATED用于控制字段的分隔符,可以为多个字符。
ENCLOSED BY用于用于控制字段的引号,必须为单一字符,如果您忽略了词语OPTIONALLY,则所有的字段都被包含在ENCLOSED BY字符串中,如果您指定了OPTINALLY,则ENCLOSED BY字符只被用于包含具有字符串数据类型(比如CHAR, BINARY, TEXT或ENUM)的列中的值.
SELECT...INTO OUTFILE导出数据,ENCLOSED BY '"',忽略OPTIONALLY
"1","a string","100.20"
SELECT...INTO OUTFILE导出数据,ENCLOSED BY '"',指定OPTIONALLY
1,"a string",100.20
ESCAPED BY用于转义,FIELDS ESCAPED BY值必须为单一字符。
如果FIELDS ESCAPED BY字符为空字符,则没有字符被转义,并且NULL被作为NULL输出,而不是\N。去指定一个空的转义符不是一个好办法,特别是如果数据的字段值包含任何刚给定的清单中的字符时,更不能这么做。
如果在字段值内出现ENCLOSED BY字符,则通过使用ESCAPED BY字符作为前缀,对ENCLOSED BY字符进行转义。
另附:MySQL5 LOAD DATA 深入研究
MySQL5 LOAD DATA 深入研究
数据库中,最常见的写入数据方式是通过SQL INSERT来写入,另外就是通过备份文件恢复数据库,这种备份文件在MySQL中是SQL脚本,实际上执行的还是在批量INSERT语句。
在实际中,常常会遇到两类问题:一类是数据导入,比如从word、excel表格或者txt文档导入数据(这些数据一般来自于非技术人员通过OFFICE工具录入的文档);一类数据交换,比如从MySQL、Oracle、DB2数据库之间的数据交换。
这其中就面临一个问题:数据库SQL脚本有差异,SQL交换比较麻烦。但是几乎所有的数据库都支持文本数据导入(LOAD)导出(EXPORT)功能。利用这一点,就可以解决上面所提到的数据交换和导入问题。
MySQL的LOAD DATA INFILE语句用于高速地从一个文本文件中读取行,并装入一个表中。文件名称必须为一个文字字符串。下面以MySQL5为例说明,说明如何使用MySQL的LOAD DATA命令实现文本数据的导入。
注意:这里所说的文本是有一定格式的文本,比如说,文本分行,每行中用相同的符号隔开文本等等。等等,获取这样的文本方法也非常的多,比如可以把word、excel表格保存成文本。
一、测试环境:
Windows XP Professional 简体中文版
mysql-5.0.45-win32
注意:不要以为测试环境写操作系统是多余的,我想说一点:不同操作系统的回车换行不大一样,会得出不同的结果。
二、准备数据库、目标表、测试数据。
1、准备测试数据
数据的来源是: [url]http://www.cstj.gov.cn/upload/newstxt/dmfl.htm[/url],这个是“国民经济行业分类与代码表”,网页格式。我们现在需要的是文本数据,如何获取符合格式的文本数据呢?方法是,复制网页到excel,删除前面无用的三列,另存为文本文档C:\DM_HY.TXT;
2、创建目标数据库、目标表
-- 创建目标数据库
CREATE DATABASE IF NOT EXISTS TESTDB;
-- 设置当前数据库
USE TESTDB;
-- 预防性删除要创建的目标表
DROP TABLE IF EXISTS DM_HY;
-- 创建目标表
CREATE TABLE DM_HY (
ID BIGINT(20) NOT
NULL AUTO_INCREMENT,
ML VARCHAR(1) DEFAULT NULL,
DL VARCHAR(2) DEFAULT NULL,
ZL VARCHAR(3) DEFAULT NULL,
XL VARCHAR(4) DEFAULT NULL,
MC VARCHAR(120) DEFAULT NULL,
SM VARCHAR(1200) DEFAULT NULL,
PRIMARY KEY (ID)
) ENGINE=MYISAM DEFAULT CHARSET=GBK;
说明:
AUTO_INCREMENT 主键自增
DEFAULT CHARSET=GBK 设定表的默认字符集
三、LOAD数据
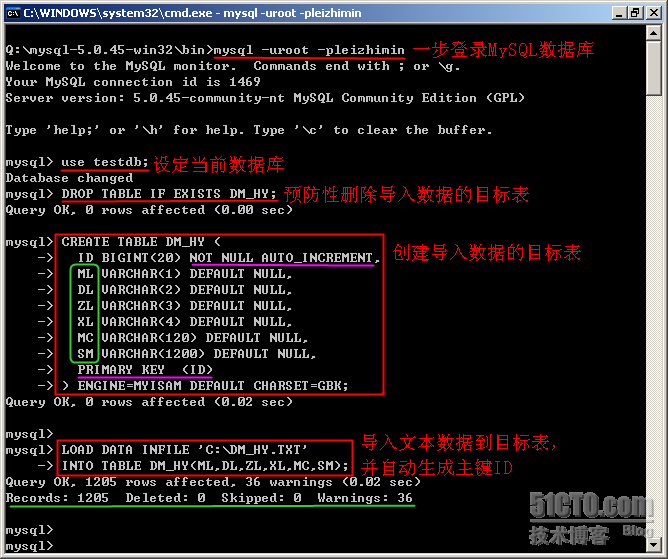
一步登录数据库,并且设置当前数据库:
mysql -uroot -pleizhimin
use testdb;
-- 从文本文件导入数据到目标表
LOAD DATA INFILE 'C:\DM_HY.TXT'
INTO TABLE DM_HY(ML,DL,ZL,XL,MC,SM);
这样即可完成数据的导入。
控制台截图如下:
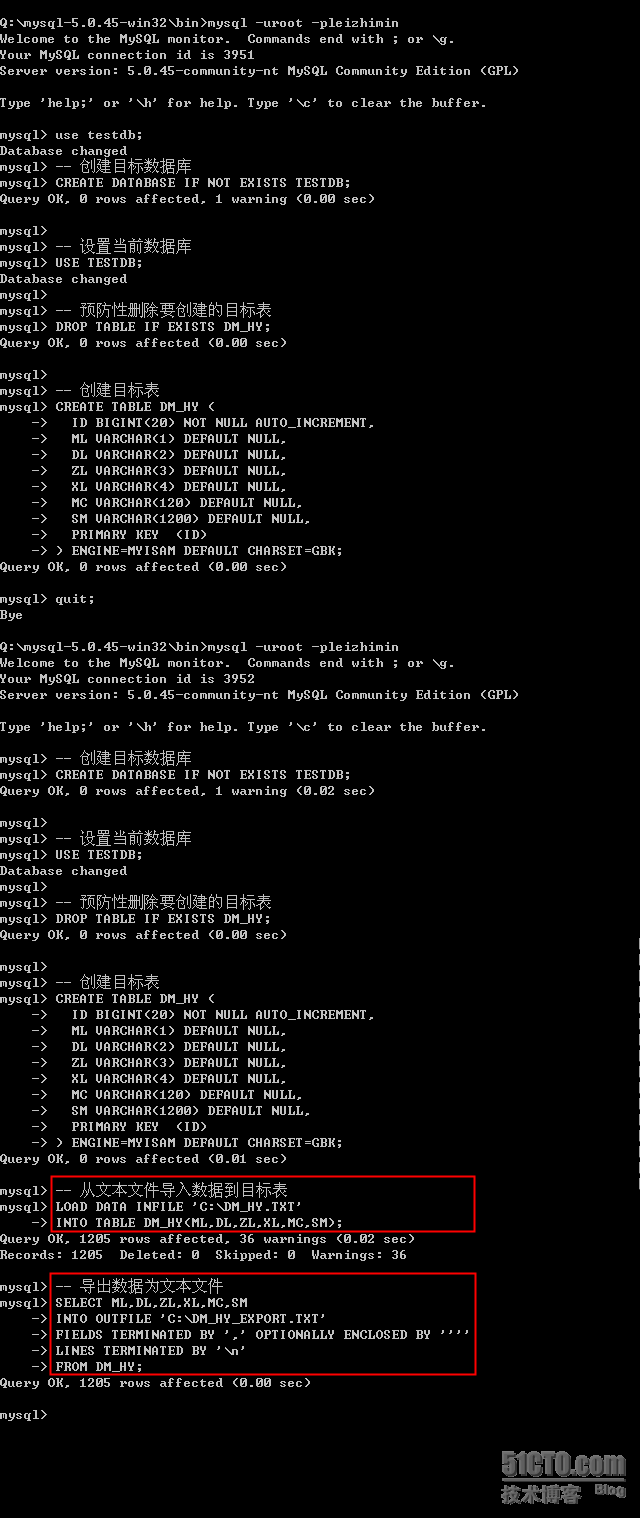
四、EXPORT数据
如果我现在要将MySQL中的DM_HY这个表导入到DB2,我还需要导出一个文本文件,然后再利用DB2的LOAD导入到DB2数据库。还以DM_HY表为例,将上面导入的数据重新导出到C:\DM_HY_EXPORT.TXT.
实际上,在MySQL5中不存在真正的EXPORT命令,而是
SELECT ... INTO OUTFILE 命令。下面是操作过程:
-- 导出数据为文本文件
SELECT ML,DL,ZL,XL,MC,SM
INTO OUTFILE 'C:\DM_HY_EXPORT.TXT'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY ''''
LINES TERMINATED BY '\n'
FROM DM_HY;
FIELDS TERMINATED BY ',' 数据字段间用逗号隔开
OPTIONALLY ENCLOSED BY '''' 每个字段的数据用单引号括住(注意单引号的表达方法)
LINES TERMINATED BY '\n' 每条数据结束用'\n'作为换行符。
执行过程的截图如下:
注意:如果导出数据的时候指定分隔符、换行符,那么在导入的时候也要指定。
五、总结
LOAD DATA是一个很有用的命令,而且命令的选项很多,但大多都用不到,如果真的需要,用的时候看看官方文档即可。下面我给出MySQL的官方的语法以供参考:
LOAD DATA INFILE语法
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[FIELDS
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char' ]
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number LINES]
[(col_name_or_user_var,...)]
[SET col_name = expr,...)]
SELECT语法
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr, ...
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name']
[FROM table_references
[WHERE where_definition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_definition]
[ORDER BY {col_name | expr | position}
[ASC | DESC] , ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[FOR UPDATE | LOCK IN SHARE MODE]]