Spark Streaming初探
了解Spark Streaming之前,建议先了解Spark,入门博文Spark初探
定义
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams(官网定义). Spark Streaming是核心的Spark API的一个扩展,是可伸缩、高吞吐量、容错的实时数据流的流处理框架。处理的数据源可以来自Kafka, Flume, Twitter, ZeroMQ, Kinesis or TCP sockets。可以通过调用map, reduce, join和window等API函数来处理数据,也可以使用机器学习、图算法来处理数据。最终结果可以保存在文件系统、数据库或者实时Dashboard展示。如下图:

Spark Streaming接收实时数据并将其拆分成多个小的批处理作业(batches),然后通过Spark引擎来处理它们,批量生成最终的结果。
DStream
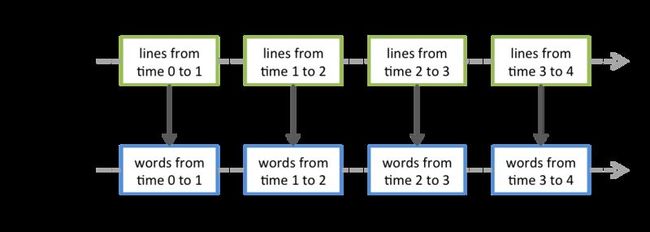
Spark Stream提供了一个高层次的抽象叫做离散流(discretized stream)或者DStream,代表了持续的数据流。DStream可以通过输入数据源(Kafka, Flume, Twitter等)传输的数据创建,也可以通过其他DStream的高级操作生成。在内部,DStream代表着一系列的持续的RDDs。DStream中的每个RDD都是一小段时间(interval)分割开来的数据集,如下图:

对DStream的任何操作都会转化成对底层RDDs的操作。如下图对lines DStream做flatMap操作,实际上就是对它内部的所有RDD做flatMap操作。
简单例子
首先我们先写一个服务器端程序,当与该服务器端程序建立连接后,程序每秒发送1一个字符串(注意以"\n"结尾)。可以使用Java或者Scala、或者其他语言实现都可以,相信也不难。这里笔者使用netty实现了一个。我们只看一下Handler部分:
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// Send greeting for a new connection.
while (true) {
Thread.sleep(1000);
ctx.write(generateString());
ctx.flush();
}
}
private String generateString() {
String[] nameList = {"Jackson", "James", "Maynard", "Harland", "Tanner"};
int index = (int)Math.rint(Math.random()*4);
System.out.println(nameList[index]);
return nameList[index] + '\n';
}
程序很简单,就是建立连接后,每秒随机发送五个名字中的一个名字。我已经使用Maven将程序包,点此下载MessageCreator-0.0.1-SNAPSHOT.jar。运行jar包:
java -jar MessageCreator-0.0.1-SNAPSHOT.jar 9999
其中9999为端口号,可以用telnet localhost 9999来验证server是否启动成功。(以上不是重点,我们重点还是Spark Streaming)
我们接下来要做的就是使用Spark Streaming,统计一段时间内(interval)每个名字出现的次数。使用Spark Streaming需要首先建立StreamingContext,使用socketTextStream接收来自TCP Socket的数据,之后就是指定相应的运算,最后通过streamingContext.start()来开始接收数据并处理。代码如下:
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: NetworkWordCount <master> <hostname> <port> <seconds>\n" +
"In local mode, <master> should be 'local[n]' with n > 1")
System.exit(1)
}
// 新建StreamingContext
val conf = new SparkConf().setAppName("NetworkWordCount").setMaster(args(0))
val ssc = new StreamingContext(conf, Seconds(args(3).toInt))
// 按行读取socket数据源发送的数据,序列化保存在内存中
val lines = ssc.socketTextStream(args(1), args(2).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) // word count
// 在控制台打印结果(只打印DStream中每个RDD的前十个)
wordCounts.print()
ssc.start() // 开始计算
ssc.awaitTermination() // 等待计算结束
}
程序启动需要四个参数master(集群的master结点),hostname(发送socket数据的主机名),port(发送socket数据程序的端口号), seconds(多长时间处理一次,也就是interval)。这里有flatMap,map,reduceByKey三个算子,与它们在Spark中的语义完全一致。
数据源
Basic Sources
1) TCP Socket数据源:streamingContext.socketTextStream(...)
2) 文件流:streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
会建立一个input stream来监控相应的目录,要求数据具有相同的InputFormatClass,文件必须是通过从同一个文件系统中移动到被监控目录中。文件移动之后,被追加的数据将不会被处理。如果是简单的文本文件,可以使用streamingContext.textFileStream(dataDirectory)方法。为了便于理解,我们看一下textFileStream方法的源码:
def textFileStream(directory: String): DStream[String] = {
fileStream[LongWritable, Text, TextInputFormat](directory).map(_._2.toString)
}
3) Streams based on Custom Actors: 通过Akka actor接收来的数据流创建DStream。
streamingContext.actorStream(actorProps, actor-name)
4) 通过RDD队列来创建DStream:streamingContext.queueStream(queueOfRDDs)
Advanced Sources
通过外部的一些包提供的接口作为数据源,例如:Twitter,Flume,Kafka,Kinesis等。
Transformation
1. 与Spark中语义一致的Transformation
Map, flatMap, filer, union, count, reduce, groupByKey, reduceByKey, join等,语义跟Spark完全一致,只不过有一些在Spark中是Action类型。
2. 更新状态的操作updateStateByKey
Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key.
updateStateByKey 针对key使用func来更新状态和值,允许使用者持续维护任何状态信息,使用它需要做以下两步:定义状态——该状态可以是任意的类型;定义更新状态的函数——指定一个根据以前的状态还输入流的值来更新状态的函数。
3. Transform操作
与它的变种transformWith一样,可以对DStream做任意的RDD-to-RDD操作。它可以应用任意RDD操作,但是该操作在Dstream的API没有直接暴露出来。比如我们要对DStream中的所有RDD去join另外一个RDD。在实际应用中,我们也在transform方法里使用机器学习和图形计算算法。
// RDD containing spam information
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...)
val cleanedDStream = wordCounts.transform(rdd => {
// join data stream with spam information to do data cleaning
rdd.join(spamInfoRDD).filter(...)
...
})
4. window操作
Spark Streaming 也提供了窗口计算,允许我们对滑动窗口数据使用transformations。
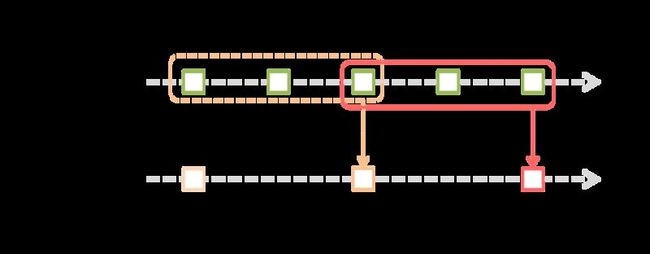
如图所示,每两个单位的时间(例如20s),来计算前三个单位时间(例如30s)的数据。这里有两个参数:
Window length – 窗口时间的长度(要计算从当前时间向前多少时间,例如计算前30秒)
slice interval:计算的时间间隔(每隔多长时间计算一次,例如每隔20秒)
// 每20秒,对过去30秒的数据做reduce操作 val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(20))
其它方法还有:
window(windowLength, slideInterval)
countByWindow(windowLength, slideInterval)
reduceByWindow(func, windowLength, slideInterval)
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) countByValueAndWindow(windowLength, slideInterval, [numTasks])
Output Operation
用户通过Output operation将DStream中的数据输出到外部系统中(例如database或者文件系统),它们真正触发并执行了Transformations(就像RDD中的Action)。
print()
Prints first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging.
在控制台中打印DStream中每个RDD的前10条记录。
saveAsTextFiles(prefix, [suffix])
Save this DStream's contents as a text files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
保存流的内容为文本文件, 每个时间段内批处理生成的文件名 : "prefix-TIME_IN_MS[.suffix]".
saveAsObjectFiles(prefix, [suffix])
Save this DStream's contents as a SequenceFile of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
保存流的内容为SequenceFile, 文件名 : "prefix-TIME_IN_MS[.suffix]".
saveAsHadoopFiles(prefix, [suffix])
Save this DStream's contents as a SequenceFile of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]".
保存流的内容为hadoop文件, 文件名 : "prefix-TIME_IN_MS[.suffix]".
foreachRDD(func)
The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to a external system, like saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs.
对Dstream里面的每个RDD执行func,保存到外部系统。例如:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
友情提示:
本文基础篇:《Spark初探》