搭建hadoop/spark集群环境
hadoop2.5.2的安装可以参照
http://blog.csdn.net/greensurfer/article/details/39450369
jdk下载地址
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
hadoop下载地址
http://mirrors.cnnic.cn/apache/hadoop/common/
这篇文章中没有说配置环境的事,我在这里简单说一下,为了能使虚机启动后环境变量就直接可用,我将jdk和hadoop直接配置到~/.bashrc文件中
# set java environment export JAVA_HOME=/usr/lib/java/jdk1.7.0_71 export SCALA_HOME=/usr/lib/scala/scala-2.11.4 export SPARK_HOME=/usr/local/spark/spark-1.2.0-bin-hadoop2.4 export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:/usr/local/hadoop/hadoop-2.5.2/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
配置完成后,使用source使命令生效
除此之外,在进行配制前要前将本地的hostname和hosts进行修改
vim /etc/profile vim /etc/hosts
对于hostname主节点修改为master,分支节点修改为slave1/slave2/salve3.........
对于hosts里面要添加主从节点的host
master 192.168.1.3 slave1 192.168.1.10 slave2 192.168.1.20
我主要说一下spark集群的安装
先去scala和spark的官网下载scala-2.11.4.tgz、spark-1.2.0-bin-hadoop2.4.tgz
安装scala
创建目录
mkdir /usr/lib/scala
在新建的目录中解压scala
tar zxvf scala-2.11.4.tgz
将scala添加到环境变量中
vim ~/.bashrc
在文件最下面添加
export SCALA_HOME=/usr/lib/scala/scala-2.11.4 export PATH=$PATH:$SCALA_HOME/bin
保存退出后,用source使命令生效
source ~/.bashrc
查看scala是否安装成功
[root@master scala]# scala -version Scala code runner version 2.11.4 -- Copyright 2002-2013, LAMP/EPFL
这样在master上就完成了scala的安装,由于spark要运行在master、slave1、slave2三个虚机上,所以我们可以用scp命令将~/.bashrc从master拷贝到slave机器上
安装spark
创建目录
mkdir /usr/local/spark
将已下载的spark-1.2.0-bin-hadoop2.4.tgz解压到此目录中
tar zxvf spark-1.2.0-bin-hadoop2.4.tgz
设置环境变量
vim ~/.bashrc
在文件中添加一行
export SPARK_HOME=/usr/local/spark/spark-1.2.0-bin-hadoop2.4
修改文件的PATH为
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin
如果要把jdk和hadoop也一起加入的话,那最后结果为
# set java environment export JAVA_HOME=/usr/lib/java/jdk1.7.0_71 export SCALA_HOME=/usr/lib/scala/scala-2.11.4 export SPARK_HOME=/usr/local/spark/spark-1.2.0-bin-hadoop2.4 export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:/usr/local/hadoop/hadoop-2.5.2/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
使用source使命令生效
source ~/.bashrc
配制spark,进入到spark的conf目录
[root@master scala]# cd /usr/local/spark/spark-1.2.0-bin-hadoop2.4/conf
使用cp命令复制一份spark-env.sh
cp spark-env.sh.template spark-env.sh
修改此文件,在文件末尾添加
###jdk安装目录 export JAVA_HOME=/usr/lib/java/jdk1.7.0_71 ###scala安装目录 export SCALA_HOME=/usr/lib/scala/scala-2.11.4 ###spark集群的master节点的ip export SPARK_MASTER_IP=192.168.1.3 ###指定的worker节点能够最大分配给Excutors的内存大小 export SPARK_WORKER_MEMORY=1g ###hadoop集群的配置文件目录 export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.5.2/etc/hadoop
修改conf目录下面的slaves文件将worker节点都加进去
[root@master conf]# cat slaves # A Spark Worker will be started on each of the machines listed below. master slave1 slave2
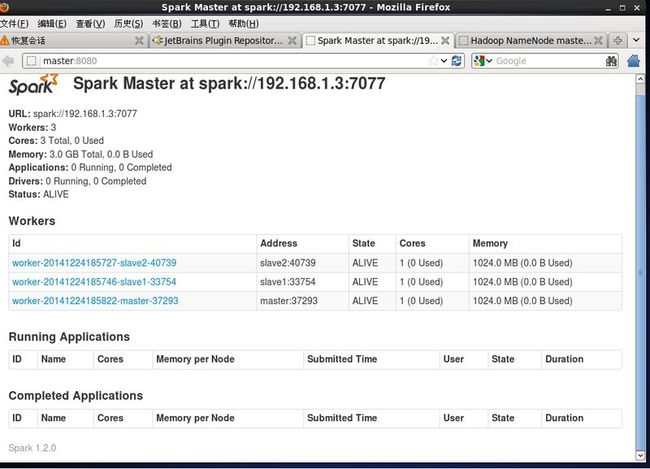
保存退出,这样master中spark就安装完成了,slave节点和maser一样的设置
成功后如下图
另外说一些实用的界面
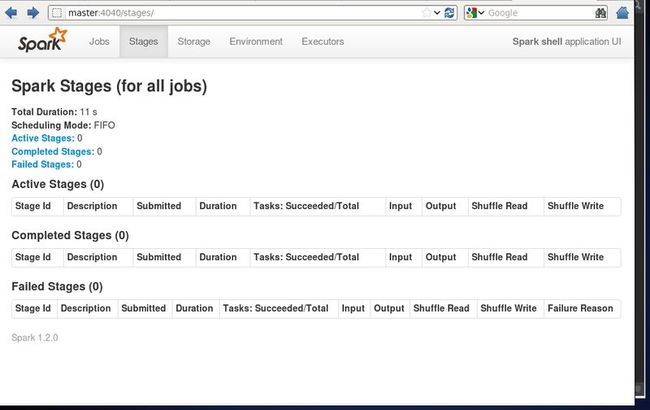
查看spark-shell状态
http://master:4040/stages/
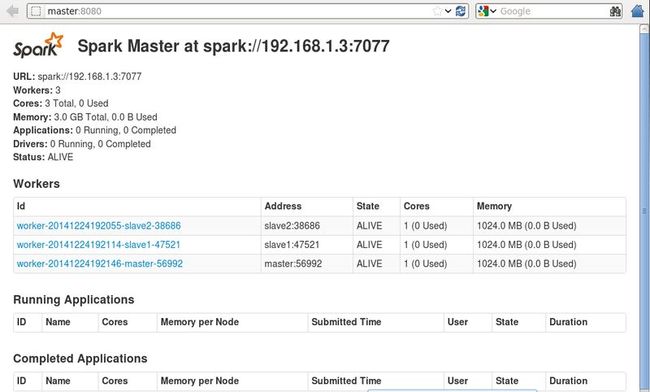
查看sprak中worker的状态
http://master:8080
查看dfs(datanode)的状态
http://master:50070
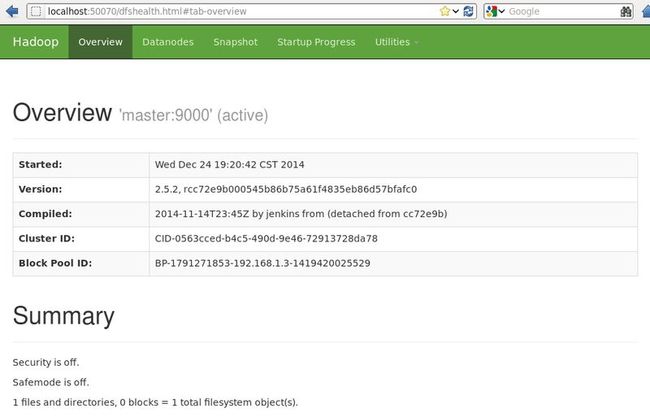
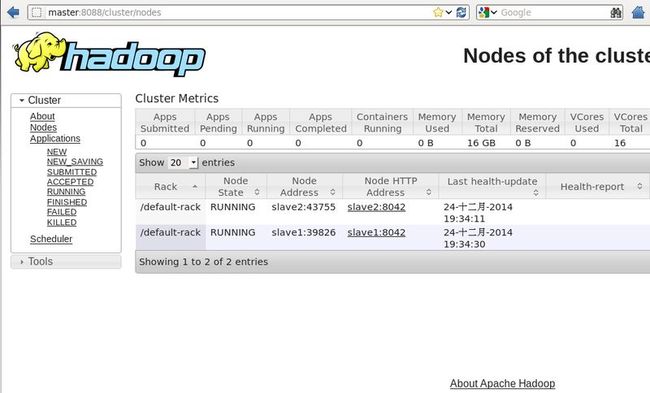
查看nodes的状态
http://master:8088