RSF 分布式服务框架-服务端工作原理
这是接上一篇文章《RSF 分布式服务框架设计》之后的续作,主要是 Hasor-RSF 的请求响应工作原理以及设计思路。
非常首先非常感谢关注这一系列文章的兄弟们,由于我个人时间不确定所以 RSF 更新起来比较无规律。近段时间抽出了时间仔细设计了一下 RSF 发现高性能和灵活的可扩展性还真不是那么轻易就能达到的。先说一下大体的工作流程。
RSF 工作流程:

大体的工作思路是:一个完整的 Rsf 请求调用会在客户端形成 Request接口,然后经过转换加工变为 Request消息,最后在通过Rsf协议传输到远程机器。远程机器在接收到 Request消息之后在将其重新转换为 Request接口,调用处理完毕之后在形成 Response 反馈给客户端。
这整个请求响应过程中一个方法调用会经历两次编码解码过程,一次在客户端一次在服务端。因此序列化的性能十分关键。此外 Rsf 数据包的简单与否也直接影响到 Encode,Decode的效率,这部分主要是网络 IO开销。
采用异步IO的优势在于每一个请求响应的处理都是异步的、非阻塞的。请求响应的过程中不影响各方本身业务系统的运行,同时可以兼顾更多的并发调用。
RSF 单机情况下保障高并发 & 高可用:
在高并发下,客户端会不断的向服务器发起请求,这类似于 DDOS 攻击,所以要求服务器有能力抵御这样的高并发请求。当遇到这样高并发请求的时,要先确保 RSF 服务器有能力处理这么多请求。如果超出自己的处理能力应当丢弃超出承受能力的请求包。同时为了保证高可用的目的,RSF 在丢弃请求之前应当做一件十分有意义的事情。通知客户端服务器资源紧张,让其可以选择其它服务器发起调用。这样一来客户端在发起 RSF 请求之后不至于因为服务器繁忙而傻等,也增加了调用成功几率。
线程也是一种资源。在实现机制上应当选用异步IO的网络模型,这样可以避免因为大量连接而产生过多的线程。毕竟维护这些线程也是需要消耗资源的。
考虑到业务线程执行时间不固定,同时网络IO的时间也因为网络状况而定。在架构设计上两者要完全分开来处理,这样才能两方面都兼顾到。为此 RSF 用到两个线程池,一个专门用于处理网络IO、另一个专注于处理业务调用。
当网络IO接收到完整的一个 RSF 消息时,将消息放入队列等待调用线程处理。
下面就分别讨论 网络IO线程、调用线程的处理逻辑。
IO线程:
这部分功能由 Netty 的 Worker 线程担当。对于IO线程主要的工作就是读取网络数据并且将其转换为 RSF 消息,然后放入队列。无论执行结果如何 RSF 的IO线程都会将处理结果反馈给客户端,下面这张图列出了它的工作流程(绿色部分是要做的事情,粉色部分代表运行状态)
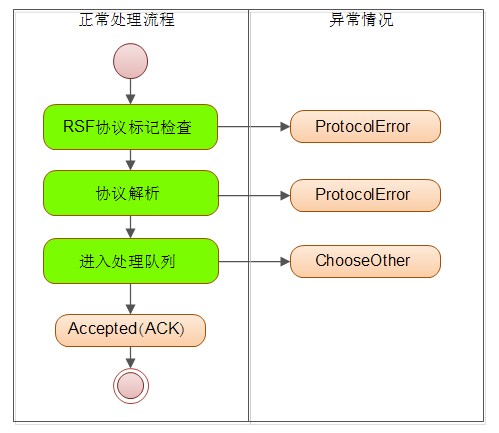
完整的IO线程逻辑会在多个类中完成,它们主要分散在 RSFProtocolDecoder、InnerServerHandler 两个类中。RSFProtocolDecoder 类主要负责将网络数据包转换成 RSF 消息并丢进 netty 的 pipeline 中。
/*RSFProtocolDecoder类*/
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
ByteBuf frame = (ByteBuf) super.decode(ctx, in);
if (frame == null)
return null;
//* byte[1] version RSF版本(0xC1)
byte version = frame.getByte(0);
short status = 0;
//decode
try {
status = this.doDecode(version, ctx, frame);//协议解析
} catch (Throwable e) {
status = ProtocolStatus.ProtocolError;
} finally {
if (status == ProtocolStatus.OK)
return null;
/*错误情况*/
frame.skipBytes(1);
fireProtocolError(ctx,version,frame.readLong(),ProtocolStatus.ProtocolError);
}
return null;
}
上面的代码来自于 Hasor-RSF 项目,rsf协议标记位于数据包的第一个字节。在上面代码中可以看到读取了第零个字节用来判断,主要判断逻辑位于 doDecode 方法。该方法返回了一个状态,状态值表示了数据包的解析是否成功。如果返回状态不是 “OK”或者执行过程中发生意外,都会导致 fireProtocolError 方法的执行。而fireProtocolError 方法的作用就是向客户端报告 ProtocolError 异常。
下面是 doDecode 方法的逻辑负责解析协议的,当协议正确解析之后通过 fireChannelRead 方法将读取到的 RSF 消息丢进 pipeline 交给后面的 Handler 进行处理。
/**协议解析*/
private short doDecode(byte version,ChannelHandlerContext ctx,ByteBuf frame) throws IOException{
ProtocolType pType = ProtocolType.valueOf(version);
if (pType == ProtocolType.Request) {
//request
Protocol<RequestSocketBlock> requestProtocol = ProtocolUtils.requestProtocol(version);
if (requestProtocol != null) {
RequestSocketBlock block = requestProtocol.decode(frame);
RequestMsg reqMetaData = TransferUtils.requestToMessage(block);
ctx.fireChannelRead(reqMetaData);
return ProtocolStatus.OK;/*正常处理后返回*/
}
}
if (pType == ProtocolType.Response) {
//response
Protocol<ResponseSocketBlock> responseProtocol = ProtocolUtils.responseProtocol(version);
if (responseProtocol != null) {
ResponseSocketBlock block = responseProtocol.decode(frame);
ResponseMsg resMetaData = TransferUtils.responseToMessage(block);
ctx.fireChannelRead(resMetaData);
return ProtocolStatus.OK;/*正常处理后返回*/
}
}
return ProtocolStatus.ProtocolError;
}
接下来 InnerServerHandler 类接收到 Netty 解码器发来的 RSF 消息并将其放入队列,下面是处理逻辑。
if (msg instanceof RequestMsg == false)
return;
//创建request、response
RequestMsg requestMsg = (RequestMsg) msg;
requestMsg.setReceiveTime(System.currentTimeMillis());
//放入业务线程准备执行
try {
Executor exe = this.rsfContext.getCallExecute(requestMsg.getServiceName());
exe.execute(new InnerRequestHandler(this.rsfContext, requestMsg, ctx.channel()));
//
ResponseMsg pack = TransferUtils.buildStatus(//
requestMsg.getVersion(), //协议版本
requestMsg.getRequestID(),//请求ID
ProtocolStatus.Accepted);//回应ACK
ctx.pipeline().write(pack);
} catch (RejectedExecutionException e) {
ResponseMsg pack = TransferUtils.buildStatus(//
requestMsg.getVersion(), //协议版本
requestMsg.getRequestID(),//请求ID
ProtocolStatus.ChooseOther);//服务器资源紧张
ctx.pipeline().write(pack);
}
在前面提到 RSF 会在高并发访问的情况下,依照自己的实际能力来合理的丢弃过载的请求。以上代码就是这个逻辑的重要保证。被服务器接受的 RSF 请求会响应 ACK,由于系统过载要求客户端选择其它服务提供者时会收到 ChooseOther 包。
至于之后就没有什么了,简短的两段代码其目的就是为了快速的处理网络传来的 RSF 数据包。处理完毕之后会迅速处理下一个 RSF 数据包。
调用线程:
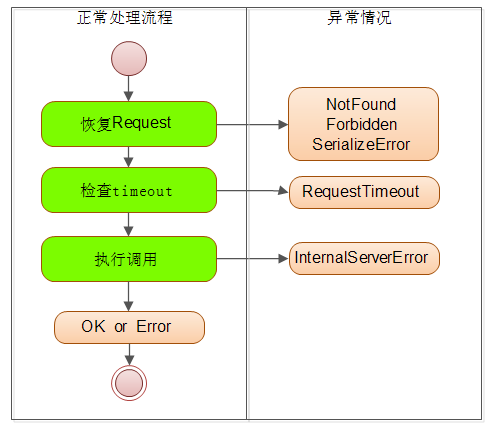
调用线程采用的是 ThreadPoolExecutor 类实现的。该类是一个固定数量的线程池,同时可以使用有容量限制的队列。正好符合 RSF 对调用线程的要求。
调用线程的入口程序位于 InnerRequestHandler 类中。调用线程的处理逻辑分为三个步骤:
一、将 RSF 消息转换为 Request/Response 接口,这会引发反序列化操作。
二、检查 timeout 。
三、执行调用,并向客户端写入返回值。
其中必须要特殊说明的是 timeout 检查。在 RSF 中超时时间在客户端和服务端都有配置。客户端在发起 RSF 请求的时就会开始记录时间,一旦调用超时就会丢弃所有远程针对此次请求的 Response 响应。
同时作为服务器,在接收到 RSF 数据包并向客户端发送 ACK 时就会记录请求到达服务端的那一刻时间。当正式开始执行调用的时候,调用线程会检查时间差。是否达到了请求中要求的超时时间,如果超时后面的调用也不需要进行了。
这里要注意的是,调用过程采用的超时判断是依照客户端传来的时间以及服务端配置的超时时间共同决定的。假如客户端配置的超时时间是3000毫秒,服务端配置的是 1000 毫秒。
那么客户端发起调用的时候会等待3000毫秒来接受返回值,但是在服务端由于要求是1000毫秒因此当服务端收到调用请求回应ACK之后,需要在1000毫秒之内正式执行 RSF 调用,否则调用线程会抛弃到这个调用回应客户端 Timeout。
所以要注意服务端配置的 timeout 不是业务方法最长可执行时间,而是 RSF 在回应 ACK 之后最大的等待调用时间。下面是这段业务逻辑代码
private RsfResponseImpl doRequest() {
RsfRequestImpl request = null;
RsfResponseImpl response = null;
try {
request = RuntimeUtils.recoverRequest(//
requestMsg, new NetworkConnection(this.channel), this.rsfContext);
response = request.buildResponse();
} catch (RsfException e) {
Hasor.logError("recoverRequest fail, requestID:" +
requestMsg.getRequestID() + " , " + e.getMessage());
//
ResponseMsg pack = TransferUtils.buildStatus(//
requestMsg.getVersion(), //协议版本
requestMsg.getRequestID(),//请求ID
e.getStatus());//回应状态
this.channel.write(pack);
return null;
}
//1.检查timeout
long lostTime = System.currentTimeMillis() - requestMsg.getReceiveTime();
int timeout=validateTimeout(requestMsg.getClientTimeout(),request.getMetaData());
if (lostTime > timeout) {
response.sendStatus(ProtocolStatus.RequestTimeout, "request timeout. (client parameter).");
return response;
}
//2.执行调用
try {
RsfFilter[] rsfFilters =this.rsfContext.getRsfFilters(request.getMetaData());
new InnerRsfFilterHandler(rsfFilters,InnerInvokeHandler.Default).doFilter(request,response);
} catch (Throwable e) {
//500 InternalServerError
response.sendStatus(ProtocolStatus.InternalServerError, e.getMessage());
return response;
}
return response;
}
扩展方式:

扩展 RSF 采用大家都熟悉的 “Web开发模式“,将 RSF 请求封装为 Request/Response。在此基础上通过 RsfFilter 完成扩展。扩展 RSF 实现更复杂的逻辑只需要简单的实现这个过滤器即可。
public class DemoRsfFilter implements RsfFilter {
public void doFilter(RsfRequest request, RsfResponse response,
RsfFilterChain chain) throws Throwable {
try {
//before
chain.doFilter(request, response);
} catch (Exception e) {
//throws
} finally {
//after
}
}
}
看到上面的扩展方式是不是很情切?开发者可以根据发来的调用请求来决定是否真的调用业务逻辑,或者是选择调用其它服务返回业务远程服务执行的结果。
response.sendData(...);
又或者通知客户端调用失败,返回一个错误消息:
response.sendStatus(ProtocolStatus.Unauthorized, ...);
测试结果 & 性能指标:
经过测试这样的架构性能表现确实很令人兴奋,当然在我的实现中还是有很多地方是可以继续优化的。下面是测试的服务类一个 sayHello 的服务:
public class TestServices {
public String sayHello(String msg) {
return msg;
}
}
服务器:选用我的开发机一台笔记本电脑配置如下:
Intel Core(TM) i5-2520M 4核 CPU @2.5G 、普通 100M网卡、Windows 7 64位操作系统,8G内存。
服务端可处理的最大队列设为:4096,有 4 条线程负责处理调用、5 条线程负责处理网络IO,1 条线程负责侦听网络端口。
客户机:是一台比较老的笔记本,配置为: Intel Core 2 Duo 双核 CPU,也是普通 100M 网卡。
在测试期间使用一个客户端模拟 50 条线程发起请求,每条请求不断的往服务器发送调用请求,任何服务端的返回都丢弃不管。
连接方式为:两台电脑网线直连中间不经过路由器。
测试结果是:服务器峰值可以处理约 1.7W 的请求,CPU 消耗维持在 80%~90% 左右、网卡使用率维持在 30%~40%。因为客户端疯狂的发送数据包所以会导致客户端很多请求收到了 ChooseOther 回应。
这个测试结果是目前阶段的测试结果,各个系统参数尚未进行调优。
出了并发测试还做过单连接下的压力测试,和上面的参数一样,单台机器下压测服务器可以处理一个连接内7000+ 请求。
淘宝的HSF,在专业服务器上 16核 CPU,下 2000+连接,性能据说可以跑到 10W。 RSF 由于开发仅仅完成了主要部分。再加上测试环境不一样,性能还不好放在一起比较。
总的来说 RSF 的初期表现还是很让人满意的,也欢迎各位大神拍砖,讨论。
---------------------------------
相关链接:
RSF-传输协议:http://my.oschina.net/u/1166271/blog/342091
项目地址:http://www.oschina.net/p/hasor