WebSphere简单故障排查
工作中经常遇到这样那样的或有迹可循、或“灵异”的情况:WebSphere在某次停止后无法启动了,部署在集群上的应用无法通过IHS访问,应用更新后重启服务器发送回滚……出现问题当然都可以联系专门的中间件管理员来解决,但等管理员赶到现场,也许时间已过去半天,问题也许很简单,几分钟就能解决,所以如果你会一些基本的排查技巧和诊断方法,那么这些小问题就可以自己迎刃而解了。
下面我就介绍几种常见的简单错误,希望对于现场人员能有所帮助:
应用无法访问
下面是一张常见的由IBM HTTP SERVER(IHS)转发到后端AppCluster上的拓扑结构:
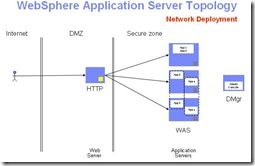
应用无法访问,问题可以出现在HTTP Server上,或者App Server上,更可能发生在数据库上,所以第一步需要缩小范围,确定问题发生的点。
我在这里假设IHS的应用地址为http://192.168.1.51 /yingyong
DMGR的访问地址是http://192.168.1.51:9060/admin
APP SERVER的应用地址为http://192.168.2.50:9080/yingyong和http://192.168.2.51:9080/yingyong
1. 找不到服务器或404错误
访问http://192.168.1.51,确定IHS是否正常,如果页面无法显示,那么去“服务”中尝试重启“IBM HTTP SERVER V6.x”。服务启动失败的话,“服务”只会提示你一句服务无法启动或者启动后又因为致命错误停止。所以你要到IBM\HTTPServer\bin目录下运行apache –k start或者httpd –k start,失败的话会有详细信息供参考。一般是端口被占用或者config目录下的httpd.conf格式出错(它会提示你出错的行数)。
如果IHS访问完好,那么尝试分别访问 http://192.168.2.50(51):9080/yingyong,如果访问失败,那么是IHS转发失败。
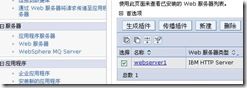
可以在管理控制台http://192.168.1.51:9060/admin中的“服务器”——“Web服务器”中勾选相应的webserver,“生成插件”并且“传播插件”。
很多IHS转发失败是因为应用发布过程中没有选则发布到webserver上,或在传播插件的过程中,由于目录访问控制等原因传播失败。你可以在“应用程序”中找到自己的应用,点击“管理模块”,确定是否正确的发布到app server上和webserver上了,注意首先在第一个框中选择要发布到集群和服务器,然后勾选模块前的勾,最后一定要点“应用”,而不是直接确定。
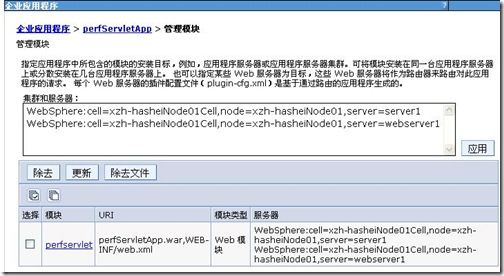
转发失败的原因很多,不过最快的解决方法是手动复制文件。生成插件后控制台会提示文件生成的位置,直接拿到然后复制到传播插件失败的位置就可以了。
不过我也遇到过很蹊跷的情况,明明部署正确,传播正确,确依旧无法访问。这时候你要看一下生成的plugin-cfg.xml文件
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/snoop/*"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/hello"/>
<Uri AffinityCookie="JSESSIONID" AffinityURLIdentifier="jsessionid" Name="/hitcount"/>
是否有你的应用url那行存在,不存在的话手动添加一下即可,不过记得下次生成插件后注意再修改。
最后要确定app server是否已经启动,是否遇到错误退出了,这点在下面一部分细说。
2. 505 Internal Error
505内部错误有三种情况,一是程序出错,不是本文讨论的重点。二是AppServer或应用程序没有正常启动,三是数据库连接失败。
AppServer是否运行可以通过访问管理控制台,查看JAVA进程确定。在profiles\AppSrv01\logs\server1目录下会有一个pid文件,此文件记录的PID号即为进程号。 Windows下在“任务管理器”点击“查看”—“选择列”,勾选PID-进程标识符即可显示。Unix/linux下运行ps –ef | grep PID或者ps –ef | grep java,查看该app的进程和所有的JAVA进程。注意:在安装DM profile的节点上,一般至少有DM、Node agent、app server三个java进程,注意区分。
确定服务器没有运行或者想重启时,在profiles\AppSrv01\bin下运行 startServer.sh(bat)即可启动服务器,观察启动状况,直到出现“为电子商务开放服务器 server1”,即为启动成功。如果失败,那就要打开logs下的SystemOut.log,查看最新的日志,查找error信息。
一般启动失败无外乎端口冲突、权限不够。
端口冲突
端口出错在SystemOut.log中的信息如下:
这时你可以用netstat –an 命令查看监听端口信息,然后用tcpview或者icesword等工具查看占用端口的进程,linux/unix下可以用netstat –an | grep LISTEN(或端口号)直接查看,然后使用lsof -i :端口号或者rmsock来查看占用端口的进程。
这时候你也许才恍然想起某个不经意的操作将websphere的端口占用了,怎么办?如果要WebSphere作出让步,那么可以修改profile_path\config\cells\cell_name\nodes\node_name 目录中serverindex.xml文件:
<endPoint xmi:id="EndPoint_1243228596786" host="*" port="9060"/>
</specialEndpoints>
<specialEndpoints xmi:id="NamedEndPoint_1243228596787" endPointName="WC_defaulthost">
……
看到端口号了么?不过要注意WC_adminhost、WC_defaulthost、 WC_adminhost_secure、WC_defaulthost_secure,也就是常用的管理端口、应用访问端口和它们各自的SSL端口,被修改后需要到profile_path\config\cells\cell_name再修改virtualhosts.xml文件中的相应端口(添加亦可),否则出现虚拟主机未定义的错误可别怪我没提醒。(我遇到过很多说用IHS可以访问,但是直接访问端口出错的情况,原因就是没有添加相应的虚拟主机,在管理控制台——虚拟主机——default host里添加改动后的端口就可以了)。
权限不足
权限不足一般发生在Unix/Linux下,比较常见的是安装websphere时新建了一个单独的用户和组,但是开发阶段权限管理不严导致开发人员也有root权限,启停没有su到was用户,等到权限回收之后发现无法启动服务了。这时候只要用root权限chown username/groupname 整个安装 目录即可。
还有一种情况是修改的端口<1024,在Unix/Linux下只能用root来起了。
其它情况
还要注意文件系统的情况,见过几次access.log和dump文件把文件系统撑满的。
应用更新失败
应用更新了,修改的文件直接上传到目录,重启应用程序,测试正常。等等!为何重启app server或者集群下重启dm后又变回修改前了呢?
这应该是dm的同步机制在捣鬼,你有没有注意到profiles\AppSrv01 \config\cells\cell_name\applications目录下也有你的程序,打开可以看到并不是程序所有的内容都在此,而是 web.xml和WEB-INF等重要内容。所以如果你更新的文件在config目录下也存在,那么你需要这里也更新一份。集群环境下还要注意 profiles\Dmgr的config目录下还有一份等着你呢。
3. 确定数据库无故障
这个很简单,只要用sqlplus连接数据库正常且能查询即可。
4. 日志文件很重要
日志文件是排查的依赖。我见过不少项目,因为处于试运行修改阶段,log4j中输出日志信息极多,每条sql语句都丝毫不差的打出来,导致1m大小的SystemOut.log文件十几分钟就写满,10个SystemOut.log存档也顶不过几小时的日志量(单个文件1~2M,总共10~20个存档是一般设置),等我赶到时案发现场已经荡然无存。(这种情况一般是重启能暂时解决问题,但是故障原因没有找到)
所以即时保存当时日志是很重要的,logs\server1下的 SystemOut.log、SystemErr.log一定要保存一份,并记下故障发生的时间。
WebSphere不像Weblogic,可以在console窗口后一直看到运行的日志,在unix/linux下,你可以用tail –f SystemOut.log来达到这个效果,windows下也有一个tail工具,后跟文件名运行就可以了。