mysql dba 面试题部分答案
MySQL DBA的基础面试题目
1, mysql的复制原理以及流程。
(1)先问基本原理流程,3个线程以及之间的关联。

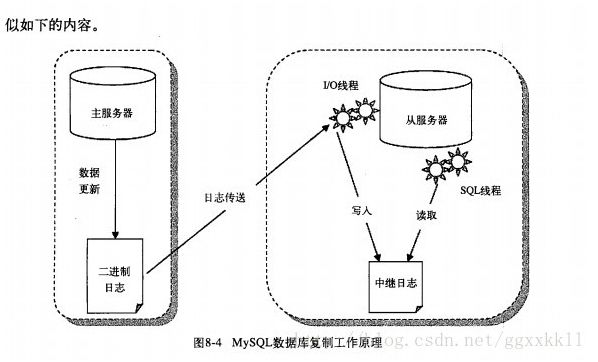
(2)再问一致性,延时性,数据恢复。
(3)再问各种工作遇到的复制bug的解决方法
2,mysql中myisam与innodb的区别,至少5点。
(1) 问5点不同
1>.InnoDB支持事物,而MyISAM不支持事物
2>.InnoDB支持行级锁,而MyISAM支持表级锁
3>.InnoDB支持MVCC, 而MyISAM不支持
4>.InnoDB支持外键,而MyISAM不支持
5>.InnoDB不支持全文索引,而MyISAM支持。
(2) 问各种不同mysql版本的2者的改进
mysql-server-4.1
增加了子查询的支持,字符集增加UTF-8,GROUP BY语句增加了ROLLUP,mysql.user表采用了更好的加密算法,innodb开始支持单独的表空间。
mysql-server-5.0
增加了Stored procedures、Views、Cursors、Triggers、XA transactions的支持,增加了INFORATION_SCHEMA系统数据库。
mysql-server-5.1
增加了Event scheduler,Partitioning,Pluggable storage engine API ,Row-based replication、Global级别动态修改general query log和slow query log的支持
(3)2者的索引的实现方式
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
3,问mysql中varchar与char的区别以及varchar(50)中的30代表的涵义。
(1)varchar与char的区别
char是一种固定长度的类型,varchar则是一种可变长度的类型
(2)varchar(50)中50的涵义
最多存放50个字节
(3)int(20)中20的涵义
int(M)中的M indicates the maximum display width (最大显示宽度)for integer types. The maximum legal display width is 255.
(4)为什么MySQL这样设计?
这需要根据经验来谈
4,问了innodb的事务与日志的实现方式。
(1)有多少种日志
错误日志:记录出错信息,也记录一些警告信息或者正确的信息
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
(2)日志的存放形式
innodb_data_file_path = ibdata1:100M:autoextend:max:500M
(3)事务是如何通过日志来实现的,说得越深入越好。
隔离性: 通过 锁 实现
原子性、一致性和持久性是通过 redo和undo来完成的。
在Innodb存储引擎中,事务日志是通过redo和innodb的存储引擎日志缓冲(Innodb log buffer)来实现的,当开始一个事务的时候,会记录该事务的lsn(log sequence number)号; 当事务执行时,会往InnoDB存储引擎的日志
的日志缓存里面插入事务日志;当事务提交时,必须将存储引擎的日志缓冲写入磁盘(通过innodb_flush_log_at_trx_commit来控制),也就是写数据前,需要先写日志。这种方式称为“预写日志方式”,
innodb通过此方式来保证事务的完整性。也就意味着磁盘上存储的数据页和内存缓冲池上面的页是不同步的,是先写入redo log,然后写入data file,因此是一种异步的方式。通过 show engine innodb status\G 来观察之间的差距
5,问了mysql binlog的几种日志录入格式以及区别
(1)各种日志格式的涵义
(2)适用场景
(3)结合第一个问题,每一种日志格式在复制中的优劣。
binlog的格式有三种,这也反应了mysql的复制技术:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。
参考连接http://www.361way.com/mysqlbinlog-type/934.html
6,问了下mysql数据库cpu飙升到500%的话他怎么处理?
(1) 没有经验的,可以不问
(2)有经验的,问他们的处理思路
7,sql优化。
(1) explain出来的各种item的意义
tid:id号
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
Extra:关于MYSQL如何解析查询的额外信息。将
(2) profile的意义以及使用场景。
Profile(查询到 SQL 会执行多少时间, 并看出 CPU/Memory 使用量, 执行过程中 Systemlock, Table lock 花多少时间等等.)
(3)explain中的索引问题。
8, 备份计划,mysqldump以及xtranbackup的实现原理,
mysqldump是最简单的逻辑备份方式。在备份myisam表的时候,如果要得到一致的数据,就需要锁表,简单而粗暴。而在备份innodb表 的时候,加上–master-data=1 –single-transaction 选项,在事务开始时刻,记录下binlog pos点,然后利用mvcc来获取一致的数据,由于是一个长事务,在写入和更新量很大的数据库上,将产生非常多的undo,显著影响性能,所以要慎用
优点:简单,可针对单表备份,在全量导出表结构的时候尤其有用。
缺点:简单粗暴,单线程,备份慢而且恢复慢,跨IDC有可能遇到时区问题
xtrabackup它实际上是物理备份+逻辑备份的组合。在备份 innodb表的时候,它拷贝ibd文件,并一刻不停的监视redo log的变化,append到自己的事务日志文件。在拷贝ibd文件过程中,ibd文件本身可能被写”花”,这都不是问题,因为在拷贝完成后的第一个 prepare阶段,Xtrabackup采用类似于innodb崩溃恢复的方法,把数据文件恢复到与日志文件一致的状态,并把未提交的事务回滚。如果同 时需要备份myisam表以及innodb表结构等文件,那么就需要用flush tables with lock来获得全局锁,开始拷贝这些不再变化的文件,同时获得binlog位置,拷贝结束后释放锁,也停止对redo log的监视。
(1) 备份计划
(2)备份恢复时间
(3)备份恢复失败如何处理
9, 500台db,在最快时间之内重启。
10, 在当前的工作中,你碰到到的最大的mysql db问题是?
11, innodb的读写参数优化
(1) 读取参数,global buffer pool以及 local buffer
Read_buffer_size、read_rnd_buffer_size、key_buffer_size、join_buffer_size、query_cache_limit、query_cache_size、sore_buffer_size、tmp_table_size、max_heap_table_size、max_connection、table_cache
(2) 写入参数
Innodb_log_buffer_pool_size、innodb_log_buffer_size、innodb_additional_mem_pool_size、
(3) 与IO相关的参数
Innodb_file_io_threads
(4) 缓存参数以及缓存的适用场景
7.查询缓存(Query Cache) -- optional
将客户端的SQL语句(仅限select语句)通过hash计算,放在hash链表中,同时将该SQL的结果集
放在内存中cache。该hash链表中,存放了结果集的内存地址以及所涉及到的所有Table等信息。
如果与该结果集相关的任何一个表的相关信息发生变化后(包扩:数据、索引、表结构等),
就会导致结果集失效,释放与该结果集相关的所有资源,以便后面其他SQL能够使用。
当客户端有select SQL进入,先计算hash值,如果有相同的,就会直接将结果集返回。
Query Cache的负面影响:
a.使用了Query Cache后,每条select SQL都要进行hash计算,然后查找结果集。对于大量SQL
访问,会消耗过多额外的CPU。
b.如果表变更比较频繁,则会造成结果集失效率非常高。
c.结果集中保存的是整个结果,可能存在一条记录被多次cache的情况,这样会造成内存资源的
过度消耗。
Query Cache的正确使用:
a.根据表的变更情况来选择是否使用Query Cache,可使用SQL Hint:SQL_NO_CACHE和SQL_CACHE
b.对于 变更比较少 或 数据基本处于静态 的表,使用SQL_CACHE
c.对于结果集比较大的,使用Query Cache可能造成内存不足,或挤占内存。
可使用1.SQL_NO_CACHE 2.query_cache_limit控制Query Cache的最大结果集(系统默认1M)
12 ,请简洁地描述下MySQL中InnoDB支持的四种事务隔离级别名称,以及逐级之间的区别?
SQL标准定义的四个隔离级别为:
read uncommited
read committed
repeatable read
serializable
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读(Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control 间隙锁)机制解决了该问题。注:其实多版本只是解决不可重复读问题,而加上间隙锁(也就是它这里所谓的并发控制)才解决了幻读问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
对于不同的事务,采用不同的隔离级别分别有不同的结果。不同的隔离级别有不同的现象。主要有下面3种现在:
1、脏读(dirty read):一个事务可以读取另一个尚未提交事务的修改数据。
2、非重复读(nonrepeatable read):在同一个事务中,同一个查询在T1时间读取某一行,在T2时间重新读取这一行时候,这一行的数据已经发生修改,可能被更新了(update),也可能被删除了(delete)。
3、幻像读(phantom read):在同一事务中,同一查询多次进行时候,由于其他插入操作(insert)的事务提交,导致每次返回不同的结果集。
不同的隔离级别有不同的现象,并有不同的锁定/并发机制,隔离级别越高,数据库的并发性就越差,4种事务隔离级别分别表现的现象如下表:
隔离级别 |
脏读 |
非重复读 |
幻像读 |
read uncommitted |
允许 |
允许 |
允许 |
read committed |
允许 |
允许 |
|
repeatable read |
允许 |
||
serializable |
13,表中有大字段X(例如:text类型),且字段X不会经常更新,以读为为主,请问
(1)您 是选择拆成子表,还是继续放一起?
(2)写出您这样选择的理由?
14,MySQL中InnoDB引擎的行锁是通过加在什么上完成(或称实现)的?为什么是这样子的
15 MyISAM 与innodb的区别
1. MySQL中控制内存分配的全局参数,有哪些?(注:至少写6个以上)
1>. Key_buffer_size
2>. innodb_buffer_pool_size
3>. innodb_additional_memory_pool_size
4>. innodb_log_buffer_size
5>. query_cache_size
6>.read_buffer_size
7>.read_rnd_buffer_size
2. 请简洁地描述下MySQL中InnoDB支持的四种事务隔离级别名称,以及逐级之间区别?
Read uncommitted: 在该隔离级别,所有事务都可以看到其他未提交的事务的执行结果。读取未提交的事务,称之为“脏读”。
Read Committed:一个事务只能看见已经提交事务所做的改变。因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read:这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。这种级别会出现幻读。
Serializable:这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题
它们之间的区别如下表:
隔离级别 |
脏读 |
非重复读 |
幻像读 |
Read uncommitted |
允许 |
允许 |
允许 |
Read Committed |
允许 |
允许 |
|
Repeatable Read |
允许 |
||
Serializable |
3. 小题集锦
1>.VARCHAR(N) 或 CHAR(N)中的N含义是:
N的含义表示N个字节。前者是变长,N的范围是 0~65535,后者是固定长度,N的范围是0~255。
2>.若一张表中只有一个字段VARCHAR(N)类型,utf8编码,则N最大值为多少(精确到数量级即可):
由于utf8的每个字符最多占用3个字节。而MySQL定义行的长度不能超过65535,因此N的最大值计算方法为:(65535-1-2)/3。减去1的原因是实际存储从第二个字节开始,减去2的原因是因为要在列表长度存储实际的字符长度,除以3是因为utf8限制:每个字符最多占用3个字节。
因此N=(Floor(65535-1-2)/3)
3>.表中有大字段X(例如:text类型),且字段X不会经常更新,以读为为主,请问您
是选择拆成子表,还是继续放一起,并且写出您的理由?
答案:拆成子表
理由:可以提高其他字段查询和更新的效率,因为每页保存的行数越多,效率会越高。大字段X更新率低,单行读取时效率影响不大。但如果读取的行数越多,影响会越大。因此选择拆成子表更好。
4>.MySQL中InnoDB引擎的行锁是通过加在什么上完成(或称实现)的:
A. 数据块
B. 索引值
选择答案后,告诉我们为什么?
答:B。innodb表数据是索引组织表形式存放
5>.username字段定义为VARCHAR(40)和VARCHAR(200)有啥区别?
答:临时表varchar(200)占用空间更大
5>.MySQL数据库备份方式有那几种(只讨论InnoDB存储引擎),至少写四种。
1>.热备份
2>.冷备份
3>.温备份
4>.二进制日志备份
4. MySQL复制搭建M->N的过程,请简述各个步骤?(备注:M已经在线跑,N为新安装的MySQL服务器)
1> .在启动主从服务器时,必须用server_id启动选项给出其ID值。主从服务器的ID值不能相同。主服务器启动二进制日志。
2>.在主服务器上,创建一个账户供从服务器连接主服务器并请求修改信息。
3>.连接到主服务器并通过执行showmaster status 语句确定当前的复制坐标。
4>.在从服务器上为将被复制的数据库建立一份完备的副本。
5>.连接到从服务器并使用changemaster 语句来配置它,包括把用来连接主服务器的参数和初始化复制坐标告诉从服务器。
6>.从服务器开始复制。
6. SQL语句优化
原SQL语句:
SELECTID,WAYBILL_NO,EXP_TYPE,PKG_QTY,EXPRESS_CONTENT_CODE,EFFECTIVE_TYPE_CODE
FROM T_EXP_OP WHERE ORDERID NOT IN(SELECTORDERID FROM T_EXP_OP WHERE AUX_OP_CODE IN ('NEW','UPDATE','DELETE') AND((OP_CODE IN (176, 162, 171, 131, 136)AND EXP_TYPE IN ('10', '20', '30')) OR(OP_CODE IN (191, 121)AND EXP_TYPE IN ('10', '20')) OR (OP_CODE IN (181,111)AND EXP_TYPE = '10'))) LIMIT 10;
条件:
T_EXP_OP表主键为BIGINT类型的ID字段,存储引擎为InnoDB,无其他索引
优化后为(提示:优化成一条简单的SQL语句,即无子查询,无JOIN关联):
SELECT ID, WAYBILL_NO, EXP_TYPE, PKG_QTY,EXPRESS_CONTENT_CODE, EFFECTIVE_TYPE_CODE
FROM T_EXP_OP
WHERE
AUX_OP_CODENOT IN (‘NEW’, ‘UPDATE’, ‘DELETE’)
AND(OP_CODE NOT IN (176, 162, 171, 131, 136, 191, 121, 181,111)
ANDEXP_TYPE NOT IN(‘10’, ‘20’, ‘30’))
LIMIT 10;
7. 分页SQL语句优化
原SQL语句:
SELECT * FROM test FORCE(idx_m_n) WHEREm=1 ORDER BY n LIMIT 1000,10;
条件:
Test表为InnoDB存储引擎,主键为BIGINT类型的ID字段,二级索引:idx_m_n(m,n)
优化后为:
索引要修改为: idx_m_n(m,n,ID);
SELECT a.* FROM test a
inner join
(SELECT ID FROM test FORCE(idx_m_n) WHEREm=1 ORDER BY n LIMIT 1000,10 ) b
on a.id=b.id
请简述优化的理由:
1>.二级索引中没有ID字段,无法达到最优化
2>.采用多表连接,效率会更高
3>.
8. 语句挑错
SQL语句:
SELECTM.columnname……,N.* columnname…..
FROMleft_table M LEFT JOIN right_tableN
ON M.columnname_join=N. columnname_join ANDN. columnname=XXX AND M.columnname=XXX
请问本SQL语句哪里不合理,为啥不合理?
答:N.* columnname….. 应该改为N.columnname……
空格符有明显错误,如:M. columnname_join应改为:M.columnname_join,N.columnname_join, N. columnname同理。
9. [SELECT *] 和[SELECT 全部字段]的2种写法有何优缺点,至少写出四点
1>.前者要解析数据字典,后者不需要
2>.结果输出顺序,前者与建表列顺序相同,后者按指定字段顺序。
3>.表字段改名,前者不需要修改,后者需要改
4>.后者可以建立索引进行优化,前者无法优化
5>.后者的可读性比前者要高
10. HAVNG 子句 和 WHERE的异同点,至少写出3点
1>.语法上:where 用表中列名,having用select结果别名
2>.影响结果范围:where从表读出数据的行数,having返回客户端的行数
3>.索引:where 可以使用索引,having不能使用索引,只能在临时结果集操作
4>.where后面不能使用聚集函数,having是专门使用聚集函数的。
11. 分布式数据库产品的特点(至少写4条)
1>.数据分布在多个异地点,抗灾性强
2>.并发性高
3>.受网络影响很大
4>.单机的性能不是特别重要,但是总体成本很高。
5>.扩展性强
12. 数据拆分架构的优缺点(至少写8条)
1>.透明性,程序不需要做任何修改
2>.解决集中数据库的扩展局限性。实现水平扩展问题,涉及到数据的拆分问题
3>.提高数据库服务的性能、可靠性、可用性
4>.实现技术不难,开发成本和维护成本可控
5>.测试成本高
6>.无法支持分布式事务
7>.数据拆分后数据合并难
8>.部分功能限制
9>.扩展受限