Hadoop编写调试MapReduce程序详解
编程学习,最好的方法还是自己动手,所以这里简单介绍在Hadoop上编写调试一个MapReduce程序。
先说一下我的开发环境,我的操作系统是Centos6.0,Hadoop版本是0.20.2,开发环境是eclipse。在Hadoop的0.20.0版本以后,都包含一个新的Java MapReduce API,这个API有时也称为上下文对象,新的API在类型上不兼容以前的API。关于新旧API的区别,这里先不做介绍了,只是在编程的时候一定要注意下,网上好多MapReduce的程序是基于旧的API编写的,如果自己安装的是新版的Hadoop,就会在调试时出现错误,初学者不明白这一点或许会走弯路。
1问题描述:查找最高气温。就是从气候日志数据中查找当年的最高气温,假设每一条记录的格式如下:“China2013inbeijing023isok0",其中2013是年份,023是温度记录,ok表示数据是完好的(为了简单易懂,省略其他的信息),我们的任务是从大量的数据记录中找出北京2013年的最高气温。这样的数据很适合用MapReduce来处理。
2问题分析,这个问题很简单,这里用这么简单的数据只是为了说明在Hadoop上编写调试MapReduce程序的过程。对于一条数据这需要提取出来年份和温度,然后找出最大温度就行了。这了类似于分治法,每一个Map过程就是分得过程,Reduce就是合的过程。
3 编码:
3.1Map函数:
//载入一些必要的包
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Mapper;
//新版APIMap过程需要继承org.apache.hadoop.mapreduce包Mapper类,并重写其map方法
public class MaxtemMapper extends
Mapper<LongWritable,Text,Text,IntWritable>{
private static final int MISSING=9999;
public void map(LongWritable key,Text value,Context context)
throws IOException,InterruptedException{
String line=value.toString();//把Text类的对象转化为String类来处理
String year=line.substring(5,9);//该String的第5-9就是年份
int airtemperature;
//有的数据中温度前面带”+“,需要处理下,带”+“的话第19到21为温度,不带的的话第18到21
//为温度
if(line.charAt(18)=='+'){
airtemperature=Integer.parseInt(line.substring(19, 21));
}
else {
airtemperature=Integer.parseInt(line.substring(18,21));
}
System.out.println("year:"+year+"tem:"+airtemperature);
判断数据是否是正确的
String quality=line.substring(23, 25);
if(airtemperature!=MISSING && quality.matches("ok")){
context.write(new Text(year), new IntWritable(airtemperature));
}
}
}
3.2Reduce函数:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxtemReducer extends
Reducer<Text,IntWritable,Text,IntWritable>{
public void reduce(Text key,Iterator<IntWritable> values,
Context context)
throws IOException,InterruptedException{
int maxValue=Integer.MIN_VALUE;
while(values.hasNext()){
maxValue=Math.max(maxValue,values.next().get());
}
context.write( key, new IntWritable(maxValue));
}
}
3.3执行MapReduce过程
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature{
//the main function
public static void main(String [] args)throws Exception{
Configuration conf=new Configuration();
if(args.length!=2){
System.out.println("Usage: Maxtemperature
<input path> <output path>");
System.exit(-1);
}
Job job=new Job(conf,"MaxTemperature");
job.setJarByClass(MaxTemperature.class);
FileInputFormat.addInputPath(job, new
Path(args[0]));
FileOutputFormat.setOutputPath(job, new
Path(args[1]));
job.setMapperClass(MaxtemMapper.class);
job.setReducerClass(MaxtemReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
//output the details of the work
System.out.println("name:"+job.getJobName());
System.out.println("isSuccessful?:"+
(job.isSuccessful()?"yes":"no"));
}
}
4进行单元测试:
编写完程序后需要进行单元测试,分别对Map函数和Reduce函数进行测试,功能正确后,就可以在小规模集群上进行测试,测试成功后就可以在Hadoop集群上进行运行。这里先不介绍单元测试的知识,后面再专门介绍如何在Hadoop中使用MRUnit进行单元测试。MRUnit是由Couldera公司开发的专门针对 Hadoop中 编写MapReduce单元测试的框架,基本原理是JUnit4和 EasyMock。MR就是Map和Reduce的缩写。MRUnit框架非常精简,其核心的单元测试依赖于JUnit。而且MRUnit实现了一套 Mock对象来控制OutputCollector的操作,从而可以拦截OutputCollector的输出,和我们的期望结果进行比较,达到自动断言 的目的。
有了MRUnit,对MR程序做重构的时候,只要明确输入和输出,就可以写出单元测试,并且在放到群集校验前进行试验,从而节省时间和资源,也 能更快的定位到问题。而进行重构的话,只要写得足够详细的单元测试都是绿色的话,那么基本就可以保证在群集运行的结果也是正常的。
MRUnit不在Apache标准的Hadoop的发行版中,而是在Couldera公司的增强版本中hadoop- 0.20.1+133.tar.gz的contrib\mrunit\hadoop-0.20.1+169.56-mrunit.jar,已经贴在附件 中。只要把它和Junit4的jar添加到Hadoop程序项目的classpath中,就可以使用MRUnit了。
4准备测试数据:
4.1建立一个text文档,test.text内容如下
china2013inbeijing023isok china2013inbeijing024isok china2013inbeijing+25isok china2013inbeijing026isok china2013inbeijing027isok china2013inbeijing028isok china2013inbeijing029isok china2013inbeijing030isok china2013inbeijing031isok china2013inbeijing132isok china2013inbeijing033isok china2013inbeijing034isok
4.2在HDFS的工作目录下建立一个文件夹input,把test.text上传到input目录里:

4.3配置运行参数:

注意在程序运行之前output文件夹是不存在的。hdfs://localhost:9000/user/XXX/input/test.text是输入文件的绝对目录。
4.4运行:
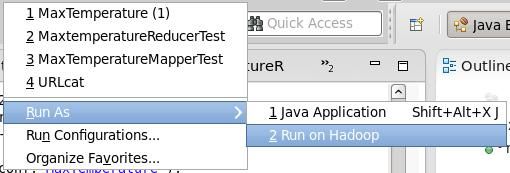
运行结果:
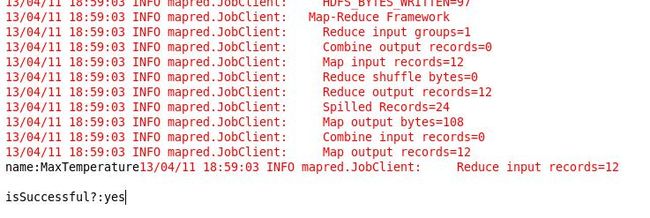

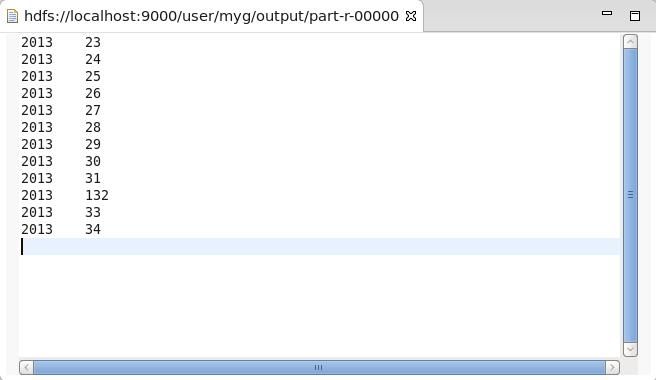
5 在集群上运行:
5.1打包
Prpject点选右键--Export
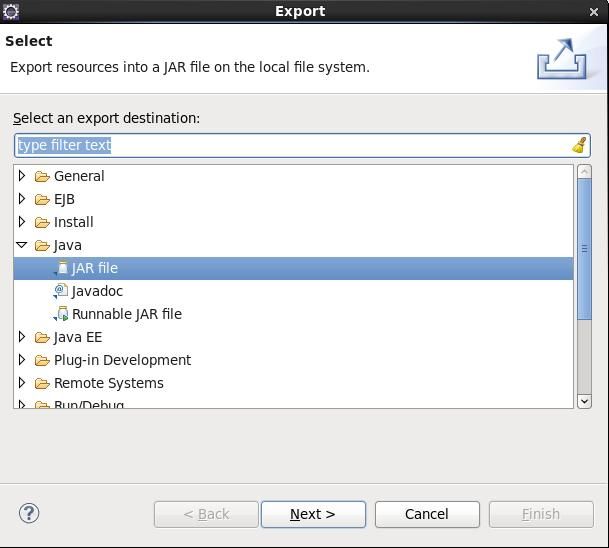
按照提示将程序打包为jar文件。在命令行方式下按照如下命令格式调用即可:
Hadoop jar /home/.../xxx/.../test.jar /home/.../xx/.../output
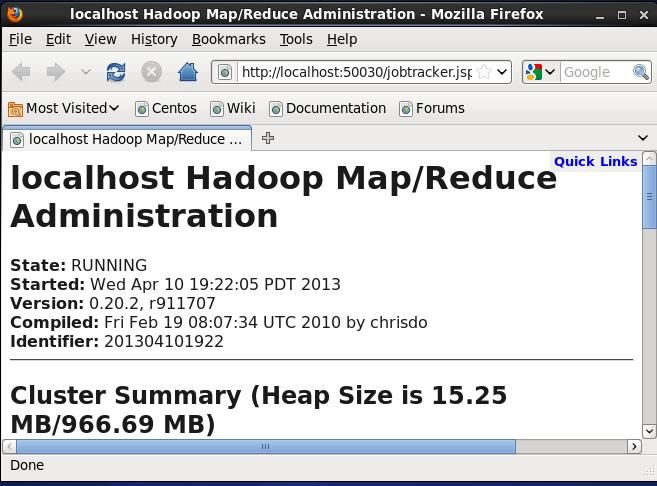
6 MapReduce的Web界面:
用浏览器访问:http://localhost:50030/就可以找到用户界面信息,在这里可以很方便的进行作业跟踪,查找作业完成情况后的统计信息,以及一些相关的日志信息:
时间有限,中间的一些具体的细节,比如Hadoop集群的配置,Hadoop的Eclipse开发环境的配置,Hadoop命令行方式下的操作,后面再做专门讲解。