医学教育网批量资源下载程序之——探路
在上一个博文里,博主已实现用python登陆了 www.med66.com 网站。
博文:http://my.oschina.net/hevakelcj/admin/edit-blog?blog=357852
To www.med66.com网站设计师:我只是想批量下载已花钱购买的资源罢了,没有恶意。
成功登陆,就意味着进入了网站的大门。剩下的工作就是进去之后在里面取想到的东西。
如下就是登陆成功后的网页,我们需要从这个页面获取课程列表。

打开Firefox的调试工具,看一下上面的元素是如何布局的。
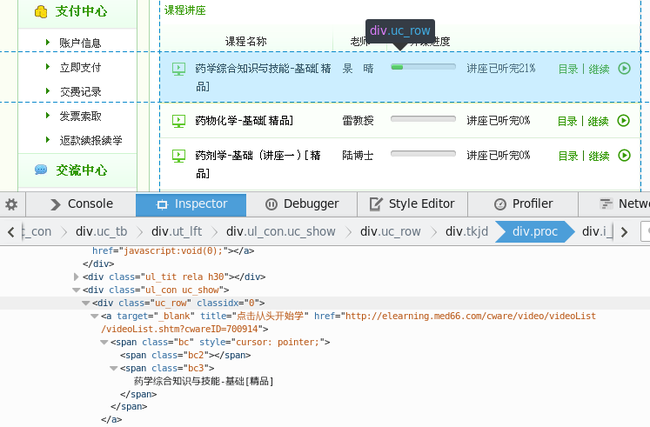
通过Firefox的调试工具很容易找到课程列表的元素,所有课程列表在 <div class="ul_con_uc_show"> 里。
而每一个<div class="uc_row"> 就是一个课程。
每个课程的"点击这里从头开始学"后面有个链接。如上 href="http://elearning.med66.com/cware/video/videoList/videoList.shtm?cwareID=700914"
我们分析一下这个链接地址,访问固定的页面 http://elearning.med66.com/cware/video/videoList/videoList.shtm
后面带个参数 cwareID=700914。这个"700914"就是课程的ID号。
进入该课程的下载页面: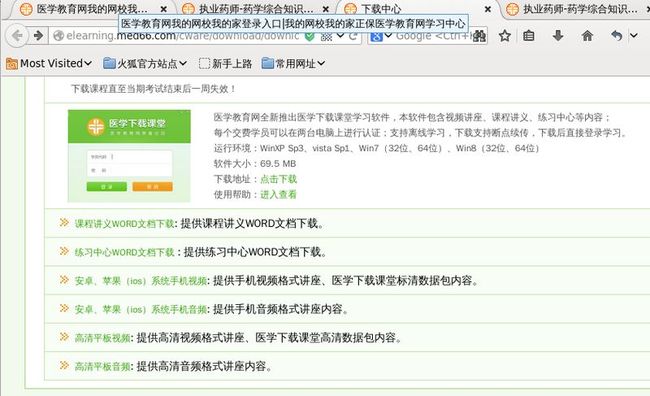
在这个“下载中心”的页面上可以下载讲义、习题、视频等。笔者惊讶地发现:下载中心的地址与课程ID有关:
http://elearning.med66.com/cware/download/downloadIndex.shtm?cwareID=700914
这个网址也是固定页面地址,后面带一个参数cwareID=700914。
笔者大胆地设想,是不是所有的课程下载页网都是以cwareID来区分课程呢?
笔者打开 “下载中心” 页面中的 “课程讲义WORD文档下载” 这个链接。观察其地址:
http://elearning.med66.com/cware/download/wordDownload.shtm?wordType=1&cwareID=700914
笔者再打开 “练习中心WORD文档下载”,观察其地址:
http://elearning.med66.com/cware/download/wordDownload.shtm?wordType=2&cwareID=700914
可看出两者只是wordType这个参数不同而已。举一反三,笔者以表格的形式展示:
| 下载内容 |
下载链接 |
| 讲义 | http://elearning.med66.com/cware/download/wordDownload.shtm?wordType=1&cwareID=700914 |
| 练习 | http://elearning.med66.com/cware/download/wordDownload.shtm?wordType=2&cwareID=700914 |
| 手机视频 |
http://elearning.med66.com/cware/download/videoDownload.shtm?cwareDownType=down12&cwareID=700914 |
| 手机音频 |
http://elearning.med66.com/cware/download/videoDownload.shtm?cwareDownType=down13&cwareID=700914 |
| 平板视频 |
http://elearning.med66.com/cware/download/videoDownload.shtm?cwareDownType=down14&cwareID=700914 |
| 平板音频 |
http://elearning.med66.com/cware/download/videoDownload.shtm?cwareDownType=down15&cwareID=700914 |
有了这张表,那么只要知道了课程的cwareID,就推导出下载该课程的资源的地址了。这是一个重大的破突!
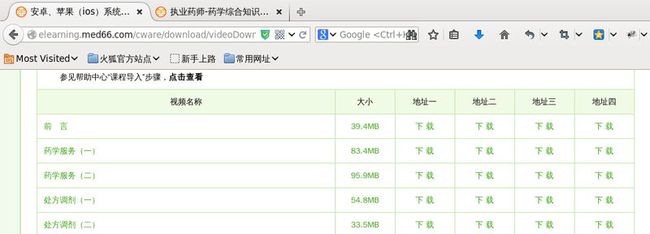
虽然能够进入资源的下载页面,但是下载页面并不是一下只下载全部,而是一小节一小节地下载。如下为 “手机视频” 下载页面截图:
用Firefox的调试工具打开看看元素的布局: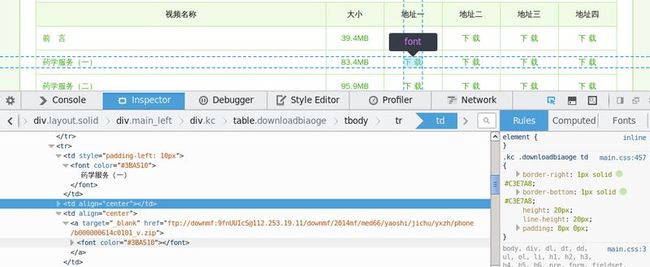
我们要捕获表的每一行,抓出小节的名称与资源链接地址。它的下载地址还不止一个,有4个下载地址可供选择。我们用第三个(应该是最不繁忙的一个吧)。
好了,今天就分析到这里,明天再分析程序流程。尽请期待!