《Nutch笔记》eclipse导入nutch-1.7
一、下载 apache-nutch-1.7-src.zip 包 和 apache-nutch-1.7-bin.zip 包
http://apache.fayea.com/apache-mirror/nutch/1.7/apache-nutch-1.7-bin.zip
http://apache.fayea.com/apache-mirror/nutch/1.7/apache-nutch-1.7-src.zip
二、
1、创建一个Java Project 。
2、复制 nutch-1.7-src 包下 java 包里的org整个包放在 项目的src包下。
3、复制 nutch-1.7-bin包里的conf 文件夹至 项目的src包下。
4、在conf 目录右键,Build Path → Use as Source Folder
5、复制nutch-1.7-bin 包里的 lib包下的所有jar包 至项目lib下没有lib就新建一个。
6、需要手动在 Bulid Path里引入这些Jar包。Libraries》Add JARS...然后选择项目lib下的所有jar包。
如果不想编译plugins 的话 ,看 二 ,要编译 plugins 就看 三
二、
1、复制 nutch-1.7-bin 包下的 plugins 文件夹整个放在 项目的 src 包下。
2、至此,正常情况项目只有一个文件报错,即StringUtil.java文件
3、修改 项目的 编码格式, 改为urf-8,上面错误解决。
三、
1、复制 nutch-1.7-src 包 .src/plugin 文件夹至 项目 src包下
2、如图,把plugin包下所有的 java 和 test 作为 Source folders。这里有挺多的,要一个个勾选,不能漏:Java Build Path》Source》Add Folder...
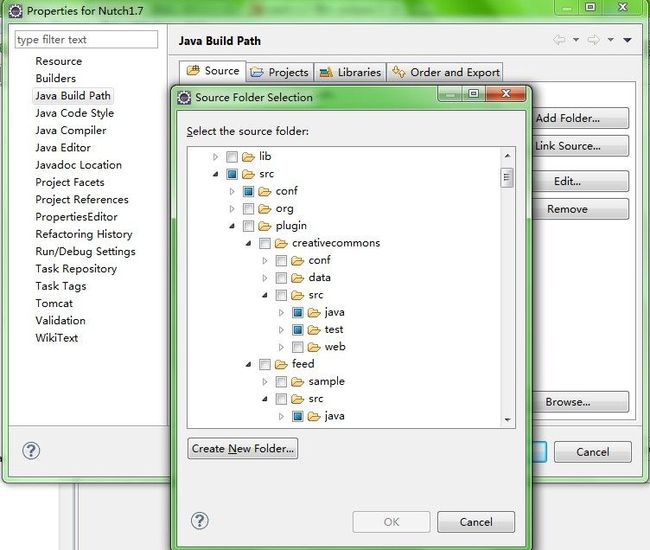
3、test是用来做单元测试的,其实是可以不用选的,如果不做单元测试的,可以选择不勾选test,但是之后要把里面所有的test手动删除,这里我就全部导入通过单元测试能够看懂代码的结构、功能。设置完毕以后项目结构就是这样子的。
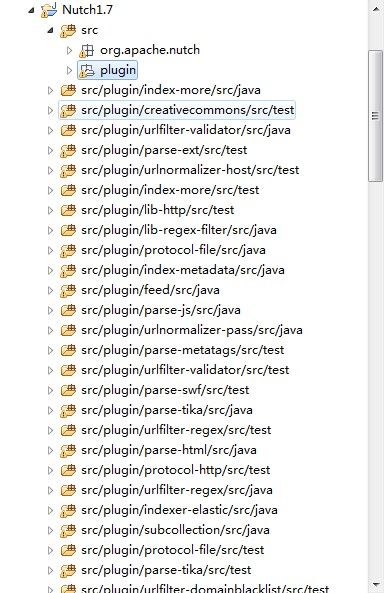
4、至此,项目的plugin包有部分包是报错的,这是因为该plugin引用了第三方包,需手动Build Path导入,这几个包在 nutch-1.7-bin/plugins 包下去找 rome-0.9.jar 、 nekohtml-0.9.5.jar 、 tagsoup-1.2.1.jar 、 javaswf.jar 、 automaton-1.11-8.jar。
5、至此,正常情况项目只有一个文件报错,即StringUtil.java文件
6、修改 项目的 编码格式, 改为urf-8,上面错误解决。
四、
OK,至此,导入工作完成了,项目也不会报错了。
1、开始执行。在conf包下,找到nutch-site.xml 在configuration节点下添加
<property>
<name>http.agent.name</name>
<value>Nutch-demo</value>
</property>
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
</property>
3、然后在src包下找到Crawl.java 文件
Run as → Run Configuration → Arguments
Program arguments输入:crawl urls -dir out -threads 20 -depth 2
VM arguments输入:-Xms32m -Xmx800m(注:这是设置内存大小,如果不设置会导致内存溢出异常)

4、然后执行该Java文件。
在windows下执行会报错,是因为hadoop的权限问题。
解决方法:网上下载一个包替换掉原来的hadoop-core-1.2.0.jar 包。
下载地址:http://download.csdn.net/detail/leave00608/7060765
5、至此应该能顺利执行,执行完毕之后我们应该能在项目的工作空间目录下看到out这个目录这就是nutch默认输出目录如图: 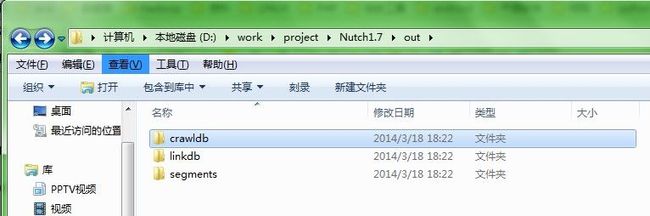
注:本文大部分出自http://blog.csdn.net/leave00608/article/details/21468871