爬虫技术总结
1、如何抓的问题
我们通常所说的利用爬虫“抓”数据,“扒”数据等等,那到底数据是如何“抓”、“扒”下来的呢?简单地讲,我们手工从网站上抓数据,无非就是用鼠标选中,复制、粘贴到记事本等文件中保存。而实际上网站中的内容都是通过浏览器解释html代码后展示给人们看的。所以复制的实质上还是复制的html的内容。因此,“抓”、“扒”的过程就是利用一段程序去复制html代码中的内容。
首先根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS、CSS,如果把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。所以最重要的部分是存在于HTML中的,下面我们就写个例子来扒一个网页下来。

运行结果如下:

上面这一堆看似乱码的东西就是百度首页的源代码,可以通过浏览器,右键,查看源代码的方式比较一下,结果是一样的。
2、分析抓网页的方法
通过代码,我们发现一共就3句话,甚至第2、3可以合并成一句话,首先第一句就是import urllib2,引入urllib2库。
![]()
首先我们调用的是urllib2库里面的urlopen方法,传入一个URL,这个网址是百度首页,协议是HTTP协议,当然你也可以把HTTP换做FTP,FILE,HTTPS 等等,只是代表了一种访问控制协议,urlopen一般接受三个参数,它的参数如下:
![]()
第一个参数url即为URL,第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间。
第二三个参数是可以不传送的,data默认为空None,timeout默认为 socket._GLOBAL_DEFAULT_TIMEOUT
第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面。
![]()
这句话就是把网页内容读出来,再打印出来而已,如果不加read方法,直接答应response则是打印的response这个对象的信息,
![]()
3、构造request
其实上面的urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容。比如上面的两行代码,我们可以这么改写
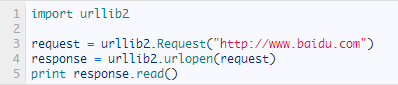
首先发送请求,服务器端响应请求得到应答将结果返回回来,再读出来打印到桌面,运行结果是完全一样的,只不过中间多了一个request对象,推荐大家这么写,因为在构建请求时还需要加入好多内容,通过构建一个request,服务器响应请求得到应答,这样显得逻辑上清晰明确。
4、Post与Get
上面的方法,对于静态网页来说是没问题的,只要再结合正则表达式等过滤匹配规则获取自己所需的内容是很简单的。但对于动态网页来说,情况就变得不太一样了,比如需要登录的网站,比如数据后台连数据库的网站(这种网站,浏览100页的内容,但仅从url上看100页的网址都一样,通过查看源代码的方式查看源码中可能并没有网页中现实的数据,而是script代码)。
因此,我们在发送请求时,还要传入一些额外的数据,这就是上面提到的data的作用。数据的传送分为Post和Get两种方式,一般面试官喜欢问一些小白同学,问你在写爬虫时是采用post还是get方式啊。二者有什么区别等。
Post和get最重要的区别就是是否把data内容加在url后面,比如http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E7%88%AC%E8%99%AB,这种网址访问的主页其实就是http://image.baidu.com/search/index,通过添加一个“?”,后面的格式基本为“XXX=***”的格式,其中“XXX=***”就是data中的数据,这种表达方式就是Get方式。而Post方式则是讲data隐式的进行传递。GET方式是直接以链接形式访问,链接中包含了所有的参数,当然如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。POST则不会在网址上显示所有的参数,不过如果你想直接查看提交了什么就不太方便了,大家可以酌情选择。
大家可以根据上面所讲的,自己判断一下,下面这两幅截图,分别是Post还是Get方式。程序本身不能准确的抓取网页,主要是让大家看一下Post和Get方式的使用方式及编码格式等。
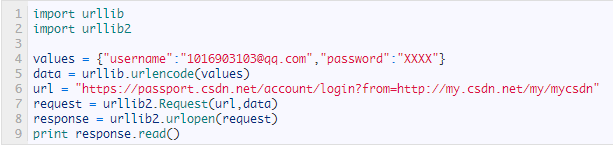

答案是上面的方式为Post,下面的方式为Get。很明显下面这幅图倒数第4行将data通过“?”添加到url里。
5、设置Headers
上面的抓取CSDN网站的代码你会不通过,会给你返回一个403错误。这就说明这种网站带有反盗链,就是人家不会让你爬虫轻易抓取人家网站的数据,毕竟数据是有价值的嘛。其实你用浏览器访问时可以正确的返回结果,而用爬虫程序则不让你访问。原因就是,人家可以检测你发送的请求中到底是什么客户端,如果是浏览器就让你访问,如果不是就不让你访问。所以解决办法就是将爬虫程序伪装成浏览器。伪装的办法就是设置headers。通过F12打开浏览器的调试功能,我们能看到大致如下图这样的内容:

其中最下面User-Agent,agent就是请求的身份,如果没有写入请求身份,那么服务器不一定会响应,所以可以在headers中设置agent,例如,下面的例子,这个例子只是说明了如何设置headers,重点在于说明设置格式。

这就是通常所说的伪装浏览器的方法,在请求时,就加入了headers传送,服务器若识别了是浏览器发来的请求,就会得到响应。另外,对付防盗链,服务器会识别headers中的referer是不是它自己,如果不是,有的服务器不会响应,所以我们可以在headers中加入referer,格式如下:

另外还有另外一些headers的属性,下面的需要特别注意一下:

其他的有必要的可以审查浏览器的headers内容,在构建时写入同样的数据即可。
6、Fiddler抓包工具
Fiddler抓包工具很好用的,它可以干嘛用呢,举个简单例子,当你浏览网页时,网页中有段视频非常好,但网站又不提供下载,用迅雷下载你又找不到下载地址,这个时候,Fiddler抓包工具就派上用场了,它会记录你发送的每条请求记录,包括每条请求中包含的表单数据,截图示例如下:

左边是请求的url链接,右边是每个链接请求工程中的一些信息数据,从这里我们可以看到data中的数据。有了它,我们就不需要用F12了。
7、Proxy(代理)的设置
你被封过账号或者IP吗?即便你通过各种方法,终于可以成功访问服务器了,但是某些网站会检测某一时间段内,某个账号或者某个IP的访问次数,如果访问次数过多,他就会把你拉入黑名单中,拒绝你的IP网址,甚至你的上层IP网段,导致局部一个地区,比如一个办公室,一栋大楼等整体都访问不了。这种网站基本都是比较大型的或者商业化的网站,比如新浪、淘宝等用户量的网站。如果网站需要登录就不要整IP代理了,同一个账号频繁更换IP地址访问也是明显不可能的。下面主要说明代理的设置用法。

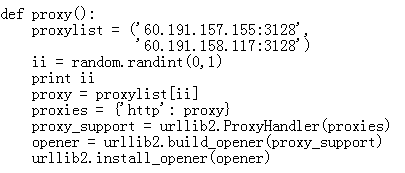
第一个例子就设置了一个代理IP,也是不靠谱的,最好的方式就是多设置几个,如第二个例子,通过http://www.youdaili.net/Daili/你可以找到很多代理IP,我们抓取国内网站时尽量选取中国的IP(虽然这种免费IP代理很多,不过免费的东西靠不靠谱就说不好了,实际上以我的经验,我会初始设置100个左右,根据他们的访问效率测试抓取,再筛选几个靠谱的代理正式抓取),第二个例子中用到了随机数,每次抓取都是随机选取一个IP代理。
8、Timeout设置
这个用的相对较少,timeout主要是设置等待多久超时,为了解决一些网站实在响应过慢而造成的影响。例如下面的代码,如果第二个参数data为空,那么要特别指定是timeout=多少,要写明形参,如果data已经传入,则不必声明。
![]()
![]()
9、异常处理
作为爬虫的抓取过程基本就那么多内容了,后面再将一些正则表达式的东西简单介绍一下基本就完事了,下面先说说异常处理的方法。先介绍一下抓取过程中的主要异常,如URLError和HTTPError。
URLError可能产生的原因主要有:网络无连接,即本机无法上网;连接不到特定的服务器;服务器不存在等。如下所示:

![]()
错误代号是11004,错误原因是getaddrinfo failed。这类错误相对来说比较少,理由是在我们抓取网页时,一般都会人工通过浏览器访问一遍,而最为常见的是HTTPError。
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字“状态码”。举个例子,假如response是一个“重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。
其他不能处理的,urlopen会产生一个HTTPError,对应相应的状态码,HTTP状态码表示HTTP协议所返回的响应的状态。下面将状态码归结如下:


HTTPError实例产生后会有一个code属性,这就是服务器发送的相关错误号。因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100~299范围的号码指示成功,所以我们只能看到400~599的错误号码。另外可能还会遇到10053、10060等状态码,一般都是服务器不稳定造成的,多刷新几次就好了。
下面写个例子感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这就是它的父类URLError的属性。

![]()
错误代号是403,错误原因是Forbidden,说明服务器禁止访问。
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以改写为:

首先对异常的属性进行判断,以免出现属性输出报错的现象。
不过,就我个人而言,我不喜欢单独捕获该类异常,因为在实际应用过程中,会出项各种各样的异常,爬虫任务往往都是几天几夜的连续工作,我们又不可能24小时盯着,所以一旦异常捕获不到就会造成爬虫程序的崩溃,而如果你还没有设置相关爬取进度的日志,这基本就是个失败的任务。所以在爬虫中,异常的捕获通常不仅仅是报告异常的原因,更重要的是增强程序的健壮性,不至于因异常而崩溃,所以通常我的做法就是从全局角度捕获所有异常。

可以在异常捕获后记录到log日志文件中,待所有任务初步完成后,可以再对log日志里有问题的内容进行二次处理。
10、Cookie的使用
Cookie是指某些网站为了辨别用户身份、进行session跟踪而存储在用户本地终端上的数据(通常经过加密),比如说有些网站需要登录才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到了目的了。
Opener
当你获取一个url,你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解为opener的一个特殊实例,传入的参数仅仅是url,data,timeout。如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需啊哟创建更一般的opener来实现对Cookie的设置。
Cookielib
Cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的cookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。它们之间的关系是:CookieJar——派生——>FileCookieJar——派生——>MozillaCookieJar和LWPCookieJar.
获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中。

我们使用以上方法将Cookie保存到变量中,然后打印出了cookie中的值,运行结果如下:

保存Cookie到文件
在上面的方法中,我们将Cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中就要用到FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存。
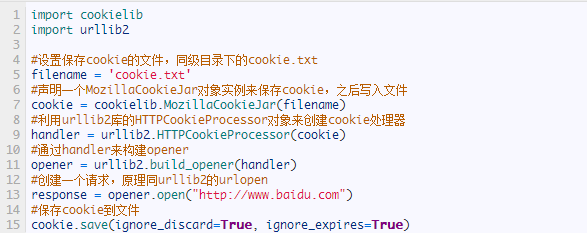
关于最后save方法的两个参数在此说明一下:
官方的解释如下:

保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中,我们查看一下内容:

从文件中获取Cookie并访问
那么我们已经做到把Cookie保存到文件中,如果我们以后想使用,可以利用下面的方法来读取cookie并访问网站,如图所示:
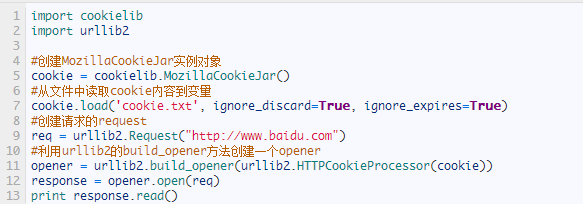
设想,如果我们的cookie.txt文件中保存的是某个人登录百度的cookie,那么我们提取这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
利用cookie模拟网站登录
下面以抓取某学校教育系统为例,利用cookie实现模拟登录,并将cookie信息保存到文件中。

以上程序的原理如下:
创建一个带有cookie的opener,在访问登录的url时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
11、正则表达式
前面十项,仅仅是想尽各种办法,突破各种常见限制,从而可以顺利访问网站,接下来的问题就是如何从一大堆html代码中提取我们需要的内容,主要介绍十分强大的正则表达式。
了解正则表达式

正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就很容易了。

正则表达式的语法规则
下面是Python中正则表达式的一些匹配规则:




正则表达式相关注解
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式“ab*”如果用于查找“abbbc”,将找到“abbb”。而如果使用非贪婪的数量词“ab*?”,将找到“a”。我们一般使用非贪婪模式来提取。
反斜杠问题
与大多数编程语言相同,正则表达式里使用“\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符“\”,那么使用编程语言表示的正则表达式里将需要4个反斜杠“\\\\”:前面两个和后面两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\\”表示。同样,匹配一个数字的“\\d”可以写成r”\d”。
Python Re模块
Python自带了re模块,它提供了对正则表达式的支持。主要用到的方法列举如下:

介绍这几个方法之前,我们先来介绍一下pattern的概念,pattern可以理解为一个匹配模式,那么我们怎么获得这个匹配模式呢?很简单的,我们需要利用re.compile方法就可以。例如:
![]()
在参数中我们传入了原生字符串对象,通过compile方法编译生成一个pattern对象,然后我们利用这个对象来进行进一步的匹配。
另外还有另一个参数flags,在这里解释一下这个参数的含义:
参数flag是匹配模式,取值可以利用按位或运算符‘|’表示同时生效,比如re.I | re.M。
可选值有:

在刚才所说的另几个方法例如re.match里我们就需要用到这个pattern了,下面我们一一介绍。

Re.match(pattern,string[,flags])
这个方法将会从string(我们要匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回None,如果匹配未结束已经到达string的末尾,也会返回None。两个结果均表示匹配失败,否则匹配pattern成功,同时匹配终止,不再对string向后匹配。下面我们通过一个例子解释一下:

运行结果:

匹配分析
第一个匹配,pattern正则表达式为‘hello’,我们匹配的目标字符串string也为hello,从头至尾完全匹配,匹配成功。
第二个匹配,string为hello CQC,从string头开始匹配pattern完全可以匹配,pattern匹配结束,同时匹配终止,后面的o CQC不再匹配,返回匹配成功的信息。
第三个匹配,string为helo CQC,从string头开始匹配pattern,发现到‘o’时无法完成匹配,匹配终止,返回None。
第四个匹配,同第二个匹配原理,即使遇到了空格符也不会受影响。
我们还看到最后打印出了result.group(),这个是什么意思呢?下面我们说一下关于match对象的属性和方法。
Match对象是一次匹配的结果,包含了许多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。


下面我们用一个例子来体会一下


Re.search(pattern,string[,flags])
Search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就会返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。我们用一个例子感受一下:

Re.split(pattern,string[,maxsplit])
按照能够匹配的子串将string分割后返回列表。Maxsplit用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。

Re.findall(pattern,string[,flags])
搜索string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下。

Re.finditer(pattern,string[,flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。我们通过下面的例子来感受一下:

Re.sub(pattern,repl,string[,count])
使用repl替换string中每一个匹配的子串后返回替换的字符串。当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0.当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。Count用于指定最多替换次数,不指定时全部替换。

Re.subn(pattern,repl,string[,count])
返回(sub(repl,string[,count]),替换次数)。

Python Re模块的另一种使用方式
在上面我们介绍了7个工具方法,例如match,search等等,不过调用方式都是re.match,re.search的方式,其实还有另外一种调用方式,可以通过pattern.match,pattern.search调用,这样调用便不用将pattern作为第一个参数传入了,大家想怎样调用皆可。
函数API列表

具体的调用方法不必详说了,原理都类似,只是参数的变化不同。