两篇小剖已经完成:
urllib2 对 urllib 改进了好些,整个思路都改了,变得更加灵活,有“高内聚,低耦合”的味道。
看看 urllib2 的新特性:
- 将对 url 的处理单独成一个 request 类
- URLopener 和 FancyURLopener 都下架,取而代之的是 OpenerDirector
- 另添加了 N 多 handlers,这些 handlers 主要对 HTTP 连接,HTTP request 或者 HTTP response 的处理,譬如往 HTTP request 中添加几个特定的 cookies 或者状态码处理,所有你能想到的 HTTP request 的预处理或者 HTTP response 的善后处理,稍后展开。
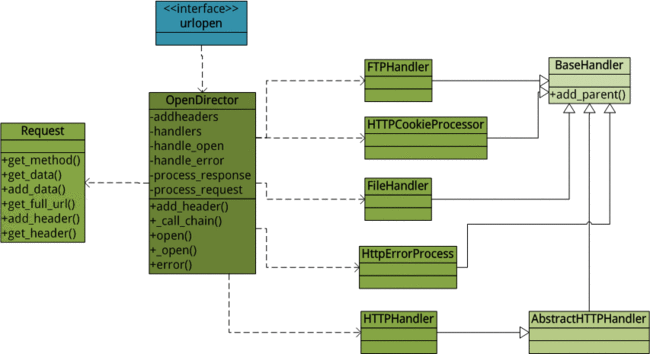
OpenerDirector
介绍完特性,应该能够想到 OpenerDirector 可以安装多个 handlers,想做什么就做什么,甚至可以自定义自己的 handler,我在项目中就遇到源码无法满足的需求,得“靠自己的双手”。
跟上篇 urllib 的套路一样,
|
1
2
3
|
用法一模一样。
urlopen 也新建一个对象,不过是一个 OpenerDirector 对象;它内部是通过调用 build_opener 方法来创建的:
urlopen 和 build_opener 方法的源码:
|
1
2
3
4
5
6
7
8
9
|
def
urlopen(url, data
=
None
, timeout
=
socket._GLOBAL_DEFAULT_TIMEOUT):
global
_opener
if
_opener
is
None
:
_opener
=
build_opener()
return
_opener.
open
(url, data, timeout)
def
build_opener(
*
handlers): 可以安装多个 handler
......
return
opener
|
目测这里可以传递多个 handlers 安装好后返回 opener。
_opener 是一个全局的对象,它调用 open() 它的作用和 urllib 一样,但做法是不同的。
从类 OpenerDirector 说起:
addheaders 添加 HTTP headers 的方法
handlers 各种处理工具类对象,里面可以包含上面提到的预处理和善后处理
handle_open 一个 key-value_list,存着发起连接的 handler,一般只有一个;key 是协议,http,https;value_list 就是方法集了
hander_error 一个 key-value_list 同上;根据状态码进行各种处理
process_response 一个 key-value_list 同上;预处理
process_request 一个 key-value_list 同上;善后处理
这四个成员变量很重要,因为各种 handler 内的方法会根据方法名安置在这个四个 key-value_list 中,在不同的时机调用。
add_handler 添加各种处理工具类对象,它会自动扫描整个对象中的所有方法,根据方法的名字添加到不同的 key-value_list 中。
_call_chain 这个取名叫链式调用,就是把 key-value_list 中的方法依次调用
open 关键来了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
def
open
(
self
, fullurl, data
=
None
, timeout
=
socket._GLOBAL_DEFAULT_TIMEOUT):
# accept a URL or a Request object
if
isinstance
(fullurl,
basestring
):
req
=
Request(fullurl, data)
else
:
req
=
fullurl
if
data
is
not
None
:
req.add_data(data)
req.timeout
=
timeout
protocol
=
req.get_type()
# pre-process request 预处理
meth_name
=
protocol
+
"_request"
# http_request ftp_request
for
processor
in
self
.process_request.get(protocol, []):
meth
=
getattr
(processor, meth_name)
# method method
req
=
meth(req) 进行各种处理
response
=
self
._open(req, data)
# post-process response 回复可能要进行修饰
meth_name
=
protocol
+
"_response"
# http_respond ftp_respond
for
processor
in
self
.process_response.get(protocol, []):
meth
=
getattr
(processor, meth_name) 进行各种对答复处理
response
=
meth(req, response)
return
response 返回
|
先构造 Request 对象;设置超时时间;预处理,连接,善后处理,一目了然。
_open 从 open 中得知,它在预处理和善后处理之间,应该负责连接访问服务器也就是发起连接的,从源码来看也没有说明秘密:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def
_open(
self
, req, data
=
None
):
# 如果有默认的处理,就用默认的处理方法
result
=
self
._call_chain(
self
.handle_open,
'default'
,
'default_open'
, req)
if
result:
return
result
# 如果没有默认处理,试着用 handle_open list 中方法的 http_open
protocol
=
req.get_type()
result
=
self
._call_chain(
self
.handle_open, protocol, protocol
+
'_open'
, req)
if
result:
return
result
# error
return
self
._call_chain(
self
.handle_open,
'unknown'
,
'unknown_open'
, req)
|
error 各种错误处理,或者处理各种状态码,从成员变量 handle_error 中选择方法
至此 OpenerDirector 介绍到这里
build_opener 这是一个全局方法,上面提到过,能创建 OpenerDirector 对象,并安装多个 handlers
这里他用的策略:默认安装 default_handlers,default_handlers 是内部指定的,倘若用户继承了 default handler,会用子类替代父类。
内置 handlers
我们知道,OpenerDirector 可以安装自定义的 handler,那就必须入乡随俗,自定义的 handler 必须被规范定义。
下面说到的是一堆内置的 handlers:
BaseHandler 所有 handler 都必须继承这个。
HTTPErrorProcessor HTTP 错误处理,内部有一个方法:
|
1
2
3
4
5
6
7
8
9
10
|
def
http_response(
self
, request, response):
code, msg, hdrs
=
response.code, response.msg, response.info()
# According to RFC 2616, "2xx" code indicates that the client's
# request was successfully received, understood, and accepted.
if
not
(
200
<
=
code <
300
):
# good
response
=
self
.parent.error(
'http'
, request, response, code, msg, hdrs)
return
response
|
如果状态码不是 200-300,就调用父类的 error,error 能调遣各种错误处理或者状态码处理 handers,交由他们处理。
HTTPDefaultErrorHandler 万能的,不想理会的错误就用它
HTTPRedirectHandler 重定向处理,状态码是 30X 的时候会用到
ProxyHandler 如果开了代理,会用到这个 handler
HTTPPasswordMgr 秘密管理器,它里面会根据不同的连接,不同的 realm 管理密码
AbstractBasicAuthHandler HTTP 认证抽象类
HTTPBasicAuthHandler 继承自 AbstractBasicAuthHandler 类,HTTP 基本认证
AbstractBasicAuthHandler 继承自 AbstractBasicAuthHandler 类;如果开了代理,需要用这个认证类
AbstractHTTPHandler HTTP 处理抽象类,其实不抽象了;它内部有一个 do_open() 方法,是 HTTP 连接的核心,它返回上一节提到过的 addinfourl 对象,动作也和上一节提到的 open_http() 大同小异。
HTTPHandler 这个类里有个 http_open() 方法,它会被安置在 OpenerDirector 对象的 handle_open list 中,很明显它是管理 HTTP 连接的,发送或者接受数据,其内部调用上面提到的 do_open() 方法。
HTTPSHandler HTTPS
HTTPCookieProcessor 里面有 http_request 和 http_response 方法,分别是 cookies 的预处理和善后处理,用作设置和提取 cookies
UnknownHandler 里面定义了 unknown_open 方法;当遇到无法理解的 url 时候,就会被调用
FileHandler 处理本地文件或者 ftp,这要视被传入的 url 而定
FTPHandler 封装了 ftp 的处理,会创建上一节提到的 ftpwrapper。
CacheFTPHandler 带缓存的 FTPHandler,里面主要记录最近 ftp 连接的信息(实际上是 ftpwrapper 对象),并各自设置了过期时间。
自定义 handlers
上面提到可以自定义 handlers,我们从处理 cookies 的类 HTTPCookieProcessor 看起,依葫芦画瓢:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class
HTTPCookieProcessor(BaseHandler):
def
__init__(
self
, cookiejar
=
None
):
import
cookielib
if
cookiejar
is
None
:
cookiejar
=
cookielib.CookieJar()
self
.cookiejar
=
cookiejar
def
http_request(
self
, request):
# add to request
self
.cookiejar.add_cookie_header(request)
return
request
def
http_response(
self
, request, response):
# extract from response 从 response 中导出
self
.cookiejar.extract_cookies(response, request)
return
response
https_request
=
http_request 一样
https_response
=
http_response
|
tips:结合上面的 open() 方法,http_request 中传入的参数 request 是 Request 对象;http_response 中传入的参数 response 是 addinfourl 对象。
很简单,我们试着写一个,作用是打印 HTTP reques 和 HTTP response 的头部:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from
urllib2
import
BaseHandler, build_opener
class
HTTPHeaderPrint(BaseHandler):
def
__init__(
self
):
pass
def
http_request(
self
, request):
print
request.headers
return
request
def
http_response(
self
, request, response):
print
response.info()
return
response
https_request
=
http_request
https_response
=
http_response
if
__name__
=
=
'__main__'
:
opener
=
build_opener(HTTPHeaderPrint)
|
结果是:
{}
Date: Sun, 25 Aug 2013 03:06:56 GMT
Server: BWS/1.0
Content-Length: 10433
Content-Type: text/html;charset=utf-8
Cache-Control: private
BDPAGETYPE: 1
BDUSERID: 0
BDQID: 0x8355f67f035cabd2
Set-Cookie: BDSVRTM=1; path=/
Set-Cookie: H_PS_PSSID=3194_1443_3139_2975_2981_2702; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=5300395E1E4ACB08A7C131F72AD493B6:FG=1; expires=Sun, 25-Aug-43 03:06:56 GMT; path=/; domain=.baidu.com
Expires: Sun, 25 Aug 2013 03:06:56 GMT
P3P: CP=" OTI DSP COR IVA OUR IND COM "
Connection: Close
可以看到,自定义的 handler 已经被安装成功,即 http_request 方法已被安置在 process_request list 中; http_response 方法已被安置在 process_response list 中。从结果看,request 的 HTTP 头并没有任何东西,因为我们并没有添加任何额外的头部,但在连接的时候,是有添加一些 HTTP 头部信息,但并没有被记录;返回的 HTTP response 中就有了。
总结
总结一下 urllib2:urlopen 是最高层的封装,很简单的一句话就可以爬数据了。其内部创建 OpenerDirector 对象并调用 open() 方法,open 方法会根据 url 构造 Request 对象,然后根据 process_request 内的方法进行预处理,根据 handle_open 内的方法,进行连接处理,根据 process_response 内的方法进行善后处理;当 url 不成功时候或者 HTTP response 状态码需要进一步处理,则会调用相应的错误或者状态码处理。
至此,urllib 和 urllib2 的小剖完毕,期中的秘密也不算多,但从 urllib 到 urllib2 的改进是值得我们在软件设计过程的值得深思的,明显 urllib2 比 urllib 会更具伸缩性。另外,urllib2 用到的应该是某种设计模式,记得的童鞋不忘留言告诉我。
捣乱 2013-08-25