系统工程师工具箱
遇到问题时的处理思路
- 评估故障重要性,紧急程度,适当的报告,如果需要,可寻求帮助;
- 及时处理故障,“糙、快、猛”,见效快,消除影响-治标;
- 故障善后要治本,聪明靠谱的人不会让故障发生第二次;
- 合理安排工作哦,保证处理问题的节奏感-好的反馈机制有利于解决问题;
- 故障是日常工作积累的集中反馈;
- 行胜于言,自己得到的数据分析比听到的重要;
如何判断系统的瓶颈或故障点
- 日常工作:监控是否到位,日志是否准确全面(提高故障定位率和定位速度);
- 必要的技术手段:cpu, disk io(iops or throughput), network(初步诊断);
- 熟悉自己负责的系统,逐步搞懂原理;
- “源码面前,了无秘密”,对非自己开发的程序要仔细评测后使用;
工具箱
- 首先解释下什么是load
在Linux系统中,uptime,top等命令都会有系统平均负载load average的输出,这里解释下究竟什么是系统平均负载。
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数,如果一个进程满足以下条件,则其位于运行队列中:
- 它没有在等待IO操作的结果;
- 它没有主动进入等待状态(如没有调用wait);
- 没有被停止;
阮一峰在其博客《理解Linux系统负荷》一文对load做了非常清晰形象的解释,推荐一看。
- vmstat
vmstat是一个查看虚拟内存使用状况的工具。在查看过Linux的负载信息后,我们应该优先使用vmstat。
在这里介绍一下虚拟内存的原理。在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
我们看一下vmstat的输出结果:
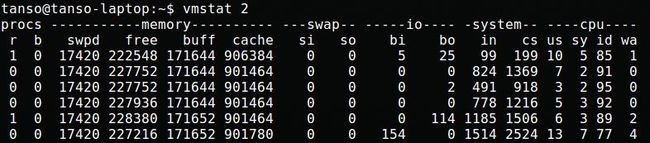
为了分析系统性能瓶颈,我们首先重点关注下r, b, si, so, bi, bo, wa字段。
r表示运行队列中的进程数量;b表示等待IO的进程数量。如果b长时间不为0,表示IO已成为系统瓶颈;
si, so分别表示每秒从交换区写入或写出内存的大小,较大表示有可能出现颠簸,系统内存不够,经常需要换入换出操作;
bi, bo表示每秒读取、写入的块数,用来衡量磁盘读写的情况;
wa表示CPU等待IO的时间,如果大于15,也说明存在IO问题。另外,注意在多核的场景下,使用top命令看到的wa是均值,可以top->1,查看时候有某个CPU的wa过高,这个CPU很可能已成为瓶颈。
- iostat
介绍下iostat里边的几个数据:
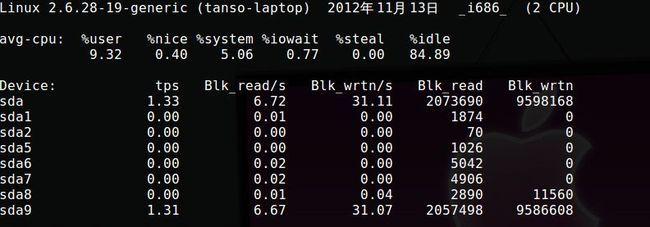
Blk_read/s和Blk_wrtn/s表示每秒从设备读取、写入的数据量,以Block为单位。Block的大小在kernel 2.4后均为512字节;
tps表示该设备每秒的传输次数。一次传输意味着一次IO请求,多个逻辑请求可能会被合并成一次IO请求,一次传输的请求大小是未知的。
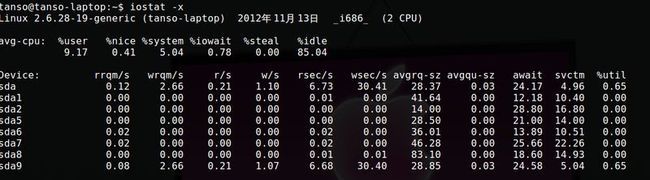
await表示每一个IO请求处理的平均时间(单位为毫秒)。可以理解为IO的响应时间,一般系统IO响应时间应低于5ms,如果大于10ms就比较大了。
%util,表示统计时间内所有处理IO的时间,除以总的统计时间。暗示了设备的繁忙程度。
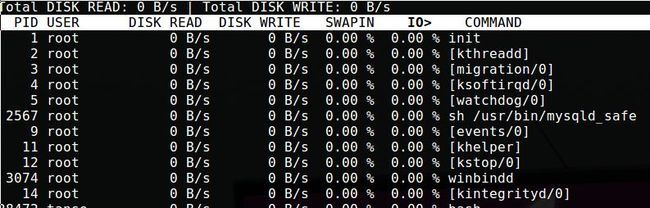
- iotop
接下来可以使用iotop,查看究竟是哪个进程在大量的读写磁盘。如下图所示:
- iftop
iftop是类似于top的实时流量检测工具。之前我都是用nload来看整个机器的流量情况,今天使用了下iftop,可以看到每个网络连接的流量情况,对于一个服务同时服务于多个连接的情况(这个太常见了),非常给力。
还有lsof,用来查看当前系统所有打开文件的状况,可以分析进程究竟被哪个文件锁住了;tcpdump(如果有图形界面,也可以用wireshark)用来抓包分析(tcp包或直接观察应用层协议);iptables,用来添加管理特定的连接策略等。
如上,介绍了常用的分析工具,文章最后,再给出一些常见的优化思路。
常见优化
- iostat发现磁盘IO瓶颈,考虑应用场景,碎片化IO是否可以缓存批量读写,需要频繁读入的文件可以考虑放入/dev/shm;
- 日志文件忘记分割,导致程序越来越慢;
- Swap过多,vmstat的si so经常不为0,表示内存不足;
- 网络调优,netstat -nat发现诸如TIME_WAIT过多,连接数不够用,连接数一直上不来,打开文件数过多等,通过修改/etc/sysctl.conf优化、该apache/nginx配置优化,修改TCP buffer,backlog等;
- 使用SSD,甚或优化文件系统;