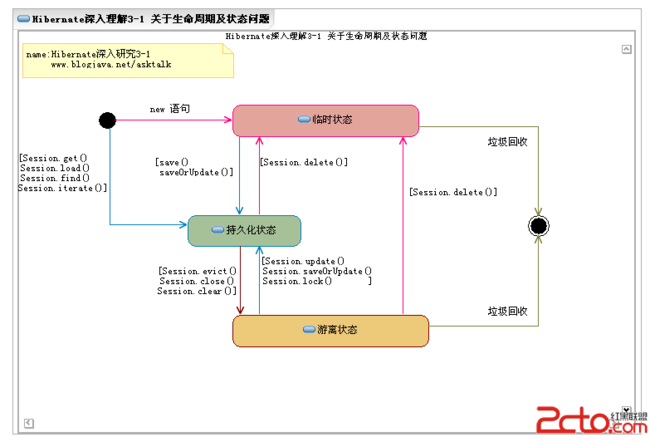
一、三种状态(Transient、Persistent、Detached)
在Hibernate中有三种状态,对它的深入理解,才能更好的理解hibernate的运行机理,刚开始不太注意这些概念,后来发现它是重要的。对于理解hibernate,JVM和sql的关系有更好的理解。对于需要持久化的JAVA对象,在它的生命周期中有三种状态,而且互相转化。
1, 临时状态(Transient):用new创建的对象,它没有持久化,没有处于Session中,处于此状态的对象叫临时对象;
2, 持久化状态(Persistent):已经持久化,加入到了Session缓存中。如通过hibernate语句保存的对象。处于此状态的对象叫持久对象;
3, 游离状态(Detached):持久化对象脱离了Session的对象。如Session缓存被清空的对象。
特点:已经持久化,但不在Session缓存中。处于此状态的对象叫游离对象;
×/√ 临时状态(Transient) 持久化状态(Persistent) 游离状态(Detached)
是否处于Session缓存中 × √ ×
数据库中是否有对应记录 × √ √
游离对象和临时对象异同:
两者都不会被Session关联,对象属性和数据库可能不一致;
游离对象有持久化对象关闭Session而转化而来,在内存中还有对象所以此时就变成游离状态了;
图是精华:
persist() is well defined. It makes a transient instance persistent. However,
it doesn't guarantee that the identifier value will be assigned to the persistent
instance immediately, the assignment might happen at flush time. The spec doesn't say
that, which is the problem I have with persist().
persist() also guarantees that it will not execute an INSERT statement if it is
called outside of transaction boundaries. This is useful in long-running conversations
with an extended Session/persistence context.A method like persist() is required.
save() does not guarantee the same, it returns an identifier, and if an INSERT
has to be executed to get the identifier (e.g. "identity" generator, not "sequence"),
this INSERT happens immediately, no matter if you are inside or outside of a transaction. This is not good in a long-running conversation with an extended Session/persistence context."
---------------------------------------------------------------------------------
简单翻译一下上边的句子的主要内容:
1,persist把一个瞬态的实例持久化,但是并"不保证"标识符被立刻填入到持久化实例中,标识符的填入可能被推迟到flush的时间。
2,persist"保证",当它在一个transaction外部被调用的时候并不触发一个Sql Insert,这个功能是很有用的,当我们通过继承Session/persistence context来封装一个长会话流程的时候,一个persist这样的函数是需要的。
3,save"不保证"第2条,它要返回标识符,所以它会立即执行Sql insert,不管是不是在transaction内部还是外部
2.4 saveOrUpdateCopy,merge和update区别
首先说明merge是用来代替saveOrUpdateCopy的,这个详细见文章最后(hibernate 3.2新的Session接口与之前接口的不同)
然后比较update和merge
update的作用上边说了,这里说一下merge的
如果session中存在相同持久化标识(identifier)的实例,用用户给出的对象的状态覆盖旧有的持久实例
如果session没有相应的持久实例,则尝试从数据库中加载,或创建新的持久化实例,最后返回该持久实例
用户给出的这个对象没有被关联到session上,它依旧是脱管的
重点是最后一句:
当我们使用update的时候,执行完成后,我们提供的对象A的状态变成持久化状态。
但当我们使用merge的时候,执行完成,我们提供的对象A还是脱管状态,hibernate或者new了一个B,或者检索到一个持久对象B,并把我们提供的对象A的所有的值拷贝到这个B,执行完成后B是持久状态,而我们提供的A还是托管状态。
3.5 flush和update区别
这两个的区别好理解
update操作的是在脱管状态的对象
而flush是操作的在持久状态的对象。
默认情况下,一个持久状态的对象是不需要update的,只要你更改了对象的值,等待hibernate flush就自动
保存到数据库了。hibernate flush发生再几种情况下:
1,调用某些查询的时候
2,transaction commit的时候
3,手动调用flush的时候
3.6 lock和update区别
update是把一个已经更改过的脱管状态的对象变成持久状态
lock是把一个没有更改过的脱管状态的对象变成持久状态
对应更改一个记录的内容,两个的操作不同:
update的操作步骤是:
(1)更改脱管的对象->调用update
lock的操作步骤是:
(2)调用lock把对象从脱管状态变成持久状态-->更改持久状态的对象的内容-->等待flush或者手动flush
附:hibernate 3.2新的Session接口与之前接口的不同
hibernate 3中的session接口的不同
hibernate3.2版本中session出现了2个
新session接口:org.hibernate.Session
老session接口:org.hibernate.classic.Session
顾名思义,classic包下的session就是以前常用的session,新的这个相比老的有很大变化。下边详细列出
1,去掉了所有的find方法
在新的session接口中没有find方法,而在老的session接口中把find全部注释成deprecated了。
2,去掉所有的saveOrUpdateCopy,使用merge代替,这是classic.Session注释中的一段原话.
/**
* Copy the state of the given object onto the persistent object with the same
* identifier. If there is no persistent instance currently associated with
* the session, it will be loaded. Return the persistent instance. If the
* given instance is unsaved or does not exist in the database, save it and
* return it as a newly persistent instance. Otherwise, the given instance
* does not become associated with the session.
*
* @deprecated use {@link org.hibernate.Session#merge(String, Object)}
*
* @param object a transient instance with state to be copied
* @return an updated persistent instance
*/
注意这句:@deprecated use {@link org.hibernate.Session#merge(String, Object)}
3,去掉了iterate方法
给出的注释是使用createQuery,自己获得iterate
4,去掉了filter方法
@deprecated use {@link #createFilter(Object, String)}.{@link Query#list}
给出的注释说用createFilter代替,实际就是自己从createFilter获得query然后自己查询
5,增加了一些方法
具体自己看api吧,主要是提供了一些新的功能。
总结:
从上边的改变不难看出hibernate对于接口的设定观念改变了。
以前的策略是:
尽量给出全的接口,这样减少用户的代码量,所以filter直接返回collection,iterate直接返回
iterate。但这样的结果是过度的提供接口,造成了学习上的负担和选择上的负担。如何记住这些函数,如何在众多函数中选择是个麻烦事情。
凡是做java的都知道,用一个java的东西最辛苦的是选择,在开源的世界里边选择一个适合自己的工程,再在这个选择的工程里边选择实现方法。
因为可能提供很多种实现方法,而且有些还是deprecated的。
现在的策略:
尽量简化接口,或减少函数,或者简化函数名,例如把saveOrUpdateCopy变成merge。
这样的好处是记忆学习负担少。多写几句代码不是特别麻烦。其实我个人来讲更喜欢现在的感觉。
以前的策略其实很大程度上是满足程序员的个人需求,更有成就感。但确不适合使用者的需求。