作为数据计算语言,集算器和R语言都提供了丰富的功能用来处理外存中的文本文件。两者在基本用法上有很多相似之处,但区别也很明显,比如处理列宽固定的文件、读写指定的列、处理大文本文件,计算性能等方面。下面详细对比两者的异同。
1、基本功能对比
描述:
sales.txt共有六列,列之间以制表符(\t)分割,行之间以换行符(\n)分割,其中第一行为列名。请将该文件读入内存,再原样写入新的文件。该文件的前几行如下:

集算器:
data=file("e:\\sales.txt").import@t()
file("e:\\salesResult.txt") .export@t(data)
R语言:
data<-read.table("e:\\sales.txt",sep="\t", header=TRUE)
write.table(data, file="e:\\ salesResult.txt", sep="\t", quote=FALSE, row.names=FALSE)
对比:
1、两者都可以方便地实现本功能,其中集算器需要用函数选项“@t”表示第一行为列名,而R语言使用“header=TURE”。
2、换行符是最常见的行分割符,集算器和R语言默认支持换行符。制表符是最常见的列分割符,集算器默认支持制表符,如需指定其他分割符(比如逗号)则应当写作“import@t(;”,”)”。R语言支持的默认列分隔符是“空格和制表符”,这会把含有空格的Client列错误地分为两列,因此需要用sep=”\t”来明确分割符只能是制表符。另外,代码中的“quote=FALSE, row.names=FALSE”表示和源文件一样,不用给元素加引号,也不用输出行号。
3、文件被读到内存后一般都以结构化二维数据对象来存储,这在集算器中被称为序表(TSeq),在R语言中被称为数据框(data.frame)。序表和数据框都支持丰富的计算功能,比如按Client和SellerId分组,分组后对Amount求和并求最大值。集算器实现该算法的代码是:
data.groups(Client,SellerId;sum(Amount),max(OrderID))
数据框不直接支持同时使用多种汇总方法,因此求和、求最大值要分为两步,最后再通过cbind拼合结果,如下:
result1<-aggregate(data[,4],data[c(2,3)],sum)
result2<-aggregate(data[,1],data[c(2,3)],max)
result<-cbind(result1,result2[,3])
4、除内存中的结构化二维数据对象外,集算器还能用游标对象来访问文件,R则能用矩阵对象来访问文件。
结论:对于基本的文件读写,集算器和序表都提供了足够丰富的函数功能,可以很好的满足需求。
2、读取列宽固定的文件
有些文件没有分隔符来区分不同的列,而是用固定的宽度来区分。比如,请将下面含有三列数据的static.txt文件读入内存,并将列名分别改为: col1、col2、col3。其中,col1宽度为1,col2宽度为4,col3宽度为3。

集算器:
data=file("e:\\static.txt").import()
data.new(mid(_1,1,1):col1, mid(_1,2,4):col2, mid(_1,6,8):col3)
R语言:
data<-read.fwf("e:\\sales.txt ", widths=c(1, 4, 3), col.names=c("col1","col2","col3"))
对比:R语言可以直接实现本功能。集算器只能间接实现,即将文件读入内存后再拆分成多个列。请注意:代码mid(_1,1,1)中的”_1”是默认列名,如果读入的文件有多个列,则默认列名依次是:_1、_2、_3等
结论:R语言能够直接读取列宽固定的文件,比集算器更方便。
3、读写指定的列
有时出于节省内存提高性能等目的,我们需要读取部分的列数据。本例需要将sales.txt中的ORDERID、CLIENT、AMOUNT这三列读入内存,并将ORDERID、AMOUNT写入新的文件。
集算器:
data=file("e:\\sales.txt").import@t(ORDERID,CLIENT,AMOUNT)
file("e:\\salesResult.txt") .export@t(data,ORDERID,AMOUNT)
语言:
data<-read.table("e:\\sales.txt",sep="\t", header=TRUE)
col3<-data[,c(“ORDERID”,”CLIENT”,”AMOUNT”)]
col2<-col3[,c(“ORDERID”,”AMOUNT”)]
write.table(col2, file="e:\\ salesResult.txt", sep="\t", quote=FALSE, row.names=FALSE)
对比:集算器可以直接实现本功能。R语言只能间接实现,即将所有的列全部读入内存,再将指定的列存入新的变量。
结论:R语言只能将所有的列全部读入内存,会占用较大的内存空间。
4、处理大文本文件
大文本文件是指超过内存空间的文件。读取大文本文件通常要采取分批读取分批计算的办法。比如这个例子:针对大文本文件sales.txt,过滤出Amount>2000的数据,并计算每个SellerId的Amount总额。
集算器:

A1:将大文件全部读入内存会导致内存溢出,因此用游标分批读入。
A2:循环读数,每次读入100000条,存储于序表A2。
B3:针对每批数据,过滤出订单金额在2000以上的记录。
B4:接着对过滤后的数据进行分组汇总,求得这个批次每个销售员的销售额。
B5:将本批次的计算结果追加到某个变量(B1)中,并进行下一批次的计算。
B6:所有批次都计算完后,B1中应该存储着每个销售员在每个批次中的销售额,所以最后还要进行一次分组汇总,从而求得每个销售员的总销售额。
R语言

1-4:建立空的数据框data,用来生成每批次的数据框databatch。
5-9:建立空的数据框agg,用来追加各批次分组汇总的结果。
11-13:按行读入文件,跳过第一行的列名,每次读入100000行。
15-21:针对每批数据,过滤出订单金额在2000以上的记录。
22:接着对过滤后的数据进行分组汇总,求得这个批次每个销售员的销售额。
23:将本批次的计算结果追加到某个变量(agg)中,并进行下一批次的计算。
24:所有批次都计算完后,B1中应该存储着每个销售员在每个批次中的销售额,所以最后还要进行一次分组汇总,从而求得每个销售员的总销售额。
对比
1、两者的算法思路一致,但集算器使用库函数就可以实现算法,代码简洁易懂,R语言则需要手工处理大量细节,代码繁杂冗长容易出错。
2、使用集算器游标,可以更简单地完成上述算法,即:
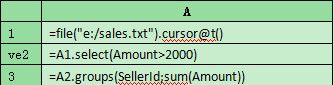
在这段代码中,集算器引擎会自动分批处理数据,程序员无需用循环语句手工控制。
结论:处理大文本文件时,集算器代码比R语言简洁易懂,方式更加灵活。
5、并行处理大文本文件
并行计算可以充分利用多核CPU的资源,会显著提高计算性能。
仍然使用上一节的例子来进行比较,但改为并行算法,即:将sales.txt分为4段,依次分给4个cpu核心计算,最终过滤出Amount>2000的数据,并计算每个SellerId的Amount总额。
集算器:
主程序(pro5.dfx)

A1:并行任务数设为4,即将文件分为4段。
A2:调用子程序进行多线程并行计算,任务参数有两个:to(A1)、A1。to(A1)的值是[1,2,3…24],这表示每个任务分配到的段数;A1是总段数。所有任务都结束后,计算结果会统一存储在本单元格。
A3:对A2中各任务的计算结果按照SellerId归并。
A4:对归并结果进行分组汇总,求得每个销售员的销售额。
子程序(sub.dfx)
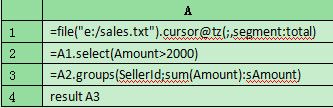
A1:用游标读取文件,按照主程序传来的参数决定当前任务应该处理文件中的第几段。比如第3个任务,segment参数的值就是3,total的值恒为4。
A2:选出订单金额在2000以上的记录。
A3:对过滤后的数据进行分组汇总。
A4:将本任务的计算结果返回主程序。
R语言:无法直接用并行算法实现本案例。
对比:集算器支持按照字节数分段读取大文本文件,可以快速跳过前面的无用数据而读取指定段,从底层起就支持多线程并行计算。
R语言虽然支持内存数据的并行计算,但不支持按字节数分段读取外存文件,只支持跳过若干行再读取数据。这种方式必须遍历无用数据,性能很低,无法在底层支持大文本文件的并行计算。
另外,按字节数分段会遇到半行数据的情况,而集算器已经对此进行了自动处理,如上述代码所示,程序员无需进行手工处理。
总结:集算器支持并行处理大文本文件,计算性能很高。R语言无法在底层支持大文本文件的并行计算,性能差得多。
6、计算性能
在同样的测试环境下,使用集算器和R语言读取字节数为1G的文件,并对其中一个字段进行汇总。
集算器:
=file("d:/T21.txt").cursor@p(#1:long)
=A1.groups(;sum(#1))
R语言
con <- file("d:/T21.txt", "r")
lines=readLines(con,n=1024)
value=0
while( length(lines) != 0) {
for(line in lines){
data<-strsplit(line,'\t')
value=value+as.numeric(data[[1]][1])
}
lines=readLines(con,n=1024)
}
print(value)
close(con)
对比:
1、集算器用时26秒,R语言耗时9分47秒,两者的差距超出了一个数量级。
2、对于大文件的处理,R语言无法使用数据框对象和库函数,只能手工书写循环语句边读边算,因此性能很低。集算器可以直接使用游标对象和库函数,因此性能较高。处理小文件时两者的区别不会有这么大。
总结:处理大文本文件时,集算器的性能大幅超过R语言。