Android 网页抓取(实现新闻客户端)
如何实现从各大网抓取新闻并经过格式处理现实到我们的新闻客户端呢?
Android客户端抓取并解析网页的方法我用到的有两种:
一、用jsoup
没仔细研究,网上有类似的,可以参考这两位兄弟的:
http://decentway.iteye.com/blog/1333127
http://blog.csdn.net/hellohaifei/article/details/9352069
二、用htmlparser
我项目中就用htmlparser,抓紧并解析腾讯新闻,代码如下:
附件为用到的jar包;
关于新闻完整的新闻客户端,有需要的哥们可以留下邮箱,完整实现了新闻的抓取:
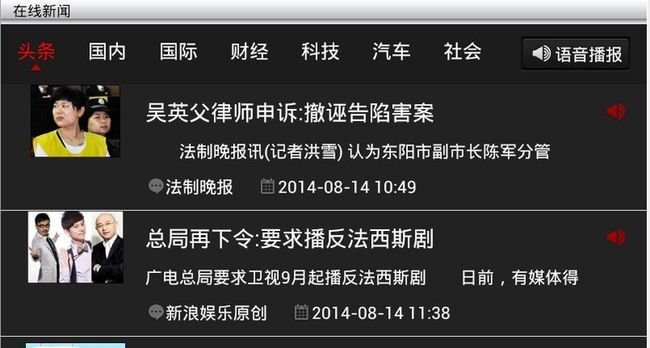
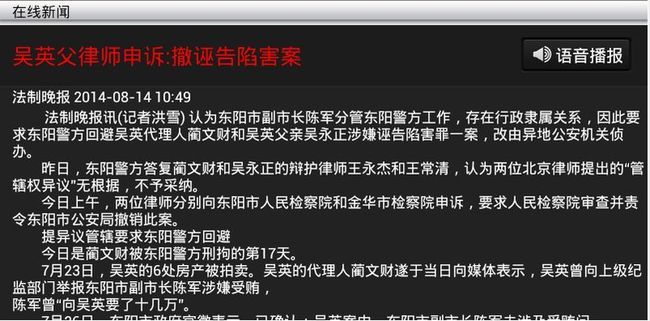
工程源码在:https://github.com/gqdy365/onlineNews
Android客户端抓取并解析网页的方法我用到的有两种:
一、用jsoup
没仔细研究,网上有类似的,可以参考这两位兄弟的:
http://decentway.iteye.com/blog/1333127
http://blog.csdn.net/hellohaifei/article/details/9352069
二、用htmlparser
我项目中就用htmlparser,抓紧并解析腾讯新闻,代码如下:
public class NetUtil {
public static List<NewsBrief> DATALIST = new ArrayList<NewsBrief>();
public static String[][] CHANNEL_URL = new String[][] {
new String[]{"http://news.qq.com/world_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/society_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
};
public static int getTechNews(List<NewsBrief> techData, int cId) {
int result = 0;
try {
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
try {
String textstr = node.getChildren().elementAt(j).toHtml();
if (textstr.trim().length() > 0) {
NodeFilter subFilter = new TagNameFilter("p");
Parser subParser = new Parser();
subParser.setResource(textstr);
NodeList subList = subParser.extractAllNodesThatMatch(subFilter);
NodeFilter titleStrFilter = new AndFilter(new TagNameFilter("a"),
new HasAttributeFilter("class", "linkto"));
Parser titleStrParser = new Parser();
titleStrParser.setResource(textstr);
NodeList titleStrList = titleStrParser.extractAllNodesThatMatch(titleStrFilter);
int linkstart = titleStrList.toHtml().indexOf("href=\"");
int linkend = titleStrList.toHtml().indexOf("\">");
int titleend = titleStrList.toHtml().indexOf("</a>");
String link = CHANNEL_URL[cId][1]+titleStrList.toHtml().substring(linkstart+6, linkend);
String title = titleStrList.toHtml().substring(linkend+2, titleend);
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
newsBrief.setSummary(subList.asString());
techData.add(newsBrief);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int getTechNews2(List<NewsBrief> techData, int cId) {
int result = 0;
try {
// 查询http://tech.qq.com/tech_yejie.htm 页面 滚动新闻的 标签 以及ID
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
// 获取匹配的fileter的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
StringBuilder NewsStr = new StringBuilder("<table>");// 新闻表格字符串
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
String textstr = node.getChildren().elementAt(j).toHtml()
.trim();
if (textstr.length() > 0) {
int linkbegin = 0, linkend = 0, titlebegin = 0, titleend = 0;
while (true) {
linkbegin = textstr.indexOf("href=", titleend);// 截取链接字符串起始位置
// 如果不存在 href了 也就结束了
if (linkbegin < 0)
break;
linkend = textstr.indexOf("\">", linkbegin);// 截取链接字符串结束位置
String sublink = textstr.substring(linkbegin + 6,linkend);
String link = CHANNEL_URL[cId][1] + sublink;
titlebegin = textstr.indexOf("\">", linkend);
titleend = textstr.indexOf("</a>", titlebegin);
String title = textstr.substring(titlebegin + 2,titleend);
NewsStr.append("\r\n<tr>\r\n\t<td><a target=\"_blank\" href=\""
+ link + "\">");
NewsStr.append(title);
NewsStr.append("</a></td></tr>");
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
techData.add(newsBrief);
}
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int parserURL(String url,NewsBrief newsBrief) {
int result = 0;
try {
Parser parser = new Parser(url);
NodeFilter contentFilter = new AndFilter(
new TagNameFilter("div"),
new HasAttributeFilter("id","Cnt-Main-Article-QQ"));
NodeFilter newsdateFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"article-time"));
NodeFilter newsauthorFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"color-a-1"));
NodeFilter imgUrlFilter = new TagNameFilter("IMG");
newsBrief.setContent(parserContent(contentFilter,parser));
parser.reset(); // 记得每次用完parser后,要重置一次parser。要不然就得不到我们想要的内容了。
newsBrief.setPubDate(parserDate(newsdateFilter,parser));
parser.reset();
newsBrief.setSource(parserAuthor(newsauthorFilter, parser));
parser.reset();
newsBrief.setImgUrl(parserImgUrl(contentFilter,imgUrlFilter, parser));
} catch (Exception e) {
result=1;
e.printStackTrace();
}
return result;
}
private static String parserContent(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList contentList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = contentList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserDate(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList datetList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = datetList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserAuthor(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList authorList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = authorList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static List<String> parserImgUrl(NodeFilter bodyfilter,NodeFilter filter, Parser parser) {
List<String> reslut = new ArrayList<String>();
try {
NodeList bodyList = (NodeList) parser.parse(bodyfilter);
Parser imgParser = new Parser();
imgParser.setResource(bodyList.toHtml());
NodeList imgList = imgParser.extractAllNodesThatMatch(filter);
String bodyString = imgList.toHtml();
//正文包含图片
if (bodyString.contains("<IMG")
&& bodyString.contains("src=")) {
if(imgList.size()>0){
for(int i=0;i<imgList.size();i++){
String imgString = imgList.elementAt(i).toHtml();
int imglinkstart = imgString.indexOf("src=\"");
int imglinkend = imgString.indexOf(">");
if(imgString.contains("\" alt=")){
imglinkend = imgString.indexOf("\" alt=");
}
if(imgString.contains("_fck")){
imglinkend = imgString.indexOf("_fck");// 截取链接字符串结束位置
}
reslut.add(imgString.substring(imglinkstart + 5, imglinkend));
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
}
附件为用到的jar包;
关于新闻完整的新闻客户端,有需要的哥们可以留下邮箱,完整实现了新闻的抓取:
工程源码在:https://github.com/gqdy365/onlineNews