在redis之字符串命令源码解析(一)中讲了get的简单实现,并没有对如何取到数据做深入分析,这里将深入。
1、redisObject 数据结构,以及Redis 的数据类型
/* The actual Redis Object */
/*
* Redis 对象
*/
#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1) /* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
// 类型,冒号后面跟数字,表示包含的位数,这样更节省内存
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
<span style="color:#ff0000;">// 指向实际值的指针,指向上节的sdshdr->buf,而不是sdshdr,这还要归因于sds.c中的方法sdsnewlen返回的buf部分,而不是整个sdshdr</span>
void *ptr;
} robj;
#define REDIS_STRING 0 // 字符串
#define REDIS_LIST 1 // 列表
#define REDIS_ZSET 3 // 有序集
#define REDIS_HASH 4 // 哈希表
#define REDIS_ENCODING_RAW 0 // 编码为字符串
#define REDIS_ENCODING_INT 1 // 编码为整数
#define REDIS_ENCODING_HT 2 // 编码为哈希表
#define REDIS_ENCODING_ZIPMAP 3 // 编码为zipmap
#define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表
#define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表
#define REDIS_ENCODING_INTSET 6 // 编码为整数集合
#define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表
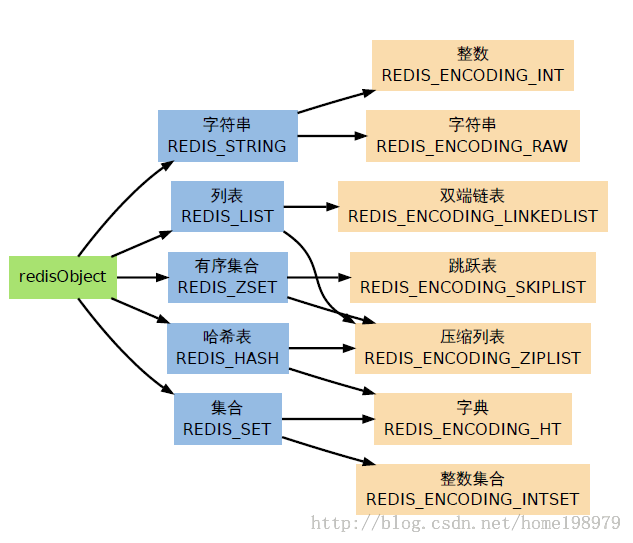
2、内部数据结构之dict(俗称字典)
1.1 dict结构
dict.h中定义如下:
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
哈希表dictht的结构:
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
哈希表数组dictEntry的结构:
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
那么一个dict可以图解表示为:
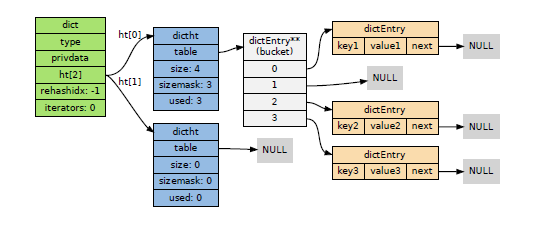
由图可清晰地看出redis字典哈希表所使用的哈希碰撞解决方法是链地址法,这个方法就是使用链表将多个哈希值相同的节点串连在一起,从而解决冲突问题。
1.2 dict实现setCommand
set命令最终会调用dict.c中的dictAdd方法将test => "hello redis" 保存到字典中
/* Add an element to the target hash table */
/*
* 尝试将给定键值对添加到字典中
*
* 只有给定键 key 不存在于字典时,添加操作才会成功
*
* 添加成功返回 DICT_OK ,失败返回 DICT_ERR
*
* 最坏 T = O(N) ,平滩 O(1)
*/
int dictAdd(dict *d, void *key, void *val)
{
// 尝试添加键到字典,并返回包含了这个键的新哈希节点
// T = O(N)
dictEntry *entry = dictAddRaw(d,key);
// 键已存在,添加失败
if (!entry) return DICT_ERR;
// 键不存在,设置节点的值
// T = O(1)
dictSetVal(d, entry, val);
// 添加成功
return DICT_OK;
}
整个set可简略如下图(此图省去了许多其它操作):
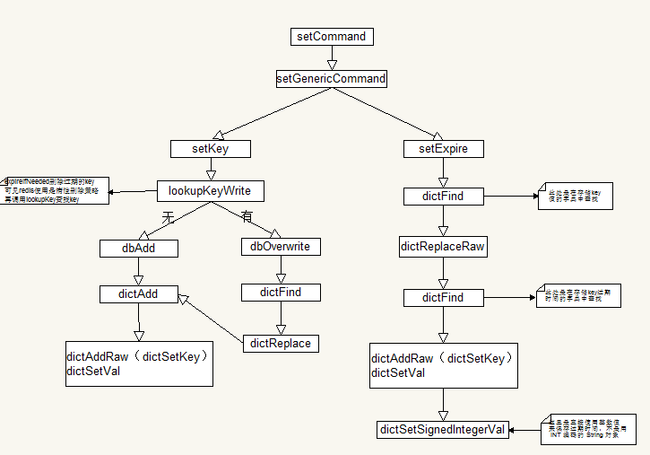
从图中你会发现,其实key的过期时间就相当于是key的另一个val,保存在另一个dict中,简单地说就是有两个dict,一个是key=>value,一个是key=>expire。
1.3 dict哈希表的rehash
dict有两个ht,就是每个字典有两个哈希表,为毛要有两个,其作用是对dict进行扩容和收缩,因为如果节点数量比哈希表的大小要大很多的话,那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在。
dict.c中的_dictExpandIfNeeded方法对哈希表何时可rehash作了判断:
// 一下两个条件之一为真时,对字典进行扩展
// 1)字典已使用节点数和字典大小之间的比率接近 1:1
// 并且 dict_can_resize 为真
// 2)已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio(默认值为5)
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 新哈希表的大小至少是目前已使用节点数的两倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
<span style="white-space:pre"> </span>//dictExpand的过程就是获取ht[0]的size,然后copy到ht[1]中,就是table大小是目录使用节点数的两倍。最后再将rehashidx设为0,标识着可以进行rehash了
}
rehash的代码这里不贴出,因为实现简单,大致的过程是
1. 释放ht[0] 的空间;
2. 用ht[1] 来代替ht[0] ,使原来的ht[1] 成为新的ht[0] ;
3. 创建一个新的空哈希表,并将它设置为ht[1] ;
4. 将字典的rehashidx 属性设置为-1 ,标识rehash 已停止;
但我在看源代码时,发现并不是一将rehashidx设为0就进行rehash操作的,而是当再次dictAdd时,才dictRehash(d,1),第二个参数是1,也就是说每次rehash只会对单个索引上的节点进行迁移,这种做法几乎不会消耗什么时间,客户端可以快速的得到响应。当然这种除了这种方式进行rehash外,Redis还有个定时任务调用dictRehashMilliseconds方法,在规定的时间内,尽可能地对数据库字典中那些需要rehash的字典进行rehash,从而加速rehash的进程。
现在我知道Redis并不是一下子就rehash完成,而是需要一定时间的,那么如果客户端在这段时间内向Redis发送get set del请求,那Redis会如何处理,从而保证数据的完整和正确呢?
• 因为在rehash 时,字典会同时使用两个哈希表,所以在这期间的所有查找、删除等操作,除了在ht[0] 上进行,还需要在ht[1] 上进行。
• 在执行添加操作时,新的节点会直接添加到ht[1] 而不是ht[0] ,这样保证ht[0] 的节点数量在整个rehash 过程中都只减不增。