自己写的一个开源爬虫框架,取名为Slit。现在的爬虫框架确实有很多,例如Nutch,Heritrix,webMagic等等我为什么又要自己写一个呢?这几个爬虫框架确实都不错,网上也有很多关于它们的评价,但是我发现它们中有很多功能我用不到,有些地方扩展性有点限制,然后自己一想搞个适合自己的轻框架,于是准备这个练手的项目Slit。
下面我对Slit项目做一些基本的介绍,包括项目的架构,内部运行逻辑,特点,怎么使用,和传统爬从比较等等。
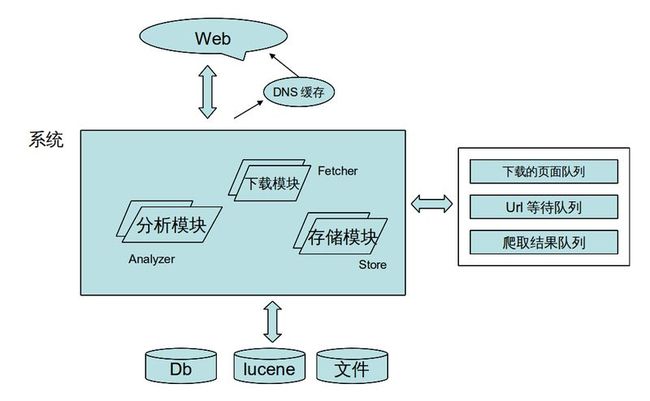
1, Slit 的模块介绍
2, Slit 内部运行逻辑
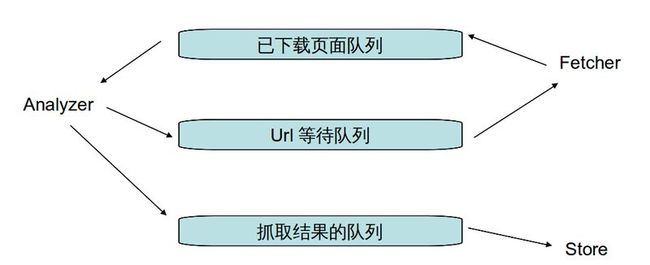
2.1,Fetcher模块,主要负责从url等待队列头取url,然后去下载页面,把整个页面结果放入已经下载页面队列。
2.2,Analyzer模块,主要负责从已经下载页面,提取想要的结果,放入抓取结果队列,另外再找出本页面上的其他连接,放入url等待队列。
2.3,Store模块,主要负责从抓取的结果队列中取出结果,然后根据用户自定义来怎么处理这些结果。
3,Slit的使用
3.1,定义一个类来继承AbstractNodeFilter,需要实现方法accept(),此方法用来提取页面上的节点。不同的用户可能想提取的结果都不同,这里的提取内容开放给用户自己定义。
3.2,定义一个类来继承AbstractFileStore,需要实现方法processResultNode(),此方法就是对抓取结果的处理。
3.3,启动Slit项目,
Config config = new Config();
// 需要爬取的url列表
config.setStartUrlList(Arrays.asList(“https://git.oschina.net/explore/recommend”));
config.setNodeFilterClass(MyNodeFilter.class); // 步骤一中自定义的类
config.setFileStoreClass(MyFileStore.class); // 步骤二中自定义的类
InitSlit slit = new InitSlit(config);
slit.start(); // 启动, 可以设置不同模块线程数,详见类config
4,Slit的使用(带浏览器)
4.1,定义一个类来继承AbstractNodeFilter,需要实现方法accept(),此方法用来提取页面上的节点。不同的用户可能想提取的结果都不同,这里的提取内容开放给用户自己定义。
4.2,定义一个类来继承AbstractFileStore,需要实现方法processResultNode(),此方法就是对抓取结果的处理。
4.3,定义一个类来继承AbstractBrowserAction,需要实现方法userBrowserAction(),此方法是定义浏览器爬取行为的。
4.4,使用chrome浏览器,下载chrome对应系统的webDriver驱动文件。(下载地址:http://chromedriver.storage.googleapis.com/index.html)
4.5, 启动Slit项目,
Config config = new Config();
config.setNodeFilterClass(MyBrowserNodeFilter.class); // 步骤一中定义的类
config.setFileStoreClass(MyBrowserFileStore.class); // 步骤二中定义的类
config.setInBrowser(true); // 设置浏览器为true
config.setBrowserAction(MyBrowserAction.class); // 步骤三中定义的类
config.setBrowserDriverPath(“/”); // chrome对应系统的webDriver文件的路径
InitSlit init = new InitSlit(config);
init.start();
5,Slit的特点
5.1,较好的扩展性,不同模块之间解耦合,非常适合二次开发自己的爬虫框架。
5.2,使用上配置简单,容易上手,可配置是否带浏览器模拟真实抓取,项目非常轻。
5.3, 可配置多线程,定义爬取深度,自动过滤重复url。
5.4,相比较传统爬虫,Slit能够解决动态页面(包含ajax局部页面),cookie信息,登录等问题。
6, Slit使用到的技术
6.1,Slit主要依赖两个jar包,“org.htmlparser:htmlparser:2.1“ 和”org.seleniumhq.selenium:selenium-java:2.45.0“ ,其他还包含一些log日志包等。
6.2,不同模块之间通过线程安全非阻塞队列协同工作。
7, Slit的demo演示 和 源码下载
项目分包结构图如下,其中test包中有两个demo的例子,分别是不带浏览器和带浏览器爬虫的例子。依赖的jar包在src/test/lib下面都可以找到。代码在github上地址是:https://github.com/DonFF/Slit,开源中国上的地址是:https://git.oschina.net/qifeifei/Slit,另外附件我也上传了源代码和说明文档。

更多的讨论可加入群共同学习,群号:213109134