Parallel query, the essence of the “divide and conquer” technique in query processing, has been part of Oracle Database for quite a while. In general, parallel query works by creating several parallel query processes that divide the workload of a SQL statement. These processes operate on objects in parallel and can therefore greatly reduce overall execution time. A coordinator session gets the output from each slave session and collates it to produce a combined output. The end result is the same as if the statement were processed serially, but it usually completes much more quickly.
The degree of parallelism , or the number of parallel processes used, depends on several factors. They include the default parallel degree of the table (set by the DBA) and the hints used in the statement by the user. The key to optimizing parallel query comes not just from understanding how it works but also in setting the optimal degree of parallelism for a given statement.
Simply setting a default degree of parallelism for a table may work in some cases. Note that whereas the default setting influences the actual degree of parallelism used for a query, other factors—such as system capabilities—also have an effect on the actual setting used. How do you choose the best default degree of parallelism? For some statements, the default degree may be too small, producing a suboptimal result due to a dearth of parallel processes. Yet it may be too large for other statements, causing the overparallelized queries to underperform. And sometimes a serial statement finishes faster than the parallelized version.
The parallel_max_servers initialization parameter defines the absolute maximum number of parallel processes that run on the system. If this value is too high, queries may perform poorly and the system may overallocate parallel processes from the total pool, forcing other queries to get fewer parallel processes than they actually need. You can also rely on hints to set the degree of parallelism, but these can be hard to set correctly.
So, although an optimal degree of parallelism is extremely important for ensuring good performance, there has been very little you could do to ensure the best setting. The most effective determination typically depended on your knowledge of the data pattern, the usage statistics, the load on the database, and a slew of other metrics—along with a healthy dose of luck. And there was no one-size-fits-all value; you needed to set it carefully for each statement. Needless to say, all that work was too much to expect from a typically overworked DBA. Furthermore, when working with packaged applications, you couldn’t even change the code to add hints that modified parallel behavior.
Enter Oracle Database 11g Release 2, with a new feature that makes it much easier to manage setting the degree of parallelism for your queries. Using this feature, you can delegate the task of determining the exact number of parallel query processes to the optimizer, which can compute the most effective degree of parallelism for a specific SQL statement. In this article, you will learn how to enable and use this feature to make the most of parallel queries.
Parallel Query Options
Consider the following query, based on the SALES table that comes as part of the Oracle SH sample schema:
explain plan for select sum(amount_sold) from sales where time_id between '1-JAN-01' and '31-DEC-10';
The explain plan command in the first line directs the database not to actually execute the query but to produce the execution plan only. You can check the execution plan by issuing this SQL statement:
select * from
table(dbms_xplan.display());
The output in Listing 1 shows the execution plan of the query. Note that there is no mention of PX-type operations in the Operation column. The absence of these operations indicates that the statement will run serially and not in parallel.
Code Listing 1: Execution plan for a query on a table without a default degree of parallelism*
-----------------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes|Cost |Time |Pstart|Pstop|
-----------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1| 13| 1387|00:00:17| | |
| 1| SORT AGGREGATE | | 1| 13| | | | |
|*2| FILTER | | | | | | | |
| 3| PARTITION RANGE ITERATOR| |229K|2916K| 1387|00:00:17| KEY | KEY|
|*4| TABLE ACCESS FULL |SALES|229K|2916K| 1387|00:00:17| KEY | KEY|
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
----------------------------------------------
2 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
4 - filter("TIME_ID">='1-JAN-01' AND "TIME_ID"<='31-DEC-10'))
Prior to Oracle Database 11g Release 2, the statement’s degree of parallelism was set according to the default parallel degree of the table. The following example shows how you can set the default parallel degree of the SALES table to 4.
SQL> alter table sales parallel 4; Table altered.
You can check the default parallel degree of the SALES table by using the following query:
SQL> select degree
2 from user_tables
3 where table_name = 'SALES';
DEGREE
--------
4
You can see how increasing the default parallel degree of the table affects the execution plan of the initial query:
explain plan for select sum(amount_sold) from sales where time_id between '1-JAN-01' and '31-DEC-10'; select * from table(dbms_xplan.display());
The output is shown in Listing 2. Note that the statement executed in parallel, as evidenced by the PX operations (shown in bold) in the Operation column.
Code Listing 2: Execution plan for a query on a table with a default degree of parallelism*
---------------------------------------------------------------------------
|Id | Operation | Name |Rows|Bytes| TQ |IN-OUT |PQ Distrib|
---------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1 | 13| | | |
| 1| SORT AGGREGATE | | 1 | 13| | | |
|*2| PX COORDINATOR | | | | | | |
| 3| PX SEND QC (RANDOM) |:TQ10000| 1 | 13|Q1,00| P->S|QC (RAND) |
| 4| SORT AGGREGATE | | 1 | 13|Q1,00| PCWP | |
|*5| FILTER | | | |Q1,00| PCWC | |
| 6| PX BLOCK ITERATOR | |229K|2916K|Q1,00| PCWC | |
|*7| TABLE ACCESS FULL| SALES |229K|2916K|Q1,00| PCWP | |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
----------
2 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
5 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
7 - filter("TIME_ID">='1-JAN-01' AND "TIME_ID"<='31-DEC-10')
Suppose a table does not have a default degree of parallelism. In that case, you can still force the query to perform a parallel operation by using a hint, quite appropriately named “parallel.” To experience how it works, first remove the default degree of parallelism from the SALES table.
SQL> alter table sales noparallel; Table altered.
If you now execute the same SELECT query shown earlier, you will get a serial execution plan as shown in Listing 1. To force the query to execute in parallel, place the parallel hint as shown below:
explain plan for select /*+ parallel */ sum(amount_sold) from sales where time_id between '1-JAN-01' and '31-DEC-10';
The execution plan is shown in Listing 3. Carefully study the plan: at the very end a Note section (shown in bold) clearly shows that the “automatic DOP” feature was set and the degree of parallelism was set to 2. This is another enhancement in Oracle Database 11g Release 2: the execution plan now shows the degree of parallelism used in the query.
Code Listing 3: Execution plan for a query with parallel hint*
----------------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes| TQ |IN-OUT | PQ Distrib|
----------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1| 13| | | |
| 1| SORT AGGREGATE | | 1| 13| | | |
|*2| PX COORDINATOR | | | | | | |
| 3| PX SEND QC (RANDOM) |:TQ10000| 1| 13|Q1,00| P->S| QC (RAND) |
| 4| SORT AGGREGATE | | 1| 13|Q1,00| PCWP | |
|*5| FILTER | | | |Q1,00| PCWC | |
| 6| PX BLOCK ITERATOR | |229K|2916K|Q1,00| PCWC | |
|*7| TABLE ACCESS FULL|SALES |229K|2916K|Q1,00| PCWP | |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
----------
2 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
5 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
7 - filter("TIME_ID">='1-JAN-01' AND "TIME_ID"<='31-DEC-10')
Note
------
- automatic DOP: Computed Degree of Parallelism is 2
The execution plan output in Listing 3 shows the computed degree of parallelism—the degree of parallelism the optimizer calculated for this specific query. In this case, it was 2, a value deemed to be optimal. The value chosen is influenced by an initialization parameter, parallel_degree_policy, which is set to LIMITED in this example. When using this setting, the optimizer computes the optimal degree-of-parallelism value based on estimated execution statistics. For a different statement, the value could be lower or higher.
Another value for the parallel_degree_policy parameter is MANUAL, which makes the optimizer behave as it did prior to Oracle Database 11g Release 2. In this case, the degree of parallelism is strictly determined by the table’s parallel degree, and the optimizer does not use the automatic degree of parallelism to find the best degree of parallelism for a particular statement. Note that the default setting for this parameter is MANUAL. To take advantage of the new automatic parallel query in Oracle Database 11g Release 2, change the setting to LIMITED or AUTO.
Limiting Parallel Processes
If a query requires parallel processes for optimal execution but no processes are free, query performance will suffer. So you may want to ensure that statements requiring many parallel processes are the ones that receive the most performance benefit. Another initialization parameter—parallel_degree_limit—sets the maximum degree of parallelism for a query. The default value of this parameter is CPU (calculated as the number of CPUs multiplied by the parallel threads allowed per CPU). This parameter can take other values, such as IO (in which the limit depends on the I/O load on the database host) or any number greater than 0. If you want, you can increase the limit to a numerical value, such as 30, systemwide by issuing
alter system set parallel_degree_limit = 30;
Or, to alter the value in a specific session only,
alter session set parallel_degree_limit = 30;
Note that even if you increase the parameter value, the automatically computed degree of parallelism may not increase, because the database may determine that the computed degree of parallelism is sufficient.
In most cases, the computed degree of parallelism will be quite accurate, but sometimes you may know the data well enough to justify a higher degree of parallelism. When that happens, how can you take advantage of more parallel query processes if they are available? You can force a higher degree of parallelism, such as 40, by specifying a hint:
explain plan for select /*+ parallel (t,40) */ sum(amount_sold) from sales t where time_id between '1-JAN-01' and '31-DEC-10';
When you examine the execution plan for the above statement (shown in Listing 4), notice that the note at the end of the plan states that the computed degree of parallelism was 30, even though the hint specified 40. The reason for the reduced number is the parallel_degree_limit initialization parameter, which we set to 30 earlier.
Code Listing 4: Execution plan for a query with a degree-of-parallelism hint*
----------------------------------------------------------------------------
|Id|Operation |Name |Rows|Bytes | TQ |IN-OUT |PQ Distrib|
----------------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1| 13 | | | |
| 1| SORT AGGREGATE | | 1| 13 | | | |
|*2| PX COORDINATOR | | | | | | |
| 3| PX SEND QC (RANDOM) |:TQ10000| 1| 13 |Q1,00| P->S|QC (RAND) |
| 4| SORT AGGREGATE | | 1| 13 |Q1,00| PCWP | |
|*5| FILTER | | | |Q1,00| PCWC | |
| 6| PX BLOCK ITERATOR | |229K| 2916K|Q1,00| PCWC | |
|*7| TABLE ACCESS FULL|SALES |229K| 2916K|Q1,00| PCWP | |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
----------
2 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
5 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
7 - filter("TIME_ID">='1-JAN-01' AND "TIME_ID"<='31-DEC-10')
Note
------
- automatic DOP: Computed Degree of Parallelism is 30 because of degree limit
The other parameter that affects the computed degree of parallelism is _parallel_threads_per_cpu, which is currently set to 30, with the CPU count for this server set to 1. This parameter limits the number of parallel query processes per CPU. Without this restriction, the number of parallel query processes could skyrocket, but they would just queue on the same CPU, making them serially executed. Note that this parameter starts with an underscore (_), meaning that this is considered hidden. In the prior releases of Oracle Database, this parameter was not hidden and was known as parallel_threads_per_cpu.
Does Parallel Query Help?
When a user issues a query against a large table, does it make sense to parallelize the query automatically? It depends. Parallelizing a query against a table requires additional work: the parallel query coordinator must divide the work among the slaves, coordinate their efforts, and finally collate the results. This additional work may actually make the overall execution take longer than running the query serially. Therefore, the database always performs a check by comparing the estimated execution time of a serial process with a parallel one. If the estimated elapsed time of a query with parallel query is higher than a certain threshold value, the query will be executed in parallel. This threshold value is specified by a parallel_min_time_threshold initialization parameter, and the default is 10 seconds. Note that you can also specify AUTO as the value for this parameter, in which case the system calculates the threshold.
When a query is first parsed, the database generates a plan that uses no parallelism and estimates the execution time. If the execution time is more than this threshold value time, it generates a parallel plan. Figure 1 shows the logic the optimizer uses to decide the plan of action. You can change the value of the parallel_min_time_threshold parameter in a session and see the effect, as shown in Listing 5. Look at the boldface note at the end of the plan, which shows the computed degree of parallelism to be 1 (meaning that no parallelism was used) because the execution time (15 seconds) was less than the threshold (16 seconds).
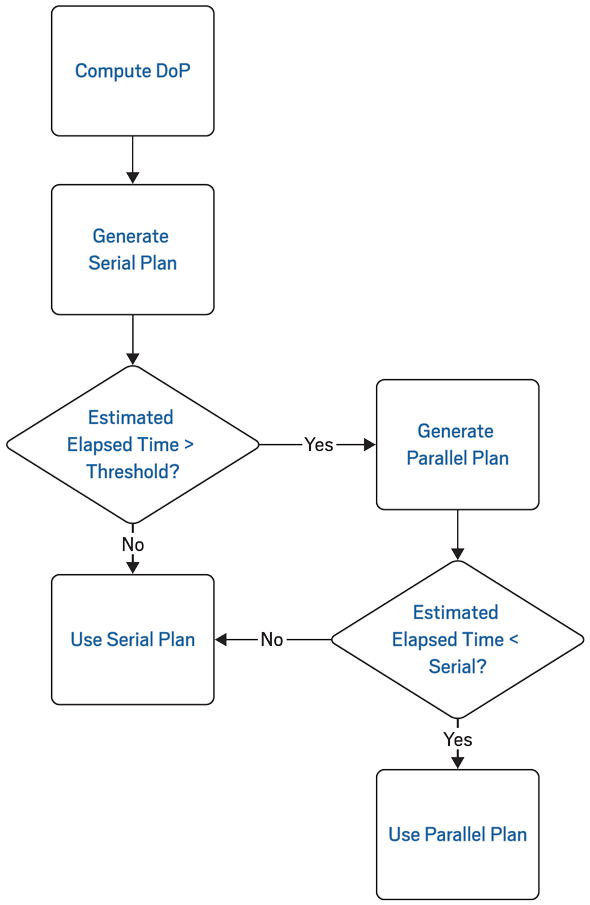 |
| Figure 1: Decision tree for query parallelization |
Code Listing 5: Specifying the threshold of parallel query
SQL> alter session set parallel_min_time_threshold = 16;
Session altered.
SQL> explain plan for
2 select /*+ parallel */ sum(amount_sold)
3 from sales t
4 where time_id between '1-JAN-01' and '31-DEC-10';
PLAN_TABLE_OUTPUT
-----------------------------------
Plan hash value: 2410956116
--------------------------------------------------------------------
| Id|Operation |Name |Rows |Bytes |Cost (%CPU)|Time |
--------------------------------------------------------------------
| 0|SELECT STATEMENT | | 1 | 13 | 1248 (2)|00:00:15|
| 1| SORT AGGREGATE | | 1 | 13 | | |
|* 2| FILTER | | | | | |
|* 3| TABLE ACCESS FULL|SALES | 229K| 2916K| 1248 (2)|00:00:15|
--------------------------------------------------------------------
Predicate Information (identified by operation id):
----------
2 - filter(TO_DATE('1-JAN-01')<=TO_DATE('31-DEC-10'))
3 - filter("TIME_ID">='1-JAN-01' AND "TIME_ID"<='31-DEC-10')
Note
------
- automatic DOP: Computed Degree of Parallelism is 1 because of parallel threshold
Parallel Query Limited to One Node of Oracle Real Application Clusters
When a query is issued against an Oracle Real Application Clusters (Oracle RAC) database with multiple nodes, the parallel processes may be spawned on different nodes. This approach is used to ensure that no one node becomes overloaded and that the processing power of all nodes is utilized as efficiently as possible.
However, under certain conditions, the interinstance traffic in the Oracle RAC database may already be significantly high. As the parallel processes on different nodes send their result sets via the interconnect, there is a strong possibility that this added traffic will introduce performance issues, especially related to global cache metrics. In such cases, you may want to restrict the parallel processes to the node where the parallel query coordinator runs. Because all the components of the query—the coordinator and the parallel processes—are in the same instance, there is no interinstance traffic and hence there are no global-cache-related issues.
The parallel_force_local parameter restricts parallel processes to a single instance. The default value is FALSE, meaning that the parallel processes can go into any available instance. To restrict the parallel processes to a single instance, set the parallel_force_local parameter value to TRUE.
Queuing
What happens when the parallel query processes required for optimal execution are not available? Should the optimizer reduce the degree of parallelism, remove it altogether to make it serial, or just abort the process? It does none of the above. Instead, Oracle Database 11g Release 2 now defers the execution of the query until the parallel query processes are available to satisfy the desired degree of parallelism. This is done transparently without any user intervention. The queuing mechanism ensures that all statements will run with the appropriate degree of parallelism. If the database did not use the queuing mechanism and instead simply allowed the parallel processes to kick off, they would be queued at the CPU level with a deeper run queue, causing performance issues. Conversely, if the database started statement execution with a reduced degree of parallelism, the statement would perform less efficiently than it would if it waited a little longer to get the desired degree of parallelism. The queuing process eliminates those risks.
The first statement in the queue will wait with a special event:
PX Queueing: statement queue.
The subsequent statements will wait with the event:
enq: JX - SQL statement queue.
Conclusion
Setting a query’s degree of parallelism is not an exact science. It’s fraught with many potential errors and depends heavily on the user’s knowledge of data distribution and on manual intervention that may not be possible. Automatic parallel query features in Oracle Database 11g Release 2 alleviate this issue by shifting the burden of determining the degree of parallelism from the users or DBAs to the optimizer. The optimizer is designed to make an effective determination of the optimal parallel settings for any given statement, not just for a table or index. And all you have to do to take advantage of this feature is set the parallel_degree_policy parameter to AUTO. Table 1 summarizes the main objectives you may have when configuring parallel query, along with the parameters that enable those objectives.
| Objective | Parameter | Allowed Values (Default is underlined.) |
| To enable the automatic degree of parallelism | parallel_degree_policy | manual, limited, auto |
| To limit the automatic degree of parallelism for a single query | parallel_degree_limit | cpu, io, auto, number |
| To specify the threshold for determining serial versus parallel query | parallel_min_time_threshold | auto, number |
| To force parallel query processes to one instance | parallel_force_local | true, false |
Table 1: Objectives of parallel query and parameters that meet those
参考至:http://www.oracle.com/technetwork/issue-archive/2010/o40parallel-092275.html
如有错误,欢迎指正