TermRangeQuery是用于字符串范围查询的,既然涉及到范围必然需要字符串比较大小,字符串比较大小其实比较的是ASC码值,即ASC码范围查询。一般对于英文来说,进行ASC码范围查询还有那么一点意义,中文汉字进行ASC码值比较没什么太大意义,所以这个TermRangeQuery了解就行,用途不太大,一般数字范围查询NumericRangeQuery用的比较多一点,比如价格,年龄,金额,数量等等都涉及到数字,数字范围查询需求也很普遍。
我们来看看官方API里是怎么解释这个Query的:
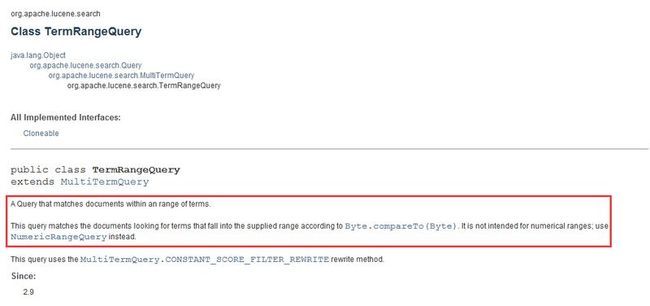
意思就是这个Query通过一个范围内的Term来匹配索引文档,这个Query通过一组Term来查找索引文档,哪些Term呢?that后面是解释根据比较byte值落入提供的范围内的Term.但这个Query不适用于数字范围查询,数字范围查询请使用NumericRangeQuery代替。
下面是TermRangeQuery的使用示例:
package com.yida.framework.lucene5.query;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
public class TermRangeQueryTest {
public static void main(String[] args) throws ParseException, IOException {
//参数定义
String directoryPath = "D:/lucenedir";
String fieldName = "contents";
String lowerTermString = "fa";
String upperTermString = "fi";
Query query = new TermRangeQuery(fieldName,
new BytesRef(lowerTermString),
new BytesRef(upperTermString), false, false);
List<Document> list = query(directoryPath,query);
if(list == null || list.size() == 0) {
System.out.println("No results found.");
return;
}
for(Document doc : list) {
String path = doc.get("path");
String content = doc.get("contents");
System.out.println("path:" + path);
//System.out.println("contents:" + content);
}
}
/**
* 创建索引阅读器
* @param directoryPath 索引目录
* @return
* @throws IOException 可能会抛出IO异常
*/
public static IndexReader createIndexReader(String directoryPath) throws IOException {
return DirectoryReader.open(FSDirectory.open(Paths.get(directoryPath, new String[0])));
}
/**
* 创建索引查询器
* @param directoryPath 索引目录
* @return
* @throws IOException
*/
public static IndexSearcher createIndexSearcher(String directoryPath) throws IOException {
return new IndexSearcher(createIndexReader(directoryPath));
}
/**
* 创建索引查询器
* @param reader
* @return
*/
public static IndexSearcher createIndexSearcher(IndexReader reader) {
return new IndexSearcher(reader);
}
public static List<Document> query(String directoryPath,Query query) throws IOException {
IndexSearcher searcher = createIndexSearcher(directoryPath);
TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
List<Document> docList = new ArrayList<Document>();
ScoreDoc[] docs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : docs) {
int docID = scoreDoc.doc;
Document document = searcher.doc(docID);
docList.add(document);
}
searcher.getIndexReader().close();
return docList;
}
}
TermRangeQuery构造函数如下:
TermRangeQuery(String field, BytesRef lowerTerm, BytesRef upperTerm, boolean includeLower, boolean includeUpper)
BytesRef创建很简单,直接new BytesRef(string)传入一个字符串即可, TermRangeQuery还提供了一个静态方法来构建TermRangeQuery实例:
/**
* Factory that creates a new TermRangeQuery using Strings for term text.
*/
public static TermRangeQuery newStringRange(String field, String lowerTerm, String upperTerm, boolean includeLower, boolean includeUpper) {
BytesRef lower = lowerTerm == null ? null : new BytesRef(lowerTerm);
BytesRef upper = upperTerm == null ? null : new BytesRef(upperTerm);
return new TermRangeQuery(field, lower, upper, includeLower, includeUpper);
}
其实就是在方法内部帮我们new BytesRef()了,这样接口参数里面对用户的只有用户熟悉的String类型了而没有BytesRef类型了,毕竟用户对BytesRef不是很熟悉,会导致用户在使用API时会有些障碍,所以提供了newStringRange这么一个静态方法,当然如果你自己知道怎么使用默认的构造函数,直接使用构造函数new也可以,只是给用户多了一种选择。
TermRangeQuery就介绍这么多了,打完收工!
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!