为了方便用户往solr中添加索引,Solr为用户提供了一个post.jar工具,用户只需要在命令行下运行post.jar并传入一些参数就可以完成索引的增删改操作,对,它仅仅是一个供用户进行Solr测试的工具而已,有关post.jar的使用说明如下:
SimplePostTool version 5.1.0 Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]] Supported System Properties and their defaults: -Dc=<core/collection> -Durl=<base Solr update URL> (overrides -Dc option if specified) -Ddata=files|web|args|stdin (default=files) -Dtype=<content-type> (default=application/xml) -Dhost=<host> (default: localhost) -Dport=<port> (default: 8983) -Dauto=yes|no (default=no) -Drecursive=yes|no|<depth> (default=0) -Ddelay=<seconds> (default=0 for files, 10 for web) -Dfiletypes=<type>[,<type>,...] (default=xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log) -Dparams="<key>=<value>[&<key>=<value>...]" (values must be URL-encoded) -Dcommit=yes|no (default=yes) -Doptimize=yes|no (default=no) -Dout=yes|no (default=no) This is a simple command line tool for POSTing raw data to a Solr port. NOTE: Specifying the url/core/collection name is mandatory. Data can be read from files specified as commandline args, URLs specified as args, as raw commandline arg strings or via STDIN. Examples: java -Dc=gettingstarted -jar post.jar *.xml java -Ddata=args -Dc=gettingstarted -jar post.jar '<delete><id>42</id></delete>' java -Ddata=stdin -Dc=gettingstarted -jar post.jar < hd.xml java -Ddata=web -Dc=gettingstarted -jar post.jar http://example.com/ java -Dtype=text/csv -Dc=gettingstarted -jar post.jar *.csv java -Dtype=application/json -Dc=gettingstarted -jar post.jar *.json java -Durl=http://localhost:8983/solr/techproducts/update/extract -Dparams=literal.id=pdf1 -jar post.jar solr-word.pdf java -Dauto -Dc=gettingstarted -jar post.jar * java -Dauto -Dc=gettingstarted -Drecursive -jar post.jar afolder java -Dauto -Dc=gettingstarted -Dfiletypes=ppt,html -jar post.jar afolder The options controlled by System Properties include the Solr URL to POST to, the Content-Type of the data, whether a commit or optimize should be executed, and whether the response should be written to STDOUT. If auto=yes the tool will try to set type automatically from file name. When posting rich documents the file name will be propagated as "resource.name" and also used as "literal.id". You may override these or any other request parameter through the -Dparams property. To do a commit only, use "-" as argument. The web mode is a simple crawler following links within domain, default delay=10s.
重点在这里:
java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]
要看懂这个post.jar使用命令规范,你首先需要知道,被中括号包住的参数表示可选参数即这个参数可有可有,| 表示或者,SystemProperties表示系统属性,什么叫系统属性呢?即你通过System.setProperty();设置的参数,比如:
System.setProperty(key,value);
这里的key,value值都是随便定义的,没什么特别要求,这样你随后通过System.getProperty(key)通过key就能在任意时刻获取到该key对应的参数值,如果是在dos命令行下,你也可以通过java -Dkey=value这种方式指定,至此java [SystemProperties]这部分你应该理解了,至于后面的-jar是java命令的参数,即执行一个jar文件,-jar后面指定一个jar包路径,默认是相对于当前所在路径,-h即表示添加了这个即会打印命令提示信息,就好比你敲java -h是类似的,后面的file,folder,url,args分别表示你要提交的数据的几种不同表示形式,file即表示你要提交的数据是存在于文件中,而folder即表示你要提交的存在于文件夹中,url即表示你要提交的数据是存在于互联网上的一个URL地址表示的资源,它可能是一个HTML页面,可能是一个PDF文件,可能是一个图片等等,args即表示你要提交的数据直接在命令行敲出来,但arges并不是随随便便一个字符串就行的,它需要有固定的格式,solr才能解析,至于args的输入格式后面会说到。
Supported System Properties and their defaults:
这句下面列出了post.jar支持的几个自定义系统属性,下面我会对每个自定义系统属性一一做个说明:
-Dc=<core/collection> -Durl=<base Solr update URL> (overrides -Dc option if specified) -Ddata=files|web|args|stdin (default=files) -Dtype=<content-type> (default=application/xml) -Dhost=<host> (default: localhost) -Dport=<port> (default: 8983) -Dauto=yes|no (default=no) -Drecursive=yes|no|<depth> (default=0) -Ddelay=<seconds> (default=0 for files, 10 for web) -Dfiletypes=<type>[,<type>,...] (default=xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log) -Dparams="<key>=<value>[&<key>=<value>...]" (values must be URL-encoded) -Dcommit=yes|no (default=yes) -Doptimize=yes|no (default=no) -Dout=yes|no (default=no)
-D是命令行下指定系统属性的固定前缀,
c表示core名称,你需要对solr admin里的哪个core进行索引数据添加/修改/删除
url表示solr admin后台索引更新的请求URL,这个URL是固定的,一般格式是http://host:port/solr/${coreName}/update,这里的${coreName}和上面的c属性值保持一致
data表示你要提交数据的几种模式,files模式表示你要提交的数据在文件里
web表示你要提交的数据在互联网上的一个URL表示的资源文件里
args表示你要提交的数据你会直接在post.jar命令后面直接输入
stdin表示你要提交的数据需要在dos命令行下通过System.in输入流临时接收,跟args有点类似,
但不同的是,stdin模式下,post.jar后面不需要指定任何参数,直接回车即可,然后程序会等待用户输入,
用户输入完毕再回车,post.jar会接收到用户输入,post.jar重新被唤醒继续执行。而args是直接在post.jar后面
输入参数,没有一个中断过程,而stdin模式下如果用户一直没有输入,那post.jar就会一直阻塞在那里等待用户输入为止。
type表示你要提交数据的MIME类型,默认是application/xml即默认会当作是XML来处理
host表示你要链接的SOlr Admin部署服务器的主机名或者IP地址,默认是localhost
port表示你要链接的Solr Admin部署的Web容器监听的端口号,默认post.jar里设置为8983
port具体值取决于你实际部署环境而定
auto表示是否自动猜测文件类型
recursive表示是否递归,这里递归有两种情况,比如你data=folder即表示是否递归查找文件夹下的
所有文件,如果你data=web即表示是否递归抓取URL,设置为no即表示不递归操作,设置为一个数字,
即表示递归深度
delay:这里的时间延迟也分两种,如果你post的是file,那么每个file的post间隔为0,即不做延迟处理,
而如果你是post的是网络上的一个url资源,因为需要收到对方服务器的访问限制,所以必须要做一个抓取
频率限制即每抓一个睡眠一会儿,否则抓取太快太频率容易被对方封IP。
filetypes表示post.jar支持提交哪些文件类型,后面有列出默认支持的文件类型,如果你想覆盖默认值,那么
请指定此参数
params表示需要追加到Solr Admin的请求URL后面的请求参数如id=1&name=yida之类的
commit表示是否提交到solr admin后台进行索引写入,设置为false表示不提交至sor admin,但设置为true也不一定
就意味着就一定会把索引写入磁盘,这取决于solrconfig中directory配置的实现是什么,如果配置的是RAMDirectory,就仅仅只在内存中操作了。
optimize表示是否需要对索引进行优化操作,默认为no即表示不对索引进行优化
out即OutputStream表示输出流,这个参数作用就是,你请求Solr Admin添加索引数据,Solr Admin后台会返回数据给你,Solr Admin后台返回的数据你拿什么输出流来接收,默认是System.out即表示把后台返回的信息输出打印到控制台
理解上面的相关说明,再来看看官方提供的几个post.jar使用命令示例,是不是感觉so easy了?
Examples: java -Dc=gettingstarted -jar post.jar *.xml java -Ddata=args -Dc=gettingstarted -jar post.jar '<delete><id>42</id></delete>' java -Ddata=stdin -Dc=gettingstarted -jar post.jar < hd.xml java -Ddata=web -Dc=gettingstarted -jar post.jar http://example.com/ java -Dtype=text/csv -Dc=gettingstarted -jar post.jar *.csv java -Dtype=application/json -Dc=gettingstarted -jar post.jar *.json java -Durl=http://localhost:8983/solr/techproducts/update/extract -Dparams=literal.id=pdf1 -jar post.jar solr-word.pdf java -Dauto -Dc=gettingstarted -jar post.jar * java -Dauto -Dc=gettingstarted -Drecursive -jar post.jar afolder java -Dauto -Dc=gettingstarted -Dfiletypes=ppt,html -jar post.jar afolder
OK,post.jar知道怎么玩了,那是不是该来实践一把?要想往solr admin后台添加索引数据,你首先需要添加一个core,添加一个core你可以通过Solr Admin的web UI来创建,如图: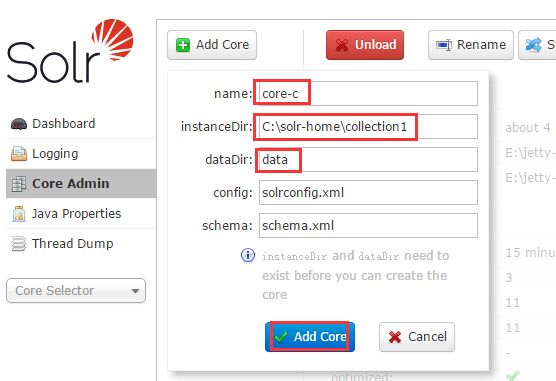
instanceDir就是你的core根目录,solr-hone就是你的SOLR_HOME,你可以在SOLR_HOME下创建多个core目录,dataDir表示你core的数据目录,当前core的索引数据会存放在dataDir下的data\index目录下,上述所有文件夹需要你手动创建(除了data\index这里的index目录,solr会自动创建),如图: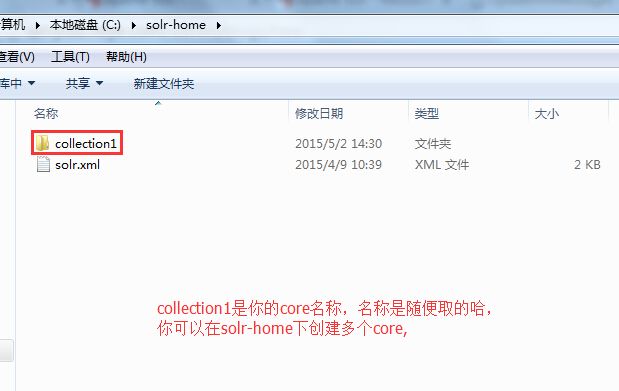
solr_home目录下需要一个solr.xml,这个配置文件可以从solr的zip包里获取,如图: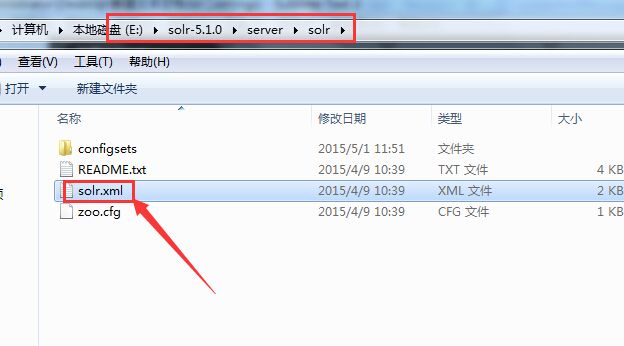
如图找到solr.xml复制到你自己的solr-home根目录下,然后你的core目录下需要一个conf目录,用来存放当前core的solr配置,这些配置文件可以从solr的examples里找到,如图:
solrconfig.xml配置文件是每个core必须的一个配置文件,只对当前core有效,sechma.xml配置文件是用来定义索引的每个域的,比如域的名称啊,域的类型,域是否索引,是否存储,是否分词,是否存储项向量,使用什么分词器,指定同义词字典文件在哪儿,指定停用词字典文件在哪儿等等,这些信息都是是sechma.xml中定义的,如果你有点Lucene基础,那编写schema.xml就没什么压力了,只不过以前在Lucene中是直接使用Lucene API来定义域的这些信息的,现在改用XML形式表达同样的意思。注意里面还有个protwords.txt字典文件,这在Lucene中还没接触过。下面是一段有关protwords.txt字典文件的解释说明:
Protwords are the words which you do not want to be stemmed (In stemming case manager/managing/managed/manageable all are indexed as ---> manag. Same thing goes in case of searching. In case you do not want a particular word to be stemmed at index/search time just put it in protwords.txt of SOLR.
大意就是Protwords表示那些你不想被还原的单词,比如manager/managing/managed/manageable这些单词,
在stemming模式下,他们全都被索引为manag,如果你不希望某个单词被stemming(转换成原型),那么你就可以把他们放入protwords.txt字典文件中,这样他们就不会被还原成原型了。
prot即protected缩写,即受保护的意思,只有英文才存在单词还原的情况。
这样你的core目录结构就创建好了,如果你不按这种规范去创建目录结构,那么你在创建core的时候会报错,比如你可能会遇到这样的异常:
Core创建成功后,你会在solr admin 后台看到这样的界面:
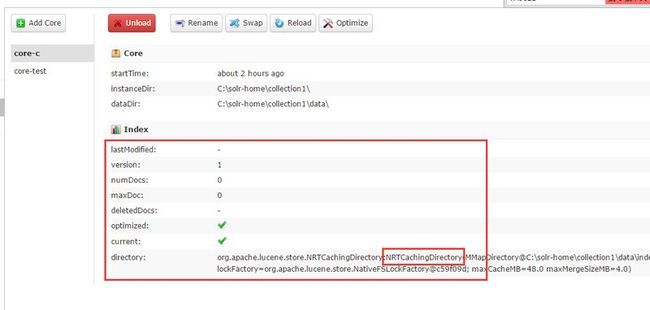
当然你也可以直接通过在浏览器输入URL的方式来创建,
http://localhost:8080/solr/admin/cores?action=CREATE&name=core2&instanceDir=/opt/solr/core2&config=solrconfig.xml&schema=schema.xml&dataDir=data
name:就是你的core名称,
instanceDir就是你的core根目录,举个例子,linux下可能是/opt/solr/core2,windows下可能是C:/solr/core2
config,schema即core的两个重要的配置文件的名称,只要你core目录结构按规范创建好了,就会按照你指定的配置文件名称去conf目录下去找,dataDir表示你的core的数据目录,该用户主要用来存放你当前core的索引数据
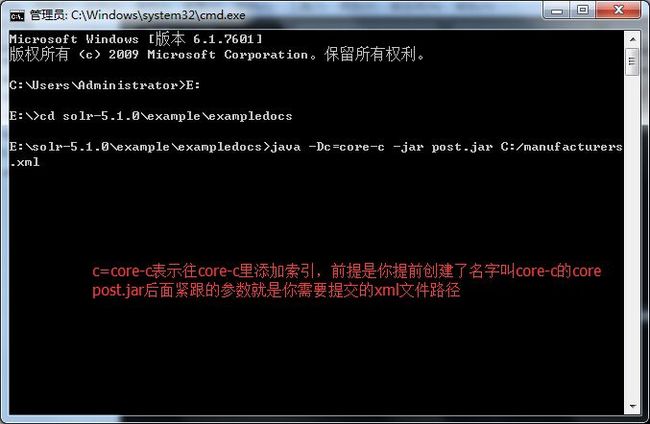
core创建好了,那就可以在命令行下执行post.jar往solr admin中添加索引了,首先你需要在dos下切到post.jar所在目录,如图: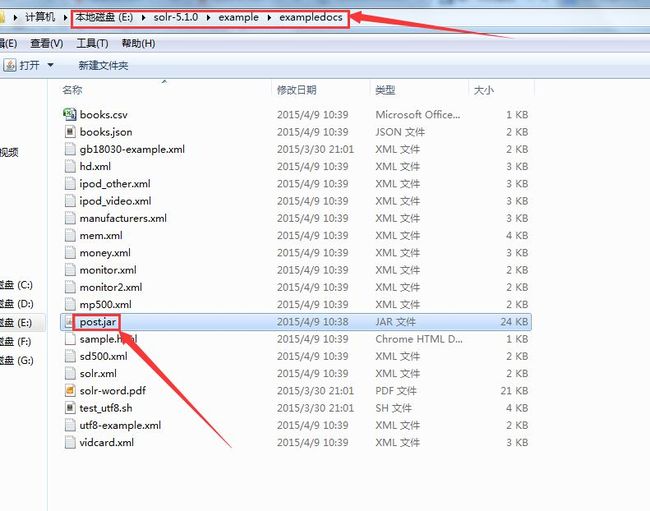
在运行post.jar命令之前,我们需要找一个测试用的xml文件,这里我以solr的examples目录下提供的xml为例,如图: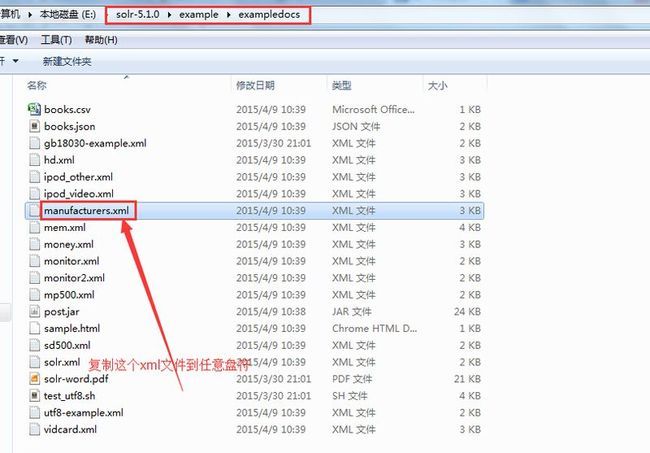
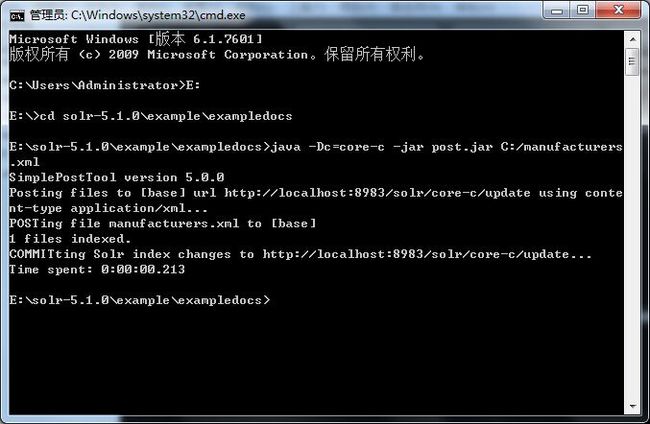
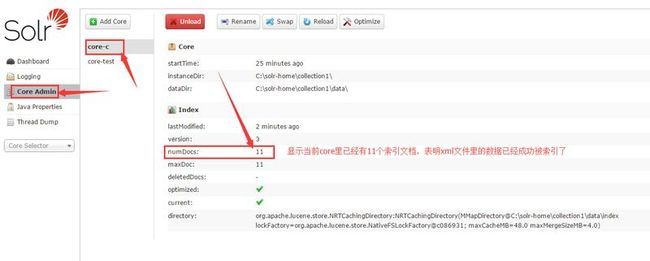
然后到Solr Admin web后台界面刷新页面,查看core-c的索引数量是否有变化,如图:
但是要注意,不是任何xml文件都可以被索引的,提交的XML内容是有固定的编写格式的,打开我们刚刚提交的xml文件,如图:
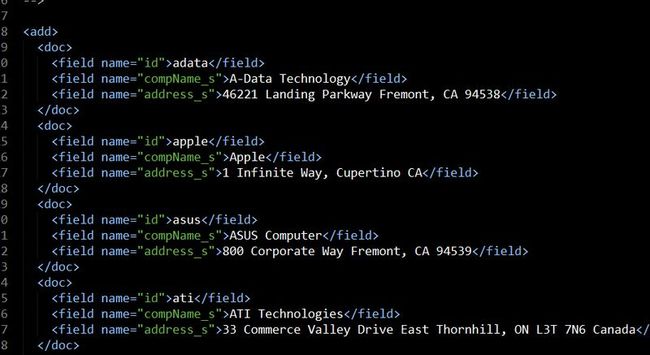
<add>表示添加索引,一对<doc></doc>表示Lucene中的一个Document,field表示域,name毫无疑问就是域名,field标签之间的值就是域值,<add>标签只有有一个,<add>标签下可以有多个<doc>标签,多个<doc>即表示批量添加多个document.
<add>标签还有2个可选属性,
overwrite: "true" | "false" ,默认为false,表示对于拥有相同uniqueKey的document是否需要覆盖,uniqueKey表示document的唯一主键,类似数据库表的主键,
commitWithin:表示document必须在指定的毫秒数内提交成功,否则就放弃提交。
你还可以为某个document设置权重,比如:
<add>
<doc boost="2.5">
<field name="employeeId">05991</field>
<field name="office" boost="2.0">Bridgewater</field>
</doc>
</add>
如何添加多值域?
<add>
<doc>
<field name="employeeId">05991</field>
<field name="skills" update="set">Python</field>
<field name="skills" update="set">Java</field>
<field name="skills" update="set">Jython</field>
</doc>
</add>
如何将某个域的值设为null?
<add>
<doc>
<field name="employeeId">05991</field>
<field name="skills" update="set" null="true" />
</doc>
</add>
你还可以在<add>标签下添加
<commit/> <optimize/>
类似于你在Lucene里显式的调用writer.commit();writer.optimize();
如何根据ID删除document?(注意这里说的id指的是uniqueKey指定的域,uniqueKey是在schema.xml中定义的,不要与document的文档ID混为一谈)
<delete><id>05991</id></delete>
如何根据一个Query删除一个Document呢?
<delete><query>office:Bridgewater</query></delete>
office表示域名,bridgewater表示域值,默认创建的是TermQuery,域值可以有通配符,可以是正则表达式,可以使用QueryParser表达式表示,你懂的。
上面说的都是在命令行下操作,如果你觉得在命令行下操作有点蛋疼,那我们也可以在eclipse中操作,通过反编译post.jar我发现post.jar包里面就是一个SimplePostTool类,我花了点时间阅读了SimplePostTool类的源码并对其关键位置加了一些注释,源码如下:
package com.yida.framework.solr5.test;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileFilter;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.ProtocolException;
import java.net.URL;
import java.net.URLEncoder;
import java.nio.BufferOverflowException;
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Locale;
import java.util.Map;
import java.util.Set;
import java.util.TimeZone;
import java.util.regex.Pattern;
import java.util.regex.PatternSyntaxException;
import java.util.zip.GZIPInputStream;
import java.util.zip.Inflater;
import java.util.zip.InflaterInputStream;
import javax.xml.bind.DatatypeConverter;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* 往Solr Admin后台提交索引数据的一个小测试工具
* @author Lanxiaowei
*
*/
@SuppressWarnings("unused")
public class SimplePostTool {
/**Solr Admin后台部署服务器的主机名或IP地址,默认为localhost即本地*/
private static final String DEFAULT_POST_HOST = "localhost";
/**Solr Admin后台部署容器监听的端口号,默认为8983*/
private static final String DEFAULT_POST_PORT = "8983";
/**当前工具的版本号*/
private static final String VERSION_OF_THIS_TOOL = "5.1.0";
/**是否提交索引*/
private static final String DEFAULT_COMMIT = "yes";
/**是否需要优化索引*/
private static final String DEFAULT_OPTIMIZE = "no";
/**是否将输出流设置为System.out即控制台输出流*/
private static final String DEFAULT_OUT = "no";
/**是否自动猜测文件MIME类型,默认是按照文件后缀名进行判定*/
private static final String DEFAULT_AUTO = "no";
/**是否递归抓取,0表示不递归抓取,1表示递归抓取*/
private static final String DEFAULT_RECURSIVE = "0";
/**抓取时间间隔即每抓取一个URL后睡眠多少秒,单位:秒*/
private static final int DEFAULT_WEB_DELAY = 10;
/**默认索引提交时间间隔即每提交一个睡眠多少毫秒,单位:毫秒*/
private static final int DEFAULT_POST_DELAY = 10;
/**对于URL就是抓取深度,对于文件夹就是目录深度,当前深度为0*/
private static final int MAX_WEB_DEPTH = 10;
/**默认文件MIME类型*/
private static final String DEFAULT_CONTENT_TYPE = "application/xml";
/**默认支持提交的文件类型*/
private static final String DEFAULT_FILE_TYPES = "xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log";
/**文件提交模式*/
static final String DATA_MODE_FILES = "files";
/**URL后面挂参数形式提交*/
static final String DATA_MODE_ARGS = "args";
/**标准输入模式,选择了这种模式的话,程序会中断,等待用户输入作为提交数据*/
static final String DATA_MODE_STDIN = "stdin";
/**爬虫抓取模式提交索引即需要用户提供一个待抓的页面链接,内部去抓取页面内容然后提交*/
static final String DATA_MODE_WEB = "web";
/**默认提交模式为files即提交文件*/
static final String DEFAULT_DATA_MODE = "files";
boolean auto = false;
int recursive = 0;
int delay = 0;
String fileTypes;
URL solrUrl;
OutputStream out = null;
String type;
String mode;
boolean commit;
boolean optimize;
String[] args;
private int currentDepth;
static HashMap<String, String> mimeMap;
GlobFileFilter globFileFilter;
//每个深度的URL集合,这里的list索引即抓取深度
List<LinkedHashSet<URL>> backlog = new ArrayList<LinkedHashSet<URL>>();
//已抓取过的URL集合
Set<URL> visited = new HashSet<URL>();
static final Set<String> DATA_MODES = new HashSet<String>();
static final String USAGE_STRING_SHORT = "Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]";
static boolean mockMode = false;
static PageFetcher pageFetcher;
public static void main(String[] args) {
String coreName = "core-test";
System.setProperty("c",coreName);
info("SimplePostTool version 5.1.0");
if ((0 < args.length)
&& (("-help".equals(args[0])) || ("--help".equals(args[0])) || ("-h"
.equals(args[0])))) {
//打印post.jar命令提示信息
usage();
} else {
SimplePostTool t = parseArgsAndInit(args);
t.execute();
}
}
public void execute() {
long startTime = System.currentTimeMillis();
if (("files".equals(this.mode)) && (this.args.length > 0)) {
doFilesMode();
} else if (("args".equals(this.mode)) && (this.args.length > 0)) {
doArgsMode();
} else if (("web".equals(this.mode)) && (this.args.length > 0)) {
doWebMode();
} else if ("stdin".equals(this.mode)) {
doStdinMode();
} else {
usageShort();
return;
}
if (this.commit)
commit();
if (this.optimize)
optimize();
long endTime = System.currentTimeMillis();
displayTiming(endTime - startTime);
}
private void displayTiming(long millis) {
SimpleDateFormat df = new SimpleDateFormat("H:mm:ss.SSS",
Locale.getDefault());
df.setTimeZone(TimeZone.getTimeZone("UTC"));
System.out.println(new StringBuilder().append("Time spent: ")
.append(df.format(new Date(millis))).toString());
}
protected static SimplePostTool parseArgsAndInit(String[] args) {
String urlStr = null;
try {
String mode = System.getProperty("data", "files");
if (!DATA_MODES.contains(mode)) {
fatal(new StringBuilder()
.append("System Property 'data' is not valid for this tool: ")
.append(mode).toString());
}
//需要追加到Solr请求URL后面的请求参数
String params = System.getProperty("params", "");
String host = System.getProperty("host", DEFAULT_POST_HOST);
String port = System.getProperty("port", DEFAULT_POST_PORT);
String core = System.getProperty("c");
urlStr = System.getProperty("url");
if ((urlStr == null) && (core == null)) {
fatal("Specifying either url or core/collection is mandatory.\nUsage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]");
}
//若没有指定Solr请求URL,则生成默认的SOLR请求URL
if (urlStr == null) {
urlStr = String.format(Locale.ROOT,
"http://%s:%s/solr/%s/update", new Object[] { host,
port, core });
}
urlStr = appendParam(urlStr, params);
URL url = new URL(urlStr);
boolean auto = isOn(System.getProperty("auto", DEFAULT_AUTO));
String type = System.getProperty("type");
int recursive = 0;
String r = System.getProperty("recursive", DEFAULT_RECURSIVE);
try {
recursive = Integer.parseInt(r);
} catch (Exception e) {
if (isOn(r)) {
recursive = "web".equals(mode) ? 1 : 999;
}
}
int delay = "web".equals(mode) ? DEFAULT_WEB_DELAY : 0;
try {
delay = Integer.parseInt(System
.getProperty("delay", delay + ""));
} catch (Exception e) {
}
OutputStream out = isOn(System.getProperty("out", DEFAULT_OUT)) ? System.out
: null;
String fileTypes = System.getProperty("filetypes",DEFAULT_FILE_TYPES);
boolean commit = isOn(System.getProperty("commit", DEFAULT_COMMIT));
boolean optimize = isOn(System.getProperty("optimize", DEFAULT_OPTIMIZE));
return new SimplePostTool(mode, url, auto, type, recursive, delay,
fileTypes, out, commit, optimize, args);
} catch (MalformedURLException e) {
fatal(new StringBuilder()
.append("System Property 'url' is not a valid URL: ")
.append(urlStr).toString());
}
return null;
}
public SimplePostTool(String mode, URL url, boolean auto, String type,
int recursive, int delay, String fileTypes, OutputStream out,
boolean commit, boolean optimize, String[] args) {
this.mode = mode;
this.solrUrl = url;
this.auto = auto;
this.type = type;
this.recursive = recursive;
this.delay = delay;
this.fileTypes = fileTypes;
this.globFileFilter = getFileFilterFromFileTypes(fileTypes);
this.out = out;
this.commit = commit;
this.optimize = optimize;
this.args = args;
pageFetcher = new PageFetcher();
}
public SimplePostTool() {
}
/**
* 要提交的索引数据存在于文件中,你可以通过args指定一个文件目录或者一个文件路径或者xxxx\*.xml这种通配符形式
*/
private void doFilesMode() {
this.currentDepth = 0;
if (!this.args[0].equals("-")) {
info(new StringBuilder()
.append("Posting files to [base] url ")
.append(this.solrUrl)
.append(!this.auto ? new StringBuilder()
.append(" using content-type ")
.append(this.type == null ? DEFAULT_CONTENT_TYPE
: this.type).toString() : "").append("...")
.toString());
if (this.auto)
info(new StringBuilder()
.append("Entering auto mode. File endings considered are ")
.append(this.fileTypes).toString());
if (this.recursive > 0)
info(new StringBuilder()
.append("Entering recursive mode, max depth=")
.append(this.recursive).append(", delay=")
.append(this.delay).append("s").toString());
int numFilesPosted = postFiles(this.args, 0, this.out, this.type);
info(new StringBuilder().append(numFilesPosted)
.append(" files indexed.").toString());
}
}
/**
* 要提交的索引数据直接通过args post方式提交到Solr Admin后台
*/
private void doArgsMode() {
info(new StringBuilder().append("POSTing args to ")
.append(this.solrUrl).append("...").toString());
for (String a : this.args) {
postData(stringToStream(a), null, this.out, this.type, this.solrUrl);
}
}
/**
* 要提交的数据存在于互联网,需要即时去抓取网页内容,然后提交
* @return
*/
private int doWebMode() {
reset();
int numPagesPosted = 0;
try {
if (this.type != null) {
fatal("Specifying content-type with \"-Ddata=web\" is not supported");
}
if (this.args[0].equals("-")) {
return 0;
}
this.solrUrl = appendUrlPath(this.solrUrl, "/extract");
info(new StringBuilder().append("Posting web pages to Solr url ")
.append(this.solrUrl).toString());
this.auto = true;
info(new StringBuilder()
.append("Entering auto mode. Indexing pages with content-types corresponding to file endings ")
.append(this.fileTypes).toString());
if (this.recursive > 0) {
if (this.recursive > MAX_WEB_DEPTH) {
this.recursive = MAX_WEB_DEPTH;
warn("Too large recursion depth for web mode, limiting to 10...");
}
if (this.delay < DEFAULT_WEB_DELAY)
warn("Never crawl an external web site faster than every "+DEFAULT_WEB_DELAY+" seconds, your IP will probably be blocked");
info(new StringBuilder()
.append("Entering recursive mode, depth=")
.append(this.recursive).append(", delay=")
.append(this.delay).append("s").toString());
}
numPagesPosted = postWebPages(this.args, 0, this.out);
info(new StringBuilder().append(numPagesPosted)
.append(" web pages indexed.").toString());
} catch (MalformedURLException e) {
fatal(new StringBuilder()
.append("Wrong URL trying to append /extract to ")
.append(this.solrUrl).toString());
}
return numPagesPosted;
}
private void doStdinMode() {
info(new StringBuilder().append("POSTing stdin to ")
.append(this.solrUrl).append("...").toString());
postData(System.in, null, this.out, this.type, this.solrUrl);
}
private void reset() {
this.fileTypes = "xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log";
this.globFileFilter = getFileFilterFromFileTypes(this.fileTypes);
this.backlog = new ArrayList<LinkedHashSet<URL>>();
this.visited = new HashSet<URL>();
}
/**
* 打印post.jar命令使用示例
*/
private static void usageShort() {
System.out
.println("Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]\n Please invoke with -h option for extended usage help.");
}
/**
* 打印post.jar命令提示信息
*/
private static void usage() {
System.out
.println("Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]\n\nSupported System Properties and their defaults:\n -Dc=<core/collection>\n -Durl=<base Solr update URL> (overrides -Dc option if specified)\n -Ddata=files|web|args|stdin (default=files)\n -Dtype=<content-type> (default=application/xml)\n -Dhost=<host> (default: localhost)\n -Dport=<port> (default: "+DEFAULT_POST_PORT+")\n -Dauto=yes|no (default=no)\n -Drecursive=yes|no|<depth> (default=0)\n -Ddelay=<seconds> (default=0 for files, 10 for web)\n -Dfiletypes=<type>[,<type>,...] (default=xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log)\n -Dparams=\"<key>=<value>[&<key>=<value>...]\" (values must be URL-encoded)\n -Dcommit=yes|no (default=yes)\n -Doptimize=yes|no (default=no)\n -Dout=yes|no (default=no)\n\nThis is a simple command line tool for POSTing raw data to a Solr port.\nNOTE: Specifying the url/core/collection name is mandatory.\nData can be read from files specified as commandline args,\nURLs specified as args, as raw commandline arg strings or via STDIN.\nExamples:\n java -Dc=gettingstarted -jar post.jar *.xml\n java -Ddata=args -Dc=gettingstarted -jar post.jar '<delete><id>42</id></delete>'\n java -Ddata=stdin -Dc=gettingstarted -jar post.jar < hd.xml\n java -Ddata=web -Dc=gettingstarted -jar post.jar http://example.com/\n java -Dtype=text/csv -Dc=gettingstarted -jar post.jar *.csv\n java -Dtype=application/json -Dc=gettingstarted -jar post.jar *.json\n java -Durl=http://localhost:8983/solr/techproducts/update/extract -Dparams=literal.id=pdf1 -jar post.jar solr-word.pdf\n java -Dauto -Dc=gettingstarted -jar post.jar *\n java -Dauto -Dc=gettingstarted -Drecursive -jar post.jar afolder\n java -Dauto -Dc=gettingstarted -Dfiletypes=ppt,html -jar post.jar afolder\nThe options controlled by System Properties include the Solr\nURL to POST to, the Content-Type of the data, whether a commit\nor optimize should be executed, and whether the response should\nbe written to STDOUT. If auto=yes the tool will try to set type\nautomatically from file name. When posting rich documents the\nfile name will be propagated as \"resource.name\" and also used\nas \"literal.id\". You may override these or any other request parameter\nthrough the -Dparams property. To do a commit only, use \"-\" as argument.\nThe web mode is a simple crawler following links within domain, default delay="+DEFAULT_WEB_DELAY+"s.");
}
/**
* 提交文件
* @param args
* @param startIndexInArgs
* @param out
* @param type
* @return
*/
public int postFiles(String[] args, int startIndexInArgs, OutputStream out,
String type) {
reset();
int filesPosted = 0;
for (int j = startIndexInArgs; j < args.length; j++) {
File srcFile = new File(args[j]);
if ((srcFile.isDirectory()) && (srcFile.canRead())) {
filesPosted += postDirectory(srcFile, out, type);
} else if ((srcFile.isFile()) && (srcFile.canRead())) {
filesPosted += postFiles(new File[] { srcFile }, out, type);
} else {
File parent = srcFile.getParentFile();
if (parent == null)
parent = new File(".");
String fileGlob = srcFile.getName();
GlobFileFilter ff = new GlobFileFilter(fileGlob, false);
File[] files = parent.listFiles(ff);
if ((files == null) || (files.length == 0)) {
warn(new StringBuilder()
.append("No files or directories matching ")
.append(srcFile).toString());
} else
filesPosted += postFiles(parent.listFiles(ff), out, type);
}
}
return filesPosted;
}
/**
* 提交文件
* @param files
* @param startIndexInArgs
* @param out
* @param type
* @return
*/
public int postFiles(File[] files, int startIndexInArgs, OutputStream out,
String type) {
reset();
int filesPosted = 0;
for (File srcFile : files) {
if ((srcFile.isDirectory()) && (srcFile.canRead())) {
filesPosted += postDirectory(srcFile, out, type);
} else if ((srcFile.isFile()) && (srcFile.canRead())) {
filesPosted += postFiles(new File[] { srcFile }, out, type);
} else {
File parent = srcFile.getParentFile();
if (parent == null)
parent = new File(".");
String fileGlob = srcFile.getName();
GlobFileFilter ff = new GlobFileFilter(fileGlob, false);
File[] fileList = parent.listFiles(ff);
if ((fileList == null) || (fileList.length == 0)) {
warn(new StringBuilder()
.append("No files or directories matching ")
.append(srcFile).toString());
} else
filesPosted += postFiles(fileList, out, type);
}
}
return filesPosted;
}
/**
* 提交目录下所有文件
* @param dir
* @param out
* @param type
* @return 返回提交的文件数量
*/
private int postDirectory(File dir, OutputStream out, String type) {
if ((dir.isHidden()) && (!dir.getName().equals(".")))
return 0;
info(new StringBuilder().append("Indexing directory ")
.append(dir.getPath()).append(" (")
.append(dir.listFiles(this.globFileFilter).length)
.append(" files, depth=").append(this.currentDepth).append(")")
.toString());
int posted = 0;
posted += postFiles(dir.listFiles(this.globFileFilter), out, type);
if (this.recursive > this.currentDepth) {
for (File d : dir.listFiles()) {
if (d.isDirectory()) {
this.currentDepth += 1;
posted += postDirectory(d, out, type);
this.currentDepth -= 1;
}
}
}
return posted;
}
/**
* 提交文件
* @param files
* @param out
* @param type
* @return
*/
public int postFiles(File[] files, OutputStream out, String type) {
int filesPosted = 0;
for (File srcFile : files) {
try {
if ((!srcFile.isFile()) || (!srcFile.isHidden())) {
postFile(srcFile, out, type);
Thread.sleep(DEFAULT_POST_DELAY);
filesPosted++;
}
} catch (InterruptedException e) {
throw new RuntimeException();
}
}
return filesPosted;
}
/**
* 根据用户提供的url进行web模式提交索引数据
* @param args
* @param startIndexInArgs
* @param out
* @return
*/
public int postWebPages(String[] args, int startIndexInArgs,
OutputStream out) {
reset();
LinkedHashSet<URL> s = new LinkedHashSet<URL>();
for (int j = startIndexInArgs; j < args.length; j++) {
try {
URL u = new URL(normalizeUrlEnding(args[j]));
s.add(u);
} catch (MalformedURLException e) {
warn(new StringBuilder()
.append("Skipping malformed input URL: ")
.append(args[j]).toString());
}
}
//将URL集合存入backlog
this.backlog.add(s);
//这里0表示抓取深度,刚开始抓取深度为0
return webCrawl(0, out);
}
/**
* 将不规范的URL标准化
* @param link
* @return
*/
protected static String normalizeUrlEnding(String link) {
//如果URL中包含#号,则直接截图开头至#号位置出,#后面部分丢弃
if (link.indexOf("#") > -1) {
link = link.substring(0, link.indexOf("#"));
}
//如果URL以问号结尾,则删除结尾的问号
if (link.endsWith("?")) {
link = link.substring(0, link.length() - 1);
}
//如果URL以/结尾,则删除结尾的/
if (link.endsWith("/")) {
link = link.substring(0, link.length() - 1);
}
return link;
}
/**
* 页面抓取
* @param level 当前抓取深度
* @param out
* @return
*/
protected int webCrawl(int level, OutputStream out) {
int numPages = 0;
LinkedHashSet<URL> stack = (LinkedHashSet<URL>) this.backlog.get(level);
int rawStackSize = stack.size();
stack.removeAll(this.visited);
int stackSize = stack.size();
LinkedHashSet<URL> subStack = new LinkedHashSet<URL>();
info(new StringBuilder().append("Entering crawl at level ")
.append(level).append(" (").append(rawStackSize)
.append(" links total, ").append(stackSize).append(" new)")
.toString());
for (URL u : stack) {
try {
//当前URL存入已访问列表,避免同一URL重复抓取
this.visited.add(u);
//获取到页面内容PageFetcherResult
PageFetcherResult result = pageFetcher.readPageFromUrl(u);
//状态码200表示页面抓取成功
if (result.httpStatus == 200) {
u = result.redirectUrl != null ? result.redirectUrl : u;
//如果有页面重定向,则抓取重定向后的页面内容
URL postUrl = new URL(appendParam(
this.solrUrl.toString(),
new StringBuilder()
.append("literal.id=")
.append(URLEncoder.encode(u.toString(),
"UTF-8"))
.append("&literal.url=")
.append(URLEncoder.encode(u.toString(),
"UTF-8")).toString()));
boolean success = postData(
new ByteArrayInputStream(result.content.array(),
result.content.arrayOffset(),
result.content.limit()), null, out,
result.contentType, postUrl);
if (success) {
info(new StringBuilder().append("POSTed web resource ")
.append(u).append(" (depth: ").append(level)
.append(")").toString());
Thread.sleep(this.delay * 1000);
numPages++;
//如果抓取深度还没超过限制
if ((this.recursive > level)
&& (result.contentType.equals("text/html"))) {
//从抓取的页面中提取出URL
Set<URL> children = pageFetcher.getLinksFromWebPage(
u,
new ByteArrayInputStream(result.content
.array(), result.content
.arrayOffset(), result.content
.limit()), result.contentType,
postUrl);
//把提取出来的URL存入stack中
subStack.addAll(children);
}
} else {
warn(new StringBuilder()
.append("An error occurred while posting ")
.append(u).toString());
}
} else {
warn(new StringBuilder().append("The URL ").append(u)
.append(" returned a HTTP result status of ")
.append(result.httpStatus).toString());
}
} catch (IOException e) {
warn(new StringBuilder()
.append("Caught exception when trying to open connection to ")
.append(u).append(": ").append(e.getMessage())
.toString());
} catch (InterruptedException e) {
throw new RuntimeException();
}
}
if (!subStack.isEmpty()) {
this.backlog.add(subStack);
numPages += webCrawl(level + 1, out);
}
return numPages;
}
public static ByteBuffer inputStreamToByteArray(BAOS bos,InputStream is)
throws IOException {
return inputStreamToByteArray(bos,is, 2147483647L);
}
/**
* 页面输入流转换到输出流,然后输出流将接收到的字节数据存入ByteBuffer字节缓冲区
* @param bos
* @param is
* @param maxSize
* @return
* @throws IOException
*/
public static ByteBuffer inputStreamToByteArray(BAOS bos,InputStream is, long maxSize)
throws IOException {
long sz = 0L;
int next = is.read();
while (next > -1) {
if (++sz > maxSize) {
throw new BufferOverflowException();
}
bos.write(next);
next = is.read();
}
bos.flush();
is.close();
return bos.getByteBuffer();
}
/**
* 计算完整的URL,因为页面上的A标签的href属性值可能是相对路径,所以这里需要拼接上baseUrl,你懂的
* @param baseUrl 网站根路径
* @param link 从A标签属性值上提取出来的值
* @return
*/
protected String computeFullUrl(URL baseUrl, String link) {
if ((link == null) || (link.length() == 0)) {
return null;
}
if (!link.startsWith("http")) {
if (link.startsWith("/")) {
link = new StringBuilder().append(baseUrl.getProtocol())
.append("://").append(baseUrl.getAuthority())
.append(link).toString();
} else {
if (link.contains(":")) {
return null;
}
String path = baseUrl.getPath();
if (!path.endsWith("/")) {
int sep = path.lastIndexOf("/");
String file = path.substring(sep + 1);
if ((file.contains(".")) || (file.contains("?")))
path = path.substring(0, sep);
}
link = new StringBuilder().append(baseUrl.getProtocol())
.append("://").append(baseUrl.getAuthority())
.append(path).append("/").append(link).toString();
}
}
link = normalizeUrlEnding(link);
String l = link.toLowerCase(Locale.ROOT);
//过滤调图片链接
if ((l.endsWith(".jpg")) || (l.endsWith(".jpeg"))
|| (l.endsWith(".png")) || (l.endsWith(".gif"))) {
return null;
}
return link;
}
/**
* 判断某个文件类型是否在程序支持范围内,支持范围由mimeMap变量定义
* @param type
* @return
*/
protected boolean typeSupported(String type) {
for (String key : mimeMap.keySet()) {
if ((((String) mimeMap.get(key)).equals(type))
&& (this.fileTypes.contains(key))) {
return true;
}
}
return false;
}
/**
* 只要输入的是true,on,yes,1都返回true
* @param property
* @return
*/
protected static boolean isOn(String property) {
return "true,on,yes,1".indexOf(property) > -1;
}
/**
* 打印警告信息
* @param msg
*/
static void warn(String msg) {
System.err.println(new StringBuilder()
.append("SimplePostTool: WARNING: ").append(msg).toString());
}
/**
* 打印提示信息
* @param msg
*/
static void info(String msg) {
System.out.println(msg);
}
/**
* 打印比较严重致命性的信息
* @param msg
*/
static void fatal(String msg) {
System.err.println(new StringBuilder()
.append("SimplePostTool: FATAL: ").append(msg).toString());
System.exit(2);
}
/**
* 提交索引数据至Solr Admin
*/
public void commit() {
info(new StringBuilder().append("COMMITting Solr index changes to ")
.append(this.solrUrl).append("...").toString());
doGet(appendParam(this.solrUrl.toString(), "commit=true"));
}
/**
* 发送索引优化请求至Solr Admin后台
*/
public void optimize() {
info(new StringBuilder().append("Performing an OPTIMIZE to ")
.append(this.solrUrl).append("...").toString());
doGet(appendParam(this.solrUrl.toString(), "optimize=true"));
}
/**
* 在URL后面追加参数即id=1&mode=files格式
* @param url
* @param param
* @return
*/
public static String appendParam(String url, String param) {
String[] pa = param.split("&");
for (String p : pa) {
if (p.trim().length() != 0) {
String[] kv = p.split("=");
if (kv.length == 2) {
url = new StringBuilder().append(url)
.append(url.indexOf(63) > 0 ? "&" : "?")
.append(kv[0]).append("=").append(kv[1]).toString();
} else {
warn(new StringBuilder().append("Skipping param ")
.append(p)
.append(" which is not on form key=value")
.toString());
}
}
}
return url;
}
public void postFile(File file, OutputStream output, String type) {
InputStream is = null;
try {
URL url = this.solrUrl;
String suffix = "";
if (this.auto) {
if (type == null) {
type = guessType(file);
}
if (type != null) {
if ((!type.equals("application/xml"))
&& (!type.equals("text/csv"))
&& (!type.equals("application/json"))) {
suffix = "/extract";
String urlStr = appendUrlPath(this.solrUrl, suffix)
.toString();
if (urlStr.indexOf("resource.name") == -1) {
//往提交URL后面追加resource.name参数即文件的绝对路径
urlStr = appendParam(
urlStr,
new StringBuilder()
.append("resource.name=")
.append(URLEncoder.encode(
file.getAbsolutePath(),
"UTF-8")).toString());
}
if (urlStr.indexOf("literal.id") == -1) {
//往提交URL后面追加literal.id参数即文件的绝对路径
urlStr = appendParam(
urlStr,
new StringBuilder()
.append("literal.id=")
.append(URLEncoder.encode(
file.getAbsolutePath(),
"UTF-8")).toString());
}
url = new URL(urlStr);
}
} else
//未知的文件类型则直接跳过,仅仅是打印下警告信息
warn(new StringBuilder().append("Skipping ")
.append(file.getName())
.append(". Unsupported file type for auto mode.")
.toString());
} else if (type == null) {
//如果自动猜测文件类型关闭了,而文件类型又为Null,那只好设置为默认值DEFAULT_CONTENT_TYPE
type = DEFAULT_CONTENT_TYPE;
}
info(new StringBuilder()
.append("POSTing file ")
.append(file.getName())
.append(this.auto ? new StringBuilder().append(" (")
.append(type).append(")").toString() : "")
.append(" to [base]").append(suffix).toString());
is = new FileInputStream(file);
//开始提交文件
postData(is, Integer.valueOf((int) file.length()), output, type,
url);
} catch (IOException e) {
e.printStackTrace();
warn(new StringBuilder().append("Can't open/read file: ")
.append(file).toString());
} finally {
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
fatal(new StringBuilder()
.append("IOException while closing file: ").append(e)
.toString());
}
}
}
/**
* 往请求URL追加内容,
* 如http://localhost:8080/solr/core1?param1=value1¶m2=value2 追加一个/update后
* http://localhost:8080/solr/core1/update?param1=value1¶m2=value2
* @param url
* @param append
* @return
* @throws MalformedURLException
*/
protected static URL appendUrlPath(URL url, String append)
throws MalformedURLException {
return new URL(new StringBuilder()
.append(url.getProtocol())
.append("://")
.append(url.getAuthority())
.append(url.getPath())
.append(append)
.append(url.getQuery() != null ? new StringBuilder()
.append("?").append(url.getQuery()).toString() : "")
.toString());
}
/**
* 根据文件后缀名猜测文件MIME类型
* @param file
* @return
*/
protected static String guessType(File file) {
String name = file.getName();
String suffix = name.substring(name.lastIndexOf(".") + 1);
return (String) mimeMap.get(suffix.toLowerCase(Locale.ROOT));
}
/**
* 发送get请求
* @param url
*/
public static void doGet(String url) {
try {
doGet(new URL(url));
} catch (MalformedURLException e) {
warn(new StringBuilder().append("The specified URL ").append(url)
.append(" is not a valid URL. Please check").toString());
}
}
/**
* 发送get请求
* @param url
*/
public static void doGet(URL url) {
try {
if (mockMode) {
return;
}
HttpURLConnection urlc = (HttpURLConnection) url.openConnection();
if (url.getUserInfo() != null) {
String encoding = DatatypeConverter.printBase64Binary(url
.getUserInfo().getBytes(StandardCharsets.US_ASCII));
urlc.setRequestProperty("Authorization", new StringBuilder()
.append("Basic ").append(encoding).toString());
}
//开始请求Solr Admin后台
urlc.connect();
//验证是否请求成功
checkResponseCode(urlc);
} catch (IOException e) {
warn(new StringBuilder()
.append("An error occurred posting data to ").append(url)
.append(". Please check that Solr is running.").toString());
}
}
/**
* POST方式提交
* @param data
* @param length
* @param output
* @param type
* @param url
* @return
*/
public boolean postData(InputStream data, Integer length,
OutputStream output, String type, URL url) {
if (mockMode) {
return true;
}
boolean success = true;
if (type == null)
type = DEFAULT_CONTENT_TYPE;
HttpURLConnection urlc = null;
try {
try {
urlc = (HttpURLConnection) url.openConnection();
try {
//设置Http Method为 post
urlc.setRequestMethod("POST");
} catch (ProtocolException e) {
//如果Solr Admin端服务不支持POST请求,则打印异常信息
fatal(new StringBuilder()
.append("Shouldn't happen: HttpURLConnection doesn't support POST??")
.append(e).toString());
}
urlc.setDoOutput(true);
urlc.setDoInput(true);
urlc.setUseCaches(false);
urlc.setAllowUserInteraction(false);
urlc.setRequestProperty("Content-type", type);
if (url.getUserInfo() != null) {
String encoding = DatatypeConverter.printBase64Binary(url
.getUserInfo().getBytes(StandardCharsets.US_ASCII));
urlc.setRequestProperty(
"Authorization",
new StringBuilder().append("Basic ")
.append(encoding).toString());
}
if (null != length)
urlc.setFixedLengthStreamingMode(length.intValue());
urlc.connect();
} catch (IOException e) {
fatal(new StringBuilder()
.append("Connection error (is Solr running at ")
.append(this.solrUrl).append(" ?): ").append(e)
.toString());
success = false;
}
Throwable localThrowable3;
try {
OutputStream out = urlc.getOutputStream();
localThrowable3 = null;
try {
pipe(data, out);
} catch (Throwable localThrowable1) {
localThrowable3 = localThrowable1;
throw localThrowable1;
} finally {
if (out != null)
if (localThrowable3 != null) {
try {
out.close();
} catch (Throwable x2) {
localThrowable3.addSuppressed(x2);
}
} else {
out.close();
}
}
} catch (IOException e) {
fatal(new StringBuilder()
.append("IOException while posting data: ").append(e)
.toString());
success = false;
}
try {
success &= checkResponseCode(urlc);
InputStream in = urlc.getInputStream();
localThrowable3 = null;
try {
pipe(in, output);
} catch (Throwable localThrowable2) {
localThrowable3 = localThrowable2;
throw localThrowable2;
} finally {
if (in != null)
if (localThrowable3 != null)
try {
in.close();
} catch (Throwable x2) {
localThrowable3.addSuppressed(x2);
}
else
in.close();
}
} catch (IOException e) {
warn(new StringBuilder()
.append("IOException while reading response: ")
.append(e).toString());
success = false;
}
} finally {
if (urlc != null) {
urlc.disconnect();
}
}
return success;
}
/**
* 根据响应状态码判断是否提交成功了
* @param urlc
* @return
* @throws IOException
*/
private static boolean checkResponseCode(HttpURLConnection urlc)
throws IOException {
//响应状态码如果大于等于400,表示请求失败了
if (urlc.getResponseCode() >= 400) {
warn(new StringBuilder().append("Solr returned an error #")
.append(urlc.getResponseCode()).append(" (")
.append(urlc.getResponseMessage()).append(") for url: ")
.append(urlc.getURL()).toString());
Charset charset = StandardCharsets.ISO_8859_1;
String contentType = urlc.getContentType();
if (contentType != null) {
int idx = contentType.toLowerCase(Locale.ROOT).indexOf(
"charset=");
if (idx > 0) {
charset = Charset.forName(contentType.substring(
idx + "charset=".length()).trim());
}
}
InputStream errStream = urlc.getErrorStream();
Throwable localThrowable2 = null;
try {
if (errStream != null) {
BufferedReader br = new BufferedReader(
new InputStreamReader(errStream, charset));
StringBuilder response = new StringBuilder("Response: ");
int ch;
while ((ch = br.read()) != -1) {
response.append((char) ch);
}
warn(response.toString().trim());
}
} catch (Throwable localThrowable1) {
localThrowable2 = localThrowable1;
throw localThrowable1;
} finally {
if (errStream != null)
if (localThrowable2 != null)
try {
errStream.close();
} catch (Throwable x2) {
localThrowable2.addSuppressed(x2);
}
else
errStream.close();
}
return false;
}
return true;
}
/**
* 字符串转换成字节输入流
* @param s
* @return
*/
public static InputStream stringToStream(String s) {
return new ByteArrayInputStream(s.getBytes(StandardCharsets.UTF_8));
}
/**
* 把输入流传输到输出流上
* @param source
* @param dest
* @throws IOException
*/
private static void pipe(InputStream source, OutputStream dest)
throws IOException {
byte[] buf = new byte[1024];
int read = 0;
while ((read = source.read(buf)) >= 0) {
if (null != dest) {
dest.write(buf, 0, read);
}
}
if (null != dest) {
dest.flush();
}
}
/**
* 根据传入的fileType构建文件过滤器
* @param fileTypes
* @return
*/
public GlobFileFilter getFileFilterFromFileTypes(String fileTypes) {
String glob;
if (fileTypes.equals("*")) {
glob = ".*";
} else {
glob = new StringBuilder().append("^.*\\.(")
.append(fileTypes.replace(",", "|")).append(")$")
.toString();
}
return new GlobFileFilter(glob, true);
}
/**
* 根据XPath表达式获取XML节点
* @param n
* @param xpath
* @return
* @throws XPathExpressionException
*/
public static NodeList getNodesFromXP(Node n, String xpath)
throws XPathExpressionException {
XPathFactory factory = XPathFactory.newInstance();
XPath xp = factory.newXPath();
XPathExpression expr = xp.compile(xpath);
return (NodeList) expr.evaluate(n, XPathConstants.NODESET);
}
/**
* 根据XPath表达式获取XML节点
* @param n
* @param xpath
* @param concatAll 是否包含所有子节点,否则只取第一个
* @return
* @throws XPathExpressionException
*/
public static String getXP(Node n, String xpath, boolean concatAll)
throws XPathExpressionException {
NodeList nodes = getNodesFromXP(n, xpath);
StringBuilder sb = new StringBuilder();
if (nodes.getLength() > 0) {
for (int i = 0; i < nodes.getLength(); i++) {
sb.append(new StringBuilder()
.append(nodes.item(i).getNodeValue()).append(" ")
.toString());
if (!concatAll) {
break;
}
}
return sb.toString().trim();
}
return "";
}
/**
* 把字节数据转换为Document对象,为XML解析做准备
* @param in
* @return
* @throws SAXException
* @throws IOException
* @throws ParserConfigurationException
*/
public static Document makeDom(byte[] in) throws SAXException, IOException,
ParserConfigurationException {
InputStream is = new ByteArrayInputStream(in);
Document dom = DocumentBuilderFactory.newInstance()
.newDocumentBuilder().parse(is);
return dom;
}
static {
DATA_MODES.add("files");
DATA_MODES.add("args");
DATA_MODES.add("stdin");
DATA_MODES.add("web");
mimeMap = new HashMap<String, String>();
mimeMap.put("xml", "application/xml");
mimeMap.put("csv", "text/csv");
mimeMap.put("json", "application/json");
mimeMap.put("pdf", "application/pdf");
mimeMap.put("rtf", "text/rtf");
mimeMap.put("html", "text/html");
mimeMap.put("htm", "text/html");
mimeMap.put("doc", "application/msword");
mimeMap.put("docx",
"application/vnd.openxmlformats-officedocument.wordprocessingml.document");
mimeMap.put("ppt", "application/vnd.ms-powerpoint");
mimeMap.put("pptx",
"application/vnd.openxmlformats-officedocument.presentationml.presentation");
mimeMap.put("xls", "application/vnd.ms-excel");
mimeMap.put("xlsx",
"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
mimeMap.put("odt", "application/vnd.oasis.opendocument.text");
mimeMap.put("ott", "application/vnd.oasis.opendocument.text");
mimeMap.put("odp", "application/vnd.oasis.opendocument.presentation");
mimeMap.put("otp", "application/vnd.oasis.opendocument.presentation");
mimeMap.put("ods", "application/vnd.oasis.opendocument.spreadsheet");
mimeMap.put("ots", "application/vnd.oasis.opendocument.spreadsheet");
mimeMap.put("txt", "text/plain");
mimeMap.put("log", "text/plain");
}
public class PageFetcherResult {
int httpStatus = 200;
String contentType = "text/html";
URL redirectUrl = null;
ByteBuffer content;
public PageFetcherResult() {
}
}
/**
* 页面抓取类
* @author Lanxiaowei
*
*/
class PageFetcher {
Map<String, List<String>> robotsCache;
final String DISALLOW = "Disallow:";
public PageFetcher() {
this.robotsCache = new HashMap<String, List<String>>();
}
/**
* 根据指定的URL去抓取页面,页面内容包装在PageFetcherResult对象中
* @param u
* @return
*/
public PageFetcherResult readPageFromUrl(URL u) {
PageFetcherResult res = new PageFetcherResult();
try {
/**
* 如果当前URL在roots.txt的禁止爬取列表中,则直接跳过
*/
if (isDisallowedByRobots(u)) {
SimplePostTool
.warn("The URL "
+ u
+ " is disallowed by robots.txt and will not be crawled.");
res.httpStatus = 403;
SimplePostTool.this.visited.add(u);
return res;
}
res.httpStatus = 404;
HttpURLConnection conn = (HttpURLConnection) u.openConnection();
conn.setRequestProperty("User-Agent",
"SimplePostTool-crawler/5.1.0 (http://lucene.apache.org/solr/)");
conn.setRequestProperty("Accept-Encoding", "gzip, deflate");
conn.connect();
res.httpStatus = conn.getResponseCode();
if (!SimplePostTool
.normalizeUrlEnding(conn.getURL().toString())
.equals(SimplePostTool.normalizeUrlEnding(u.toString()))) {
SimplePostTool.info("The URL " + u
+ " caused a redirect to " + conn.getURL());
u = conn.getURL();
res.redirectUrl = u;
SimplePostTool.this.visited.add(u);
}
if (res.httpStatus == 200) {
String rawContentType = conn.getContentType();
String type = rawContentType.split(";")[0];
if (SimplePostTool.this.typeSupported(type)) {
String encoding = conn.getContentEncoding();
InputStream is = null;
if ((encoding != null)
&& (encoding.equalsIgnoreCase("gzip"))) {
is = new GZIPInputStream(conn.getInputStream());
} else {
if ((encoding != null)
&& (encoding.equalsIgnoreCase("deflate")))
is = new InflaterInputStream(
conn.getInputStream(), new Inflater(
true));
else {
is = conn.getInputStream();
}
}
BAOS bos = new BAOS();
res.content = SimplePostTool.inputStreamToByteArray(bos,is);
is.close();
bos.close();
} else {
SimplePostTool
.warn("Skipping URL with unsupported type "
+ type);
res.httpStatus = 415;
}
}
} catch (IOException e) {
SimplePostTool.warn("IOException when reading page from url "
+ u + ": " + e.getMessage());
}
return res;
}
/**
* 根据roots.txt信息判断指定URL是否可以抓取
* @param url
* @return
*/
public boolean isDisallowedByRobots(URL url) {
String host = url.getHost();
//拼接网站的roots.txt访问地址
String strRobot = url.getProtocol() + "://" + host + "/robots.txt";
//先从缓存中获取当前网站的roots信息
List<String> disallows = (List<String>) this.robotsCache.get(host);
//若缓存中没有
if (disallows == null) {
disallows = new ArrayList<String>();
try {
//则根据拼接的roots.txt访问地址去解析获取
URL urlRobot = new URL(strRobot);
//解析roots信息
disallows = parseRobotsTxt(urlRobot.openStream());
} catch (MalformedURLException e) {
return true;
} catch (IOException e) {
}
}
//缓存到 map中
this.robotsCache.put(host, disallows);
//判断是否存在于roots的禁爬列表中
String strURL = url.getFile();
for (String path : disallows) {
if ((path.equals("/")) || (strURL.indexOf(path) == 0)) {
return true;
}
}
//return false即表示不是禁爬URL
return false;
}
/**
* 根据roots.txt输入流解析roots信息,存入list中,一般是一行一条url
* @param is
* @return
* @throws IOException
*/
protected List<String> parseRobotsTxt(InputStream is)
throws IOException {
List<String> disallows = new ArrayList<String>();
BufferedReader r = new BufferedReader(new InputStreamReader(is,
StandardCharsets.UTF_8));
String l;
while ((l = r.readLine()) != null) {
String[] arr = l.split("#");
if (arr.length != 0) {
l = arr[0].trim();
//我们只关心禁爬URL信息,Disallow不允许的意思即禁爬
if (l.startsWith("Disallow:")) {
l = l.substring("Disallow:".length()).trim();
if (l.length() != 0) {
disallows.add(l);
}
}
}
}
is.close();
return disallows;
}
/**
* 从抓取到的页面内容中提取出URL
* @param u
* @param is
* @param type
* @param postUrl
* @return
*/
protected Set<URL> getLinksFromWebPage(URL u, InputStream is,
String type, URL postUrl) {
Set<URL> l = new HashSet<URL>();
URL url = null;
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
URL extractUrl = new URL(SimplePostTool.appendParam(
postUrl.toString(), "extractOnly=true"));
boolean success = SimplePostTool.this.postData(is, null, os,
type, extractUrl);
if (success) {
Document d = SimplePostTool.makeDom(os.toByteArray());
String innerXml = SimplePostTool.getXP(d,
"/response/str/text()[1]", false);
d = SimplePostTool.makeDom(innerXml
.getBytes(StandardCharsets.UTF_8));
//这个XPath表达式表示:获取html标签下的body标签下的所有a标签的href属性值
NodeList links = SimplePostTool.getNodesFromXP(d,
"/html/body//a/@href");
for (int i = 0; i < links.getLength(); i++) {
String link = links.item(i).getTextContent();
link = SimplePostTool.this.computeFullUrl(u, link);
if (link != null) {
url = new URL(link);
if ((url.getAuthority() != null)
&& (url.getAuthority().equals(u
.getAuthority()))) {
l.add(url);
}
}
}
}
} catch (MalformedURLException e) {
SimplePostTool.warn("Malformed URL " + url);
} catch (IOException e) {
SimplePostTool.warn("IOException opening URL " + url + ": "
+ e.getMessage());
} catch (Exception e) {
throw new RuntimeException();
}
return l;
}
}
/**
* 自定义文件过滤器
* @author Lanxiaowei
*
*/
class GlobFileFilter implements FileFilter {
private String _pattern;
private Pattern p;
/**
* isRegex用来表示第一个参数pattern是否为一个正则表达式
* @param pattern
* @param isRegex
*/
public GlobFileFilter(String pattern, boolean isRegex) {
this._pattern = pattern;
//如果pattern参数不是一个正则表达式
if (!isRegex) {
//不是正则表达式的话,则需要对正则表达式里的特殊字符进行转义,所以这里的处理就不言自明了
this._pattern = this._pattern.replace("^", "\\^")
.replace("$", "\\$").replace(".", "\\.")
.replace("(", "\\(").replace(")", "\\)")
.replace("+", "\\+").replace("*", ".*")
.replace("?", ".");
//经过上一步处理后this._pattern参数就被当作一个普通的文件名了,
//再在开头加^结尾加$转换成正则表达式
this._pattern = ("^" + this._pattern + "$");
}
try {
//这里的2即Pattern.CASE_INSENSITIVE即忽略大小写的意思
this.p = Pattern.compile(this._pattern, 2);
} catch (PatternSyntaxException e) {
SimplePostTool.fatal("Invalid type list " + pattern + ". "
+ e.getDescription());
}
}
/**根据正则表达式匹配结果判断是否返回这个文件*/
public boolean accept(File file) {
return this.p.matcher(file.getName()).find();
}
}
/**
* 自定义字节输出流
* @author Administrator
*
*/
public static class BAOS extends ByteArrayOutputStream {
//把输出流存入ByteBuffer字节缓冲区中,因为ByteBuffer比byte[]读写效率要高
public ByteBuffer getByteBuffer() {
return ByteBuffer.wrap(this.buf, 0, this.count);
}
}
}
看懂了post.jar的源码,有助于你更熟练使用post.jar来进行索引的添加删除等操作,下面截图演示如何在eclipse下运行SimplePostTool类进行索引测试操作,如图:
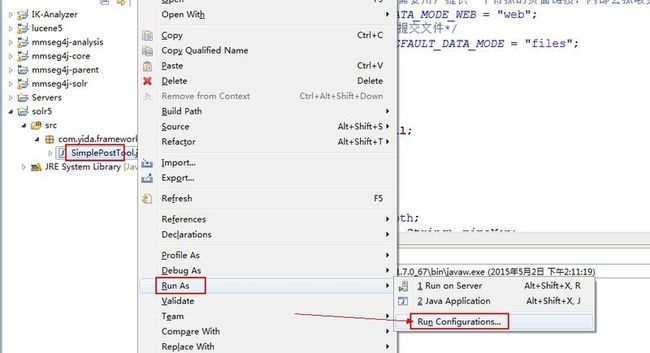
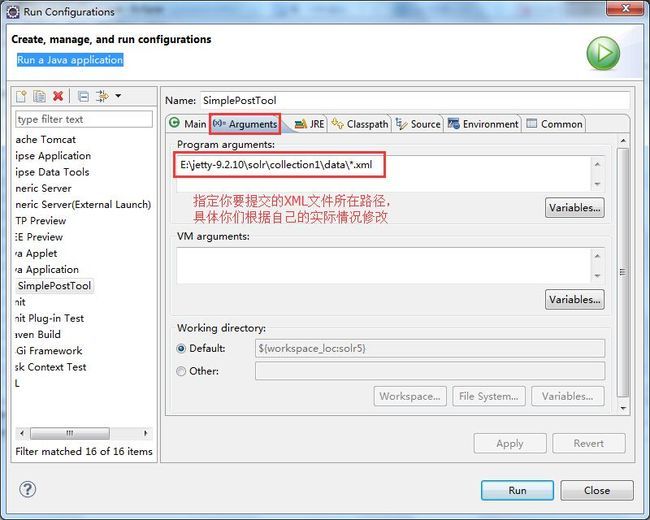
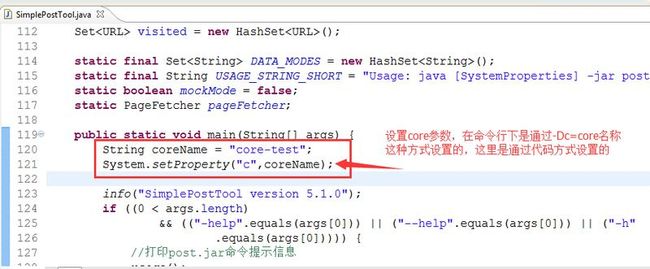
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!