hadoop学习--HDFS
hadoop fs -ls / hdfs dfs -ls / #操作命令
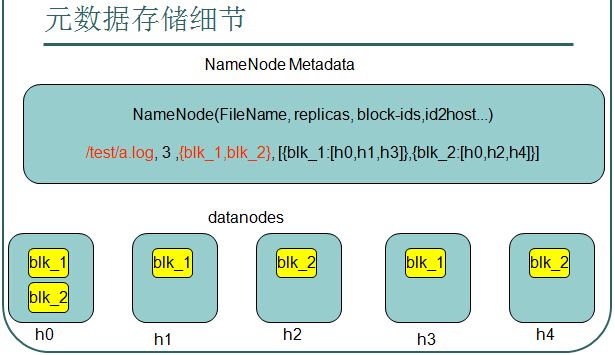
1、架构

下图表示/test/a.log这个文件保存3个副本,该文件有blk_1,blk_2两个块,
第一个块保存在h0,h1,h3这3个服务器中,
第二个块保存在h0,h2,h4这3个服务器中。。
2、HDFS基础数据
NameNode是整个文件系统的管理节点;它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表;接收用户的操作请求。
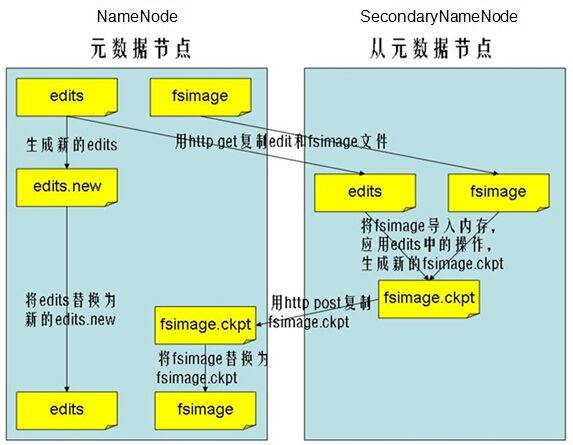
以下这些文件是HDFS的关键元素,,,,并且保存在linux的文件系统中:
fsimage:元数据镜像文件,存储某一时段NameNode内存元数据信息
edits:操作日志文件
fstime:保存最近一次checkpoint的时间
a、Namenode始终在内存中保存metedata,用于处理“读请求”
b、当有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
c、Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容
d、Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
HDFS--CRUD
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test;
public class DfsTest {
private FileSystem fs = null;
private Path f = new Path("/words");
@Before
public void before(){
try {
fs = FileSystem.get(new URI("hdfs://jzk:9000"), new Configuration(), "jzk");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
@Test
public void upload(){
try {
FSDataOutputStream out = fs.create(f, (short)1);
FileInputStream in = new FileInputStream(new File("/home/jzk/tmp/words"));
IOUtils.copyBytes(in, out, 4096, true);
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void download(){
try {
FSDataInputStream in = fs.open(f);
FileOutputStream out = new FileOutputStream(new File("/home/jzk/tmp/words1"));
IOUtils.copyBytes(in, out, 4096, true);
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void append(){
try {
FSDataOutputStream out = fs.exists(f) ? fs.append(f, 4096) : fs.create(f, (short)1);
FileInputStream in = new FileInputStream(new File("/home/jzk/tmp/words"));
IOUtils.copyBytes(in, out, 4096, true);
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void del(){
try {
fs.delete(f, true);
} catch (IOException e) {
e.printStackTrace();
}
}
}