使用 Drools 规则引擎实现业务逻辑
转自:http://www.ibm.com/developerworks/cn/java/j-drools/#ibm-pcon
使用 Drools 规则引擎实现业务逻辑
使用声明性编程方法编写程序的业务逻辑
简介: 使用规则引擎可以通过降低实现复杂业务逻辑的组件的复杂性,降低应用程序的维护和可扩展性成本。这篇更新的文章展示如何使用开源的 Drools 规则引擎让 Java™ 应用程序更适应变化。Drools 项目引入了一个新的本地规则表达式语言和一个 Eclipse 插件,使 Drools 比以前更容易使用。
要求施加在当今软件产品上的大多数复杂性是行为和功能方面的,从而导致组件实现具有复杂的业务逻辑。实现 J2EE 或 J2SE 应用程序中业务逻辑最常见的方法是编写 Java 代码来实现需求文档的规则和逻辑。在大多数情况下,该代码的错综复杂性使得维护和更新应用程序的业务逻辑成为一项令人畏惧的任务,甚至对于经验丰富的开发人员来说也是如此。任何更改,不管多么简单,仍然会产生重编译和重部署成本。
规则引擎试图解决(或者至少降低)应用程序业务逻辑的开发和维护中固有的问题和困难。可以将规则引擎看作实现复杂业务逻辑的框架。大多数规则引擎允许您使用声明性编程来表达对于某些给定信息或知识有效的结果。您可以专注于已知为真的事实及其结果,也就是应用程序的业务逻辑。
有多个规则引擎可供使用,其中包括商业和开放源码选择。商业规则引擎通常允许使用专用的类似英语的语言来表达规则。其他规则引擎允许使用脚本语言(比如 Groovy 或 Python)编写规则。这篇更新的文章为您介绍 Drools 引擎,并使用示例程序帮助您理解如何使用 Drools 作为 Java 应用程序中业务逻辑层的一部分。
Drools 是用 Java 语言编写的开放源码规则引擎,使用 Rete 算法(参阅 参考资料)对所编写的规则求值。Drools 允许使用声明方式表达业务逻辑。可以使用非 XML 的本地语言编写规则,从而便于学习和理解。并且,还可以将 Java 代码直接嵌入到规则文件中,这令 Drools 的学习更加吸引人。Drools 还具有其他优点:
- 非常活跃的社区支持
- 易用
- 快速的执行速度
- 在 Java 开发人员中流行
- 与 Java Rule Engine API(JSR 94)兼容(参阅 参考资料)
- 免费
在编写本文之际,Drools 规则引擎的最新版本是 4.0.4。这是一个重要更新。虽然现在还存在一些向后兼容性问题,但这个版本的特性让 Drools 比以前更有吸引力。例如,用于表达规则的新的本地语言比旧版本使用的 XML 格式更简单,更优雅。这种新语言所需的代码更少,并且格式易于阅读。
另一个值得注意的进步是,新版本提供了用于 Eclipse IDE(Versions 3.2 和 3.3)的一个 Drools 插件。我强烈建议您通过这个插件来使用 Drools。它可以简化使用 Drools 的项目开发,并且可以提高生产率。例如,该插件会检查规则文件是否有语法错误,并提供代码完成功能。它还使您可以调试规则文件,将调试时间从数小时减少到几分钟。您可以在规则文件中添加断点,以便在规则执行期间的特定时刻检查对象的状态。这使您可以获得关于规则引擎在特定时刻所处理的知识(knowledge)(在本文的后面您将熟悉这个术语)的信息。
本文展示如何使用 Drools 作为示例 Java 应用程序中业务逻辑层的一部分。为了理解本文,您应该熟悉使用 Eclipse IDE 开发和调试 Java 代码。并且,您还应该熟悉 JUnit 测试框架,并知道如何在 Eclipse 中使用它。
下列假设为应用程序解决的虚构问题设置了场景:
- 名为 XYZ 的公司构建两种类型的计算机机器:Type1 和 Type2。机器类型按其架构定义。
- XYZ 计算机可以提供多种功能。当前定义了四种功能:DDNS Server、DNS Server、Gateway 和 Router。
- 在发运每台机器之前,XYZ 在其上执行多个测试。
- 在每台机器上执行的测试取决于每台机器的类型和功能。目前,定义了五种测试:Test1、Test2、Test3、Test4 和 Test5。
- 当将测试分配给一台计算机时,也将测试到期日期 分配给该机器。分配给计算机的测试不能晚于该到期日期执行。到期日期值取决于分配给机器的测试。
- XYZ 使用可以确定机器类型和功能的内部开发的软件应用程序,自动化了执行测试时的大部分过程。然后,基于这些属性,应用程序确定要执行的测试及其到期日期。
- 目前,为计算机分配测试和测试到期日期的逻辑是该应用程序的已编译代码的一部分。包含该逻辑的组件用 Java 语言编写。
- 分配测试和到期日期的逻辑一个月更改多次。当开发人员需要使用 Java 代码实现该逻辑时,必须经历一个冗长乏味的过程。
因为在对为计算机分配测试和到期日期的逻辑进行更改时,公司会发生高额成本,所以 XYZ 主管已经要求软件工程师寻找一种灵活的方法,用最少的代价将对业务规则的更改 “推” 至生产环境。于是 Drools 走上舞台了。工程师决定,如果它们使用规则引擎来表达确定哪些测试应该执行的规则,则可以节省更多时间和精力。他们将只需要更改规则文件的内容,然后在生产环境中替换该文件。对于他们来说,这比更改已编译代码并在将已编译代码部署到生产环境中时进行由组织强制的冗长过程要简单省时得多(参阅侧栏 何时使用规则引擎?)。
目前,在为机器分配测试和到期日期时必须遵循以下业务规则:
- 如果计算机是 Type1,则只能在其上执行 Test1、Test2 和 Test5。
- 如果计算机是 Type2 且其中一个功能为 DNS Server,则应执行 Test4 和 Test5。
- 如果计算机是 Type2 且其中一个功能为 DDNS Server,则应执行 Test2 和 Test3。
- 如果计算机是 Type2 且其中一个功能为 Gateway,则应执行 Test3 和 Test4。
- 如果计算机是 Type2 且其中一个功能为 Router,则应执行 Test1 和 Test3。
- 如果 Test1 是要在计算机上执行的测试之一,则测试到期日期距离机器的创建日期 3 天。该规则优先于测试到期日期的所有下列规则。
- 如果 Test2 是要在计算机上执行的测试之一,则测试到期日期距离机器的创建日期 7 天。该规则优先于测试到期日期的所有下列规则。
- 如果 Test3 是要在计算机上执行的测试之一,则测试到期日期距离机器的创建日期 10 天。该规则优先于测试到期日期的所有下列规则。
- 如果 Test4 是要在计算机上执行的测试之一,则测试到期日期距离机器的创建日期 12 天。该规则优先于测试到期日期的所有下列规则。
- 如果 Test5 是要在计算机上执行的测试之一,则测试到期日期距离机器的创建日期 14 天。
捕获为机器分配测试和测试到期日期的上述业务规则的当前 Java 代码如清单 1 所示:
Machine machine = ...
// Assign tests
Collections.sort(machine.getFunctions());
int index;
if (machine.getType().equals("Type1")) {
Test test1 = ...
Test test2 = ...
Test test5 = ...
machine.getTests().add(test1);
machine.getTests().add(test2);
machine.getTests().add(test5);
} else if (machine.getType().equals("Type2")) {
index = Collections.binarySearch(machine.getFunctions(), "Router");
if (index >= 0) {
Test test1 = ...
Test test3 = ...
machine.getTests().add(test1);
machine.getTests().add(test3);
}
index = Collections.binarySearch(machine.getFunctions(), "Gateway");
if (index >= 0) {
Test test4 = ...
Test test3 = ...
machine.getTests().add(test4);
machine.getTests().add(test3);
}
...
}
// Assign tests due date
Collections.sort(machine.getTests(), new TestComparator());
...
Test test1 = ...
index = Collections.binarySearch(machine.getTests(), test1);
if (index >= 0) {
// Set due date to 3 days after Machine was created
Timestamp creationTs = machine.getCreationTs();
machine.setTestsDueTime(...);
return;
}
index = Collections.binarySearch(machine.getTests(), test2);
if (index >= 0) {
// Set due date to 7 days after Machine was created
Timestamp creationTs = machine.getCreationTs();
machine.setTestsDueTime(...);
return;
}
...
|
清单 1 中的代码不是太复杂,但也并不简单。如果要对其进行更改,需要十分小心。一堆互相缠绕的 if-else 语句正试图捕获已经为应用程序标识的业务逻辑。如果您对业务规则不甚了解,就无法一眼看出代码的意图。
使用 Drools 规则的示例程序附带在本文的 ZIP 存档中。程序使用 Drools 规则文件以声明方法表示上一节定义的业务规则。它包含一个 Eclipse 3.2 Java 项目,该项目是使用 Drools 插件和 4.0.4 版的 Drools 规则引擎开发的。请遵循以下步骤设置示例程序:
- 下载 ZIP 存档(参见 下载)。
- 下载并安装 Drools Eclipse 插件(参见 参考资料)。
- 在 Eclipse 中,选择该选项以导入 Existing Projects into Workspace,如图 1 所示:
图 1. 将示例程序导入到 Eclipse 工作区
- 然后选择下载的存档文件并将其导入工作区中。您将在工作区中发现一个名为
DroolsDemo的新 Java 项目,如图 2 所示:
图 2. 导入到工作区中的示例程序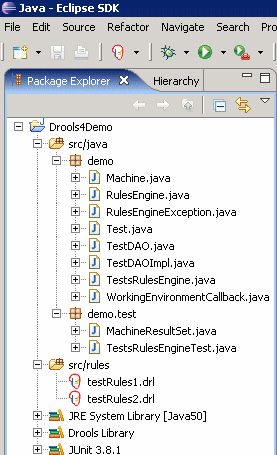
如果启用了 Build automatically 选项,则代码应该已编译并可供使用。如果未启用该选项,则现在构建 DroolsDemo 项目。
现在来看一下示例程序中的代码。该程序的 Java 类的核心集合位于 demo 包中。在该包中可以找到 Machine 和 Test 域对象类。Machine 类的实例表示要分配测试和测试到期日期的计算机机器。下面来看 Machine 类,如清单 2 所示:
public class Machine {
private String type;
private List functions = new ArrayList();
private String serialNumber;
private Collection tests = new HashSet();
private Timestamp creationTs;
private Timestamp testsDueTime;
public Machine() {
super();
this.creationTs = new Timestamp(System.currentTimeMillis());
}
...
|
在清单 2 中可以看到 Machine 类的属性有:
-
type(表示为string属性)—— 保存机器的类型值。 -
functions(表示为list)—— 保存机器的功能。 -
testsDueTime(表示为timestamp变量)—— 保存分配的测试到期日期值。 -
tests(Collection对象)—— 保存分配的测试集合。
注意,可以为机器分配多个测试,而且一个机器可以具有一个或多个功能。
出于简洁目的,机器的创建日期值设置为创建 Machine 类的实例时的当前时间。如果这是真实的应用程序,创建时间将设置为机器最终构建完成并准备测试的实际时间。
Test 类的实例表示可以分配给机器的测试。Test实例由其 id 和 name 惟一描述,如清单 3 所示:
public class Test {
public static Integer TEST1 = new Integer(1);
public static Integer TEST2 = new Integer(2);
public static Integer TEST3 = new Integer(3);
public static Integer TEST4 = new Integer(4);
public static Integer TEST5 = new Integer(5);
private Integer id;
private String name;
private String description;
public Test() {
super();
}
...
|
示例程序使用 Drools 规则引擎对 Machine 类的实例求值。基于 Machine 实例的 type 和 functions 属性的值,规则引擎确定应分配给tests 和 testsDueTime 属性的值。
在 demo 包中,还会发现 Test 对象的数据访问对象 (TestDAOImpl) 的实现,它允许您按照 ID 查找 Test 实例。该数据访问对象极其简单;它不连接任何外部资源(比如关系数据库)以获得 Test 实例。相反,在其定义中硬编码了预定义的 Test 实例集合。在现实世界中,您可能会具有连接外部资源以检索 Test 对象的数据访问对象。
demo 中比较重要(如果不是最重要的)的一个类是 RulesEngine 类。该类的实例用作封装逻辑以访问 Drools 类的包装器对象。可以在您自己的 Java 项目中容易地重用该类,因为它所包含的逻辑不是特定于示例程序的。清单 4 展示了该类的属性和构造函数:
public class RulesEngine {
private RuleBase rules;
private boolean debug = false;
public RulesEngine(String rulesFile) throws RulesEngineException {
super();
try {
// Read in the rules source file
Reader source = new InputStreamReader(RulesEngine.class
.getResourceAsStream("/" + rulesFile));
// Use package builder to build up a rule package
PackageBuilder builder = new PackageBuilder();
// This parses and compiles in one step
builder.addPackageFromDrl(source);
// Get the compiled package
Package pkg = builder.getPackage();
// Add the package to a rulebase (deploy the rule package).
rules = RuleBaseFactory.newRuleBase();
rules.addPackage(pkg);
} catch (Exception e) {
throw new RulesEngineException(
"Could not load/compile rules file: " + rulesFile, e);
}
}
...
|
在清单 4 中可以看到,RulesEngine 类的构造函数接受字符串值形式的参数,该值表示包含业务规则集合的文件的名称。该构造函数使用 PackageBuilder 类的实例解析和编译源文件中包含的规则。(注意: 该代码假设规则文件位于程序类路径中名为 rules 的文件夹中。)然后,使用 PackageBuilder 实例将所有编译好的规则合并为一个二进制 Package 实例。然后,使用这个实例配置 DroolsRuleBase 类的一个实例,后者被分配给 RulesEngine 类的 rules 属性。可以将这个类的实例看作规则文件中所包含规则的内存中表示。
清单 5 展示了 RulesEngine 类的 executeRules() 方法:
清单 5. RulesEngine 类的 executeRules() 方法
public void executeRules(WorkingEnvironmentCallback callback) {
WorkingMemory workingMemory = rules.newStatefulSession();
if (debug) {
workingMemory
.addEventListener(new DebugWorkingMemoryEventListener());
}
callback.initEnvironment(workingMemory);
workingMemory.fireAllRules();
}
|
executeRules() 方法几乎包含了 Java 代码中的所有魔力。调用该方法执行先前加载到类构造函数中的规则。Drools WorkingMemory类的实例用于断言或声明知识,规则引擎应使用它来确定应执行的结果。(如果满足规则的所有条件,则执行该规则的结果。)将知识当作规则引擎用于确定是否应启动规则的数据或信息。例如,规则引擎的知识可以包含一个或多个对象及其属性的当前状态。
规则结果在调用 WorkingMemory 对象的 fireAllRules() 方法时执行。您可能奇怪(我希望您如此)知识是如何插入到 WorkingMemory实例中的。如果仔细看一下该方法的签名,将会注意到所传递的参数是 WorkingEnvironmentCallback 接口的实例。executeRules()方法的调用者需要创建实现该接口的对象。该接口只需要开发人员实现一个方法(参见清单 6 ):
清单 6. WorkingEnvironmentCallback 接口
public interface WorkingEnvironmentCallback {
void initEnvironment(WorkingMemory workingMemory) throws FactException;
}
|
所以,应该是 executeRules() 方法的调用者将知识插入到 WorkingMemory 实例中的。稍后将展示这是如何实现的。
清单 7 展示了 TestsRulesEngine 类,它也位于 demo 包中:
public class TestsRulesEngine {
private RulesEngine rulesEngine;
private TestDAO testDAO;
public TestsRulesEngine(TestDAO testDAO) throws RulesEngineException {
super();
rulesEngine = new RulesEngine("testRules1.drl");
this.testDAO = testDAO;
}
public void assignTests(final Machine machine) {
rulesEngine.executeRules(new WorkingEnvironmentCallback() {
public void initEnvironment(WorkingMemory workingMemory) {
// Set globals first before asserting/inserting any knowledge!
workingMemory.setGlobal("testDAO", testDAO);
workingMemory.insert(machine);
};
});
}
}
|
TestsRulesEngine 类只有两个实例变量。rulesEngine 属性是 RulesEngine 类的实例。 testDAO 属性保存对 TestDAO 接口的具体实现的引用。 rulesEngine 对象是使用 "testRules1.drl" 字符串作为其构造函数的参数实例化的。testRules1.drl 文件以声明方式捕获要解决的问题 中的业务规则。 TestsRulesEngine 类的 assignTests() 方法调用 RulesEngine 类的 executeRules() 方法。在这个方法中,创建了 WorkingEnvironmentCallback 接口的一个匿名实例,然后将该实例作为参数传递给 executeRules() 方法。
如果查看 assignTests() 方法的实现,可以看到知识是如何插入到 WorkingMemory 实例中的。 WorkingMemory 类的 insert() 方法被调用以声明在对规则求值时规则引擎应使用的知识。在这种情况下,知识由 Machine 类的一个实例组成。被插入的对象用于对规则的条件求值。
如果在对条件求值时,需要让规则引擎引用未 用作知识的对象,则应使用 WorkingMemory 类的 setGlobal() 方法。在示例程序中,setGlobal() 方法将对 TestDAO 实例的引用传递给规则引擎。然后规则引擎使用 TestDAO 实例查找它可能需要的任何 Test 实例。
TestsRulesEngine 类是示例程序中惟一的 Java 代码,它包含专门致力于为机器分配测试和测试到期日期的实现的逻辑。该类中的逻辑永远不需要更改,即使业务规则需要更新时也是如此。
如前所述,testRules.xml 文件包含规则引擎为机器分配测试和测试到期日期所遵循的规则。它使用 Drools 本地语言表达所包含的规则。
Drools 规则文件有一个或多个 rule 声明。每个 rule 声明由一个或多个 conditional 元素以及要执行的一个或多个 consequences 或actions 组成。一个规则文件还可以有多个(即 0 个或多个)import 声明、多个 global 声明以及多个 function 声明。
理解 Drools 规则文件组成最好的方法是查看一个真正的规则文件。下面来看 testRules1.drl 文件的第一部分,如清单 8 所示:
package demo; import demo.Machine; import demo.Test; import demo.TestDAO; import java.util.Calendar; import java.sql.Timestamp; global TestDAO testDAO; |
在清单 8 中,可以看到 import 声明如何让规则执行引擎知道在哪里查找将在规则中使用的对象的类定义。global 声明让规则引擎知道,某个对象应该可以从规则中访问,但该对象不应是用于对规则条件求值的知识的一部分。可以将 global 声明看作规则中的全局变量。对于 global 声明,需要指定它的类型(即类名)和想要用于引用它的标识符(即变量名)。global 声明中的这个标识符名称应该与调用 WorkingMemory 类的 setGlobal() 方法时使用的标识符值匹配,在此即为 testDAO (参见 清单 7)。
function 关键词用于定义一个 Java 函数(参见 清单 9)。如果看到 consequence(稍后将讨论)中重复的代码,则应该提取该代码并将其编写为一个 Java 函数。但是,这样做时要小心,避免在 Drools 规则文件中编写复杂的 Java 代码。规则文件中定义的 Java 函数应该简短易懂。这不是 Drools 的技术限制。如果想要在规则文件中编写复杂的 Java 代码,也可以。但这样做可能会让您的代码更加难以测试、调试和维护。复杂的 Java 代码应该是 Java 类的一部分。如果需要 Drools 规则执行引擎调用复杂的 Java 代码,则可以将对包含复杂代码的 Java 类的引用作为全局数据传递给规则引擎。
清单 9. testRules1.drl 文件中定义的 Java 函数
function void setTestsDueTime(Machine machine, int numberOfDays) {
setDueTime(machine, Calendar.DATE, numberOfDays);
}
function void setDueTime(Machine machine, int field, int amount) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(machine.getCreationTs());
calendar.add(field, amount);
machine.setTestsDueTime(new Timestamp(calendar.getTimeInMillis()));
}
...
|
清单 10 展示了 testRules1.drl 文件中定义的第一个规则:
清单 10. testRules1.drl 中定义的第一个规则
rule "Tests for type1 machine" salience 100 when machine : Machine( type == "Type1" ) then Test test1 = testDAO.findByKey(Test.TEST1); Test test2 = testDAO.findByKey(Test.TEST2); Test test5 = testDAO.findByKey(Test.TEST5); machine.getTests().add(test1); machine.getTests().add(test2); machine.getTests().add(test5); insert( test1 ); insert( test2 ); insert( test5 ); end |
如清单 10 所示,rule 声明有一个惟一标识它的 name。还可以看到,when 关键词定义规则中的条件块,then 关键词定义结果块。清单 10 中显示的规则有一个引用 Machine 对象的条件元素。如果回到 清单 7 可以看到, Machine 对象被插入到 WorkingMemory 对象中。这正是这个规则中使用的对象。条件元素对 Machine 实例(知识的一部分)求值,以确定是否应执行规则的结果。如果条件元素等于 true,则启动或执行结果。从清单 10 中还可以看出,结果只不过是一个 Java 语言语句。通过快速浏览该规则,可以很容易地识别出这是下列业务规则的实现:
- 如果计算机是 Type1,则只能在该机器上执行 Test1、Test2 和 Test5。
因此,该规则的条件元素检查( Machine 对象的) type 属性是否为 Type1。 (在条件元素中,只要对象遵从 Java bean 模式,就可以直接访问对象的属性,而不必调用 getter 方法。)如果该属性的值为 true,那么将 Machine 实例的一个引用分配给 machine 标识符。然后,在规则的结果块使用该引用,将测试分配给 Machine 对象。
在该规则中,惟一看上去有些奇怪的语句是最后三条结果语句。回忆 “要解决的问题” 小节中的业务规则,应该分配为测试到期日期的值取决于分配给机器的测试。因此,分配给机器的测试需要成为规则执行引擎在对规则求值时所使用的知识的一部分。这正是这三条语句的作用。这些语句使用一个名为 insert 的方法更新规则引擎中的知识。
规则的另一个重要的方面是可选的 salience 属性。使用它可以让规则执行引擎知道应该启动规则的结果语句的顺序。具有最高显著值的规则的结果语句首先执行;具有第二高显著值的规则的结果语句第二执行,依此类推。当您需要让规则按预定义顺序启动时,这一点非常重要,很快您将会看到。
testRules1.drl 文件中接下来的四个规则实现与机器测试分配有关的其他业务规则(参见清单 11)。这些规则与刚讨论的第一个规则非常相似。注意,salience 属性值对于前五个规则是相同的;不管这五个规则的启动顺序如何,其执行结果将相同。如果结果受规则的启动顺序影响,则需要为规则指定不同的显著值。
清单 11. testRules1.drl 文件中与测试分配有关的其他规则
rule "Tests for type2, DNS server machine" salience 100 when machine : Machine( type == "Type2", functions contains "DNS Server") then Test test5 = testDAO.findByKey(Test.TEST5); Test test4 = testDAO.findByKey(Test.TEST4); machine.getTests().add(test5); machine.getTests().add(test4); insert( test4 ); insert( test5 ); end rule "Tests for type2, DDNS server machine" salience 100 when machine : Machine( type == "Type2", functions contains "DDNS Server") then Test test2 = testDAO.findByKey(Test.TEST2); Test test3 = testDAO.findByKey(Test.TEST3); machine.getTests().add(test2); machine.getTests().add(test3); insert( test2 ); insert( test3 ); end rule "Tests for type2, Gateway machine" salience 100 when machine : Machine( type == "Type2", functions contains "Gateway") then Test test3 = testDAO.findByKey(Test.TEST3); Test test4 = testDAO.findByKey(Test.TEST4); machine.getTests().add(test3); machine.getTests().add(test4); insert( test3 ); insert( test4 ); end rule "Tests for type2, Router machine" salience 100 when machine : Machine( type == "Type2", functions contains "Router") then Test test3 = testDAO.findByKey(Test.TEST3); Test test1 = testDAO.findByKey(Test.TEST1); machine.getTests().add(test3); machine.getTests().add(test1); insert( test1 ); insert( test3 ); end ... |
清单 12 展示了 Drools 规则文件中的其他规则。您可能已经猜到,这些规则与测试到期日期的分配有关:
清单 12. testRules1.drl 文件中与测试到期日期分配有关的规则
rule "Due date for Test 5" salience 50 when machine : Machine() Test( id == Test.TEST5 ) then setTestsDueTime(machine, 14); end rule "Due date for Test 4" salience 40 when machine : Machine() Test( id == Test.TEST4 ) then setTestsDueTime(machine, 12); end rule "Due date for Test 3" salience 30 when machine : Machine() Test( id == Test.TEST3 ) then setTestsDueTime(machine, 10); end rule "Due date for Test 2" salience 20 when machine : Machine() Test( id == Test.TEST2 ) then setTestsDueTime(machine, 7); end rule "Due date for Test 1" salience 10 when machine : Machine() Test( id == Test.TEST1 ) then setTestsDueTime(machine, 3); end |
这些规则的实现比用于分配测试的规则的实现要略微简单一些,但我发现它们更有趣一些,原因有四。
第一,注意这些规则的执行顺序很重要。结果(即,分配给 Machine 实例的 testsDueTime 属性的值)受这些规则的启动顺序所影响。如果查看 要解决的问题 中详细的业务规则,您将注意到用于分配测试到期日期的规则具有优先顺序。例如,如果已经将 Test3、Test4 和 Test5 分配给机器,则测试到期日期应距离机器的创建日期 10 天。原因在于 Test3 的到期日期规则优先于 Test4 和 Test5 的测试到期日期规则。如何在 Drools 规则文件中表达这一点呢?答案是 salience 属性。为 testsDueTime 属性设置值的规则的salience 属性值不同。Test1 的测试到期日期规则优先于所有其他测试到期日期规则,所以这应是要启动的最后一个规则。换句话说,如果 Test1 是分配给机器的测试之一,则由该规则分配的值应该是优先使用的值。所以,该规则的 salience 属性值最低:10。
第二,每个规则有两个条件元素。第一个元素只检查工作内存中是否存在一个 Machine 实例。(注意,这里不会对 Machine 对象的属性进行比较。)当这个元素等于 true 时,它将一个引用分配给 Machine 对象,而后者将在规则的结果块被用到。如果不分配这个引用,那么就无法将测试到期日期分配给 Machine 对象。第二个条件元素检查 Test 对象的 id 属性。当且仅当这两个条件元素都等于true 时,才执行规则的结果元素。
第三,在 Test 类的一个实例成为知识的一部分(即,包含在工作内存中)之前,Drools 规则执行引擎不会(也不能)对这些规则的条件块求值。这很符合逻辑,因为如果工作内存中还没有 Test 类的一个实例,那么规则执行引擎就无法执行这些规则的条件中所包含的比较。如果您想知道 Test 实例何时成为知识的一部分,那么可以回忆,在与分配测试相关规则的结果的执行期间,一个或多个Test 实例被插入到工作内存中。(参见 清单 10 和 清单 11)。
第四,注意这些规则的结果块相当简短。原因在于在所有结果块中调用了规则文件中之前使用 function 关键词定义的setTestsDueTime() Java 方法。该方法为 testsDueTime 属性实际分配值。
既然已经仔细检查了实现业务规则逻辑的代码,现在应该检查它是否能工作。要执行示例程序,运行 demo.test 中的TestsRulesEngineTest JUnit 测试。
在该测试中,创建了 5 个 Machine 对象,每个对象具有不同的属性集合(序号、类型和功能)。为这五个 Machine 对象的每一个都调用 TestsRulesEngine 类的 assignTests() 方法。一旦 assignTests() 方法完成其执行,就执行断言以验证 testRules1.drl 中指定的业务规则逻辑是否正确(参见清单 13)。可以修改 TestsRulesEngineTest JUnit 类以多添加几个具有不同属性的 Machine 实例,然后使用断言验证结果是否跟预期一样。
清单 13. testTestsRulesEngine() 方法中用于验证业务逻辑实现是否正确的断言
public void testTestsRulesEngine() throws Exception {
while (machineResultSet.next()) {
Machine machine = machineResultSet.getMachine();
testsRulesEngine.assignTests(machine);
Timestamp creationTs = machine.getCreationTs();
Calendar calendar = Calendar.getInstance();
calendar.setTime(creationTs);
Timestamp testsDueTime = machine.getTestsDueTime();
if (machine.getSerialNumber().equals("1234A")) {
assertEquals(3, machine.getTests().size());
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST1)));
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST2)));
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST5)));
calendar.add(Calendar.DATE, 3);
assertEquals(calendar.getTime(), testsDueTime);
} else if (machine.getSerialNumber().equals("1234B")) {
assertEquals(4, machine.getTests().size());
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST5)));
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST4)));
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST3)));
assertTrue(machine.getTests().contains(testDAO.findByKey(Test.TEST2)));
calendar.add(Calendar.DATE, 7);
assertEquals(calendar.getTime(), testsDueTime);
...
|
值得一提的是,除了将对象插入至工作内存之外,还可以在工作内存中修改对象或从中撤回对象。可以在规则的结果块中进行这些操作。如果在结果语句中修改作为当前知识一部分的对象,并且所修改的属性被用在 condition 元素中以确定是否应启动规则,则应在结果块中调用 update() 方法。调用 update() 方法时,您让 Drools 规则引擎知道对象已更新且引用该对象的任何规则的任何条件元素(例如,检查一个或多个对象属性的值)应再次求值,以确定条件的结果现在是 true 还是 false。这意味着甚至当前活动规则(在其结果块中修改对象的规则)的条件都可以再次求值,这可能导致规则再次启动,并可能导致无限循环。如果不希望这种情况发生,则应该包括 rule 的可选 no-loop 属性并将其赋值为 true。
清单 14 用两个规则的定义的伪代码演示了这种情况。Rule 1 修改 objectA 的 property1。然后它调用 update() 方法,以允许规则执行引擎知道该更新,从而触发对引用 objectA 的规则的条件元素的重新求值。因此,启动 Rule 1 的条件应再次求值。因为该条件应再次等于 true(property2 的值仍相同,因为它在结果块中未更改),Rule 1 应再次启动,从而导致无限循环的执行。为了避免这种情况,添加 no-loop 属性并将其赋值为 true,从而避免当前活动规则再次执行。
清单 14. 修改工作内存中的对象并使用规则元素的 no-loop 属性
... rule "Rule 1" salience 100 no-loop true when objectA : ClassA (property2().equals(...)) then Object value = ... objectA.setProperty1(value); update( objectA ); end rule "Rule 2" salience 100 when objectB : ClassB() objectA : ClassA ( property1().equals(objectB) ) ... then ... end ... |
如果对象不再是知识的一部分,则应将该对象从工作内存中撤回(参见清单 15)。通过在结果块中调用 retract() 方法实现这一点。当从工作内存中移除对象之后,引用该对象的(属于任何规则的)任何条件元素将不被求值。因为对象不再作为知识的一部分存在,所以规则没有启动的机会。
... rule "Rule 1" salience 100 when objectB : ... objectA : ... then Object value = ... objectA.setProperty1(value); retract(objectB); end rule "Rule 2" salience 90 when objectB : ClassB ( property().equals(...) ) then ... end ... |
清单 15 包含两个规则的定义的伪代码。假设启动两个规则的条件等于 true。则应该首先启动 Rule 1,因为 Rule 1 的显著值比 Rule 2 的高。现在,注意在 Rule 1 的结果块中,objectB 从工作内存中撤回(也就是说,objectB 不再是知识的一部分)。该动作更改了规则引擎的 “执行日程”,因为现在将不启动 Rule 2。原因在于曾经为真值的用于启动 Rule 2 的条件不再为真,因为它引用了一个不再是知识的一部分的对象(objectB)。如果清单 15 中还有其他规则引用了 objectB,且这些规则尚未启动,则它们将不会再启动了。
作为关于如何修改工作内存中当前知识的具体例子,我将重新编写前面讨论的规则源文件。业务规则仍然与 “要解决的问题” 小节中列出的一样。但是,我将使用这些规则的不同实现取得相同的结果。按照这种方法,任何时候工作内存中惟一可用的知识是 Machine 实例。换句话说,规则的条件元素将只针对 Machine 对象的属性执行比较。这与之前的方法有所不同,之前的方法还要对 Test 对象的属性进行比较(参见 清单 12)。 这些规则的新实现被捕获在示例应用程序的 testRules2.drl 文件中。清单 16 展示了 testRules2.drl 中与分配测试相关的规则:
清单 16. testRules2.drl 中与分配测试相关的规则
rule "Tests for type1 machine" lock-on-active true salience 100 when machine : Machine( type == "Type1" ) then Test test1 = testDAO.findByKey(Test.TEST1); Test test2 = testDAO.findByKey(Test.TEST2); Test test5 = testDAO.findByKey(Test.TEST5); machine.getTests().add(test1); machine.getTests().add(test2); machine.getTests().add(test5); update( machine ); end rule "Tests for type2, DNS server machine" lock-on-active true salience 100 when machine : Machine( type == "Type2", functions contains "DNS Server") then Test test5 = testDAO.findByKey(Test.TEST5); Test test4 = testDAO.findByKey(Test.TEST4); machine.getTests().add(test5); machine.getTests().add(test4); update( machine ); end rule "Tests for type2, DDNS server machine" lock-on-active true salience 100 when machine : Machine( type == "Type2", functions contains "DDNS Server") then Test test2 = testDAO.findByKey(Test.TEST2); Test test3 = testDAO.findByKey(Test.TEST3); machine.getTests().add(test2); machine.getTests().add(test3); update( machine ); end rule "Tests for type2, Gateway machine" lock-on-active true salience 100 when machine : Machine( type == "Type2", functions contains "Gateway") then Test test3 = testDAO.findByKey(Test.TEST3); Test test4 = testDAO.findByKey(Test.TEST4); machine.getTests().add(test3); machine.getTests().add(test4); update( machine ); end rule "Tests for type2, Router machine" lock-on-active true salience 100 when machine : Machine( type == "Type2", functions contains "Router") then Test test3 = testDAO.findByKey(Test.TEST3); Test test1 = testDAO.findByKey(Test.TEST1); machine.getTests().add(test3); machine.getTests().add(test1); update( machine ); end ... |
如果将清单 16 中第一个规则的定义与 清单 10 中的定义相比较,可以看到,新方法没有将分配给 Machine 对象的 Test 实例插入到工作内存中,而是由规则的结果块调用 update() 方法,让规则引擎知道 Machine 对象已被修改。(Test 实例被添加/指定给它。) 如果看看清单 16 中其他的规则,应该可以看到,每当将测试分配给一个 Machine 对象时,都采用这种方法:一个或多个 Test 实例被分配给一个 Machine 实例,然后,修改工作知识,并通知规则引擎。
还应注意清单 16 中使用的 active-lock 属性。该属性的值被设为 true;如果不是这样,在执行这些规则时将陷入无限循环。将它设为 true 可以确保当一个规则更新工作内存中的知识时,最终不会导致对规则重新求值并重新执行规则,也就不会导致无限循环。可以将 active-lock 属性 看作 no-loop 属性的加强版。 no-loop 属性确保当修改知识的规则更新后不会再被调用,而 active-lock 属性则确保在修改知识以后,文件中的任何规则(其 active-lock 属性被设为 true)不会重新执行。
清单 17 展示了其他规则有何更改:
清单 17. testRules2.drl 中与分配测试到期日期有关的规则
rule "Due date for Test 5" salience 50 when machine : Machine(tests contains (testDAO.findByKey(Test.TEST5))) then setTestsDueTime(machine, 14); end rule "Due date for Test 4" salience 40 when machine : Machine(tests contains (testDAO.findByKey(Test.TEST4))) then setTestsDueTime(machine, 12); end rule "Due date for Test 3" salience 30 when machine : Machine(tests contains (testDAO.findByKey(Test.TEST3))) then setTestsDueTime(machine, 10); end rule "Due date for Test 2" salience 20 when machine : Machine(tests contains (testDAO.findByKey(Test.TEST2))) then setTestsDueTime(machine, 7); end rule "Due date for Test 1" salience 10 when machine : Machine(tests contains (testDAO.findByKey(Test.TEST1))) then setTestsDueTime(machine, 3); end |
这些规则的条件元素现在检查一个 Machine 对象的 tests 集合,以确定它是否包含特定的 Test 实例。因此,如前所述,按照这种方法,规则引擎只处理工作内存中的一个对象(一个 Machine 实例),而不是多个对象(Machine 和 Test 实例)。
要测试 testRules2.drl 文件,只需编辑示例应用程序提供的 TestsRulesEngine 类(参见 清单 7):将 "testRules1.drl" 字符串改为"testRules2.drl",然后运行 TestsRulesEngineTest JUnit 测试。所有测试都应该成功,就像将 testRules1.drl 作为规则源一样。
如前所述,用于 Eclipse 的 Drools 插件允许在规则文件中设置断点。要清楚,只有在调试作为 “Drools Application” 的程序时,才会启用这些断点。否则,调试器会忽略它们。
例如,假设您想调试作为 “Drools Application” 的 TestsRulesEngineTest JUnit 测试类。在 Eclipse 中打开常见的 Debug 对话框。在这个对话框中,应该可以看到一个 “Drools Application” 类别。在这个类别下,创建一个新的启动配置。在这个新配置的 Main 选项卡中,应该可以看到一个 Project 字段和一个 Main class 字段。对于 Project 字段,选择 Drools4Demo 项目。对于 Main class 字段,输入 junit.textui.TestRunner(参见图 3)。
图 3. TestsRulesEngineTest 类的 Drools application 启动配置(Main 选项卡)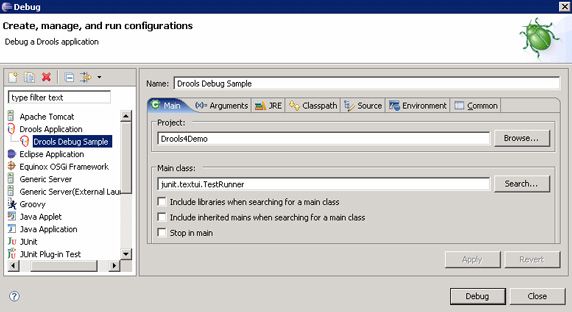
现在选择 Arguments 选项卡并输入 -t demo.test.TestsRulesEngineTest 作为程序参数(参见图 4)。输入该参数后,单击对话框右下角的 Apply 按钮,保存新的启动配置。然后,可以单击 Debug 按钮,开始以 “Drools Application” 的形式调试TestsRulesEngineTest JUnit 类。如果之前在 testRules1.drl 或 testRules2.drl 中添加了断点,那么当使用这个启动配置时,调试器应该会在遇到这些断点时停下来。
图 4. TestsRulesEngineTest 类的 Drools Application 启动配置(Arguments 选项卡)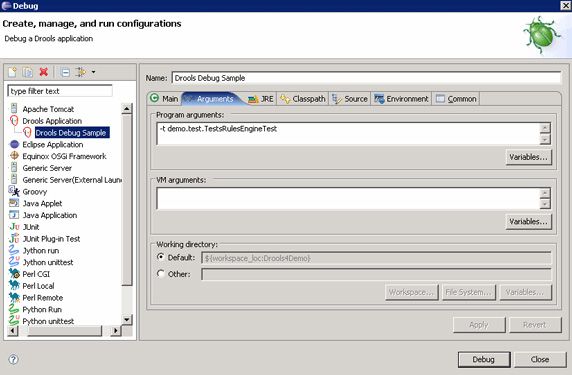
使用规则引擎可以显著降低实现 Java 应用程序中业务规则逻辑的组件的复杂性。使用规则引擎以声明方法表达规则的应用程序比其他应用程序更容易维护和扩展。正如您所看到的,Drools 是一种功能强大的灵活的规则引擎实现。使用 Drools 的特性和能力,您应该能够以声明方式实现应用程序的复杂业务逻辑。Drools 使得学习和使用声明式编程对于 Java 开发人员来说相当容易。
本文展示的 Drools 类是特定于 Drools 的。如果要在示例程序中使用另一种规则引擎实现,代码需要作少许更改。因为 Drools 是 JSR 94 兼容的,所以可以使用 Java Rule Engine API(如 JSR 94 中所指定)设计特定于 Drools 的类的接口。(Java Rule Engine API 用于 JDBC 在数据库中的规则引擎。)如果使用该 API,则可以无需更改 Java 代码而将规则引擎实现更改为另一个不同的实现,只要这个不同的实现也是 JSR 94 兼容的。JSR 94 不解析包含业务规则的规则文件(在本文示例应用程序中为 testRules1.drl)的结构。文件的结构将仍取决于您选择的规则引擎实现。作为练习,可以修改示例程序以使它使用 Java Rule Engine API,而不是使用 Java 代码引用特定于 Drools 的类。