MySQL已然是目前业界最为流行的开源数据库,基于其强大的复制与集群架构构建的高可用数据中心正在被越来越多的公司所采纳。无独有偶,我们公司也正在为客户构建一个低成本、高可用的数据集成平台。因此,对最近学习的MySQL高可用复制架构进行一些总结与分享。
从高可用MySQL的阵营大概可以分为两类,一类是轻量级的异步复制架构,另外一类是较为复杂的同步集群架构。当然,在MySQL5.5以后,还有了半同步复制架构。
基本主从冗余保护
在高可用的世界,一般都有冗余、监控和修复三个最为基本元素。冗余分摊了故障发生的概率,监控使得故障发生后能够及时发现,而修复使得系统得以重新恢复运行。

在整体的系统架构中,如果一个组件是单点应用,那么这个组件发生故障的概率将是100%。所以在MySQL异步复制架构最基本的便是主Master-从Slave冗余保护架构。这样的架构使用与读取请求很多,而写入请求较少,通过主从拓扑实现读写分离。Master维护了数据的源端,而Slave通过binlog技术从Master复制数据。其示意图如下:
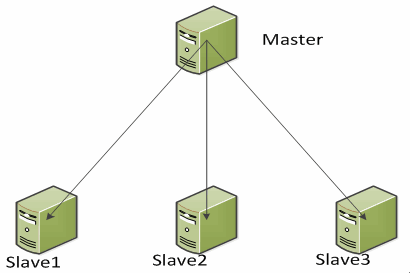
在这种架构中,既实现了读写分离,又实现了Slave冗余保护,但其缺点也是闲而易见的。那就是Master的单点瓶颈。
双机热备主从架构
最简单的服务器备份技术应该就是热备份技术了,其示意图如下:

在MySQL的双机热备复制架构中, Master作为联机实时服务器,维护数据的变化,Slave提供数据读取的服务,而Standby作为Master的一个在线热备份服务器,监听着Master的一举一动,一旦发现Master不再提供服务了,那么马上接管,充当Master的角色。等Master完成修复后,再重新成为Standby。因此,Standby类似与Slave一样,拥有着一个Master的拷贝,只不过区分与Slave的是Standby需要在my.cnf/my.ini中开启log-Slave-updates选项,从而将备份服务器的所有更改写入的备份服务器的二进制日志文件中。
双机热备在理想的情况下,Master宕机时,Standby要完成立即接管,Slave实现切换Master有两个前提:1、所有Slave的复制进度与Standby保持一致 2、Standby接管开始的起点正式Master停止的终点
然而现实总是残酷的,上述两点基本上都无法同时准确无误的满足。在Master正常运行时,Standby的行为完全可以理解为一个Slave,所以基于异步的复制架构,Standby和Slave的复制进度肯定有先后,并且无法保证总是与Master同步。因此,难免会增加一些手动操作。
首先,解决Standby和Slave的复制进度一致性问题。
分别在Standby和Slave上运行SHOW SLAVE STATUS\G命令,如下例:
Standby>SHOW SLAVE STATUS\G
……
Relay_Master_Log_File:Master-bin.000096
……
Exec_Master_Log_Pos:756789
1 row in set (0.00 sec)
Slave>SHOW SLAVE STATUS\G
……
Relay_Master_Log_File:Master-bin.000096
……
Exec_Master_Log_Pos:701234
1 row in set (0.00 sec)
在本例中可以看到,Standby和Slave都基于一个Master的日志文件复制,但是Standby的复制进度要快于Slave进度。因此,在进行主备切换前,先要让Slave的复制进度赶上Standby,并且在正确的位置停住!那么需要在Slave上执行下述操作:
Slave>START SLAVE UNTIL
->MASTER_LOG_FILE=’ Master-bin.000096’,
->MASTER_LOG_POS=756789;
Query OK, 0 rows affected (0.18 sec)
Slave>SELECT MASTER_POS_WAIT(’ Master-bin.000096’, 756789)
Query OK, 0 rows affected (0.18 sec)
那么如果正好与本例相反,即Standby的复制进度要慢于Slave进度。那么就需要颠倒上述的操作,让Standby赶上Slave的复制进度。
其次,精确定位Master失败的位置,即Standby开始的位置
Master在停止运行的时候所记录的文件和位置与Standby是完全不一样的,因此在Slave进行切换前需要获悉Standby开始的位置。那么在Standby执行下述命令:
Standby>SHOW MASTER STATUS\G
*****************1. row********************
File:standby-bin.000019
Positon:654321
Binlog_Do_DB:
Binlog_Ignore_DB:
1 row in set (0.00 sec)
至此,可以放心的将Slave从Master上切换至Standby了,命令如下:
Slave>CHANGE MASTER TO
->MASTER_HOST=’standby1’,
->MASTER_PORT=3306,
->MASTER_USER=’repl_user’,
-MASTER_PASSWORD=’abc@123’,
->MASTER_LOG_FILE=’standby-bin.000019’,
->MASTER_LOG_POS=654321;
Query OK, 0 rows affected (0.18 sec)
Slave>START SLAVE;
Query OK, 0 rows affected (0.18 sec)
双主Active-Passive架构
双Master是非常常用的高可用拓扑结构。两个Master互相复制数据以保持同步,因为是对称的,所以设置起来非常简单。而双主架构又可细分为Active-Passive模式和Active- Active模式。它们都常常搭配共享存储使用,或者低成本的DRBD技术,可以理解为“网络的RAID”实现。Active-Passive模式的拓扑架构示意图如下:
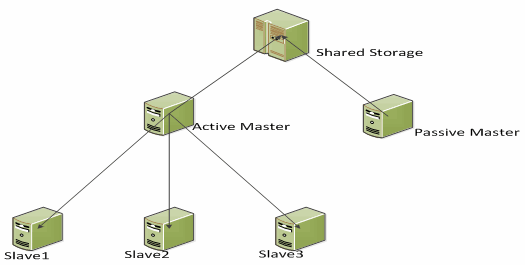
两台Master彼此互为镜像,并且binlog二进制文件存储在共享磁盘之上。这意味着主Master到备Master的切换速度很快,而且Slave也不需要将binlog的文件和位置进行调整,唯一需要做的便这是CHANGE MASTER了。
在Active-Passive模式的双主架构中,最需要注意的便是“脑裂split-brain syndrome”问题了。造成脑裂很有可能是主Master发生故障进入修复期,此时备Master接管服务。不幸的是心跳线或监听服务也发生了故障,那么当主Master完成修复回来时,备Master无法洞悉这一情况,那么将出现两个Master同时运行,那么很有可能出现数据更新的冲突,导致Slave复制出现脏数据。因此,将竭尽全力避免脑裂的发生。值得庆幸的是DRBD内置已经以优雅的方式解决了脑裂split-brain syndrome问题,而共享存储则依赖于该产品自身的处理方式。
双主Active-Active架构
双Master的Active-Active也很常见,该设计常常用于解决地理位置不同,又想保证快速的响应。例如研发部门在深圳,销售部门在北京,那么对于研发立项的数据自然需要Master架设在深圳,而对于市场用户信息的数据自然需要Master架设在北京。深圳的Master提供研发立项的更新写入服务,并维护了市场用户信息拷贝;而北京的Master提供了市场用户信息的更新写入服务,并维护了研发立项数据的拷贝。因此,避免脑裂问题,实现双Master的Active-Active的一个可行方案便是分配不同的数据库(或者不同的表)给不同的Master。其示意图如下:

这里需要注意如前所述开启log-Slave-updates选项,保证服务的更改能够写入二进制文件。
然而总会存在一些数据需要双主同时更新写入,例如员工信息。无论深圳的研发团队,还是北京的市场团队都需要招募员工,那么如何解决相同数据表的冲突问题呢?在MySQL中一个行之有效的方法便是设置奇偶步长,使得一个Master生成主键为奇数的数据,而另外一个Master生成主键为偶数的数据。即在my.cnf/my.ini设置如下:
Master1
auto-increment-increment=2 #步长为2
auto-increment-offset=1 #奇数增长
Master2
auto-increment-increment=2 #步长为2
auto-increment-offset=2 #偶数增长
这种方案非常有效的解决了数据写入同一张表的问题,但是没有解决更新的问题!考虑如下语句:
Master1>UPDATE employee SET rank=’Senior’ Where uid=9527;
Master2>UPDATE employee SET rank=’Junior Where uid=9527;
假如不同的终端分别向Master1和Master2同时发出了如上语句,那么将会导致数据复制的不一致性。因此,必须解决双主同时更新数据的冲突问题。庆幸的是,在MySQL5.1版本引入了混合模式复制。我们知道MySQL默认是基于语句的机制进行复制,但是当碰到下述情况时,就需要基于行的机制进行复制才能保证数据的一致性:
ü 语句调用了:
· UUID函数;
· 用户自定义函数;
· CURRENT_USER或USER函数;
· LOAD_FILE函数;
ü 同一语句更改了两张或更多包含AUTO_INCREMENT列的表
ü 语句中使用了服务器变量
ü 存储引擎不允许使用基于语句的复制,例如:MySQL Cluster引擎
基于行的复制并不复制语句,而是将插入、更新、删除等操作对数据影响的各行进行复制。因此,基于行的复制可以有效解决数据不一致的问题。但基于行的复制并不总是合适,例如大量的独立更新,那么基于语句的复制肯定效率由于基于行的复制。故而MySQL推荐基于混合模式复制,默认情况下使用应用已久的基于语句复制技术,在需要的时候切换为基于行的复制技术。