OutputFormat主要用于描述数据输出的格式,它能够将用户提供的key/value对写入特定格式的文件中。
与InputFormat相似,OutputFormat也是一个接口,旧版API有两个方法:
RecordWriter<K,V> getRecordWriter(FileSystem ignored,JobConf job,String name,Progressable progress) throws IOException;
void checkOutputSpecs(FileSystem ignored,JobConf job) throws IOException;
新版API增加:OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException;
其中,getRecordWriter方法返回一个RecordWriter类的对象,它有如下两个方法:
void write(K key, V value);
void close(TaskAttemptContext context);
前者负责将Reduce输出的Key/Value写成特定的格式,后者负责对输出做最后的确认并关闭输出。
再其中,checkOutputSpecs是在JobClient提交Job之前被调用的,即在InputFomat进行输入数据划分之前,用于检测Job的输出路径,如果存在则抛出异常,防止之前的数据被覆盖,若不存在,然后该方法又会重新创建这个Output路径,这样一来,就能确保Job结束后,Output路径下的东西就是且仅是该Job输出的。。关于InputFomat以及数据划分,可以参考http://924389979.iteye.com/blog/2059267。
hadoop自带很多OutputFormat实现,具体如下: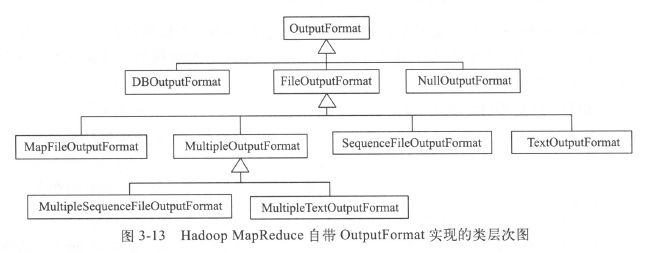
最后,OutputCommitter用于控制Job的输出环境,它有下面几个方法:
void setupJob(JobContext jobContext);
Job开始被执行之前,框架会调用OutputCommitter.setupJob()为Job创建一个临时输出路径 ${mapred.out.dir}/_tempory;
void commitJob(JobContext jobContext);
如果Job成功完成,框架会调用OutputCommitter.commitJob()提交Job的输出,删除临时路径并在${mapred.out.dir}下创建空文件_SUCCESS;
void abortJob(JobContext jobContext, JobStatus.State state);
如果Job失败,框架会调用OutputCommitter.abortJob()撤销Job的输出,删除临时路径;
void setupTask(TaskAttemptContext taskContext);
任务初始化,需要时创建 side-effect file;
boolean needsTaskCommit(TaskAttemptContext taskContext);
判断是否需要提交,若存在 side-effect file,返回true;
void commitTask(TaskAttemptContext taskContext);
提交结果,将 side-effect file 移动到 ${mapred.out.dir} 目录下;
void abortTask(TaskAttemptContext taskContext);
任务运行失败,则删除 side-effect file ;
对应于Job下的每一个Task,同样牵涉创建、提交和撤销三个动作,分别由OutputCommitter.setupTask()、OutputCommitter.commitTask()、OutputCommitter.abortTask()来完成。而一个Task可能没有输出,从而也就不需要提交,这个可以通过OutputCommitter.needsTaskCommit()来判断;
关于 side-effect file 的处理:
side-effect file 并不是任务的最终输出文件,该文件用于执行推测式任务。为防止一个结点上的任务执行速度过慢而拖后腿,hadoop会在另一个结点上启动一个相同的任务,即推测式任务。又为防止这两个任务同时向一个输出文件中写入数据时发生冲突,FileOutputFormat会为每个Task的数据创建一个 side-effect file,并将临时数据写入该文件,待Task完成后,移动到最终输出目录下。
细节部分:
首先,一个Job被提交到JobTracker后会生成若干的Map和Reduce任务,这些任务会被分派到TaskTracker上。对于每一个Task,TaskTracker会使用一个子JVM来执行它们。那么对于Task的setup/commit/abort这些操作,自然应该在执行Task的子JVM里面去完成。
重点说一下任务执行失败时的情况,首先OutputCommitter.abortTask()会被调用。这个调用很特殊,它不大可能在执行任务的子JVM里面完成。因为执行任务的子JVM里面跑的是用户提供的Map/Reduce代码,Hadoop框架是无法保证这些代码的稳定性的,所以任务的失败往往伴随着子JVM的异常退出(这也就是为什么要用子JVM来执行Map和Reduce任务的原因,否则异常退出的可能就是整个框架了)。于是,对于失败的任务,JobTracker除了要考虑它的重试之外,还要为其生成一个cleanup任务。这个cleanup任务像普通的Map和Reduce任务一样,会被分派到TaskTracker上去执行(不一定分派到之前执行该任务失败的那个TaskTracker上,因为输出是在HDFS上,是全局的)。而它的执行逻辑主要就是调用OutputCommitter.abortTask();