RabbitMQ:镜像队列Mirrored queue
在上一节
《RabbitMQ集群类型一:在单节点上构建built-in内置集群》中我们已经学习过:在集群环境中,队列只有元数据会在集群的所有节点同步,但队列中的数据只会存在于一个节点,数据没有冗余且容易丢,甚至在durable的情况下,如果所在的服务器节点宕机,就要等待节点恢复才能继续提供消息服务。
那么是不是有消息冗余的解决方案呢?这就要提到从RabbitMQ 2.6.0版本开始提供支持 镜像队列(Mirrored Queue),消息会在rabbitmq节点之间的被创建为“镜像队列”的队列之间复制。和其它的主从设计一样,镜像队列也有master和slave的概念,一旦某个节点当掉,会在其余的节点中选举一个slave作为master。
在镜像队列(Mirrored Queue)中,只有master的copy对外提供服务,而其他slave copy只提供备份服务,在master copy所在节点不可用时,选出一个slave copy作为新的master继续对外提供服务。
之前我们也将过,rabbitmq会同过一种“选举”机制在余下的所有的salve中选出一个
理想总是简单,真实却总是复杂。如果我们要在运行时添加一个新的节点到集群中,消息复制会怎么处理?如果有新节点加入,RabbitMQ不会同步之前的历史数据,新结点只会复制该结点加入到集群之后新增消息.这里的假设是随着消息的被consumer取走,最终所有的节点的数据都会对齐一致。
接下来,一个自然的追问就“诞生”了:既然master节点退出集群会选一个slave作为master,那么如果不幸选中了一个刚刚加入集群的节点怎么办?那消息不就丢了吗!?这里您可以把心放到您的肚子里,RabbitMQ集群内部会维护节点的状态是否已经同步,使用rabbitmqctl的synchronised_slave_pids参数,就可以查看状态.如果slave_pids和synchronised_slave_pids里面的节点是一致的,那说明全都同步了.如果不一致很容易比较出来哪些还没有同步, 集群只会在“最老”的slave节点之间选一个出来作为新的master节点。
镜像队列分为两种:集群内全节点复制的镜像队列和集群内局部节点复制的镜像队列。先面我们就看一下如何创建镜像队列Mirrored Queue:其实很简单,只要在创建消息队列时,添加一个叫“x-ha-policy”的key/value对就可以了:
//创建集群内全节点复制的镜像队列
...
queue_args = {'x-ha-policy' : 'all'}
channel.queue_declare(queue = 'hello-queue',arguments = queue_args)
...
//创建集群内局部节点复制的镜像队列
...
queue_args = {'x-ha-policy' : 'nodes',
'x-ha-policy-params' : [rabbit@JackyChen,rabbit3@JackyChen]}
channel.queue_declare(queue = 'hello-queue',arguments = queue_args)
...
下面我们通过实际的python代码并执行相关的操作来验证一下镜像队列:
# mkdir -p /data/rabbitmq-pika/c5
# cd /data/rabbitmq-pika/c5
# touch hello_world_mirrored_producer.py
# chmod +x hello_world_mirrored_producer.py
# touch hello_world_mirrored_consumer.py
# chmod +x hello_world_mirrored_consumer.py
其中hello_world_mirrored_producer.py代码如下:
#!/usr/bin/env python
#coding=utf-8
import pika,sys
from pika import spec
#在"/"虚拟主机vhost上通过用户guest建立channel通道
user_name = 'guest'
user_passwd = 'guest'
target_host = 'JackyChen'
vhost = '/'
cred = pika.PlainCredentials(user_name,user_passwd)
conn_params = pika.ConnectionParameters(target_host,
virtual_host = vhost,
credentials = cred)
conn_broker = pika.BlockingConnection(conn_params)
channel = conn_broker.channel()
#创建一个direct类型的、持久化的、没有consumer时队列是否自动删除的exchage交换机
channel.exchange_declare(exchange = 'hello-exch',
type = 'direct',
passive = False,
durable = True,
auto_delete = False)
#使用接收到的信息创建消息
msg = sys.argv[1]
msg_props = pika.BasicProperties()
msg_props.content_type = 'text/plain'
#持久化消息
msg_props.delivery_mode = 2
msg_ids = []
print 'ready to publish...'
#发布消息
channel.basic_publish(body = msg,
exchange = 'hello-exch',
properties = msg_props,
routing_key = 'hala')
print 'published!'
msg_ids.append(len(msg_ids) + 1)
print len(msg_ids)
channel.close()
conn_broker.close()
hello_world_mirrored_consumer.py代码如下:
#!/usr/bin/env python
#coding=utf-8
import pika
#在"/"虚拟主机vhost上通过用户guest建立channel通道
user_name = 'guest'
user_passwd = 'guest'
target_host = 'JackyChen'
vhost = '/'
cred = pika.PlainCredentials(user_name,user_passwd)
conn_params = pika.ConnectionParameters(target_host,
virtual_host = vhost,
credentials = cred)
conn_broker = pika.BlockingConnection(conn_params)
conn_channel = conn_broker.channel()
#创建一个direct类型的、持久化的、没有consumer时,队列是否自动删除exchage交换机
conn_channel.exchange_declare(exchange = 'hello-exch',
type = 'direct',
passive = False,
durable = True,
auto_delete = False)
#创建一个持久化的、没有consumer时队列是否自动删除的名为“hello-queue”
#创建集群内全节点复制的镜像队列
queue_args = {'x-ha-policy' : 'all'}
#创建集群内局部节点复制的镜像队列
#queue_args = {'x-ha-policy' : 'nodes','x-ha-policy-params' : ['rabbit@JackyChen','rabbit3@JackyChen']}
conn_channel.queue_declare(queue = 'hello-queue',
durable = True,
auto_delete = False,
arguments = queue_args)
#将“hello-queue”队列通过routing_key绑定到“hello-exch”交换机
conn_channel.queue_bind(queue = 'hello-queue',
exchange = 'hello-exch',
routing_key = 'hala')
#定义一个消息确认函数,消费者成功处理完消息后会给队列发送一个确认信息,然后该消息会被删除
def ack_info_handler(channel,method,header,body):
"""ack_info_handler """
print 'ack_info_handler() called!'
if body == 'quit':
channel.basic_cancel(consumer_tag = 'hello-hala')
channel.stop_sonsuming()
else:
print body
channel.basic_ack(delivery_tag = method.delivery_tag)
conn_channel.basic_consume(ack_info_handler,
queue = 'hello-queue',
no_ack = False,
consumer_tag = 'hello-hala')
print 'ready to consume msg...'
conn_channel.start_consuming()
打开rabbitmq集群中所有节点:
# /opt/mq/rabbitmq/sbin/rabbitmqctl start_app
# /opt/mq/rabbitmq2/sbin/rabbitmqctl start_app
# /opt/mq/rabbitmq3/sbin/rabbitmqctl start_app
然后执行:
# ./hello_world_mirrored_consumer.py
# ./hello_world_mirrored_producer.py
注意:上面是rabbitmq 3.0之前的创建镜像队列的方法,3.0之后改为通过
//给所有以“hello”开头为名创建的消息队列设置为集群内全节点复制的镜像队列
# ./rabbitmqctl set_policy ha-all2 "^hello.*" '{"ha-mode":"all"}'

创建集群内局部节点复制的镜像队列:
# ./rabbitmqctl set_policy ha-all "^halo.*" '{"ha-mode":"nodes","ha-params":["rabbit@JackyChen","rabbit3@JackyChen"]}'
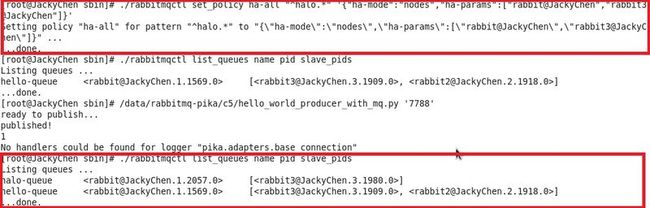
另外还有一种的镜像队列:
//只指定在整个集群节点中只包含count = n 个镜像的镜像列表
# ./rabbitmqctl set_policy ha-all3 "^alert.*" '{"ha-mode":"exactly","count":2}'
那么是不是有消息冗余的解决方案呢?这就要提到从RabbitMQ 2.6.0版本开始提供支持 镜像队列(Mirrored Queue),消息会在rabbitmq节点之间的被创建为“镜像队列”的队列之间复制。和其它的主从设计一样,镜像队列也有master和slave的概念,一旦某个节点当掉,会在其余的节点中选举一个slave作为master。
在镜像队列(Mirrored Queue)中,只有master的copy对外提供服务,而其他slave copy只提供备份服务,在master copy所在节点不可用时,选出一个slave copy作为新的master继续对外提供服务。
之前我们也将过,rabbitmq会同过一种“选举”机制在余下的所有的salve中选出一个
理想总是简单,真实却总是复杂。如果我们要在运行时添加一个新的节点到集群中,消息复制会怎么处理?如果有新节点加入,RabbitMQ不会同步之前的历史数据,新结点只会复制该结点加入到集群之后新增消息.这里的假设是随着消息的被consumer取走,最终所有的节点的数据都会对齐一致。
接下来,一个自然的追问就“诞生”了:既然master节点退出集群会选一个slave作为master,那么如果不幸选中了一个刚刚加入集群的节点怎么办?那消息不就丢了吗!?这里您可以把心放到您的肚子里,RabbitMQ集群内部会维护节点的状态是否已经同步,使用rabbitmqctl的synchronised_slave_pids参数,就可以查看状态.如果slave_pids和synchronised_slave_pids里面的节点是一致的,那说明全都同步了.如果不一致很容易比较出来哪些还没有同步, 集群只会在“最老”的slave节点之间选一个出来作为新的master节点。
镜像队列分为两种:集群内全节点复制的镜像队列和集群内局部节点复制的镜像队列。先面我们就看一下如何创建镜像队列Mirrored Queue:其实很简单,只要在创建消息队列时,添加一个叫“x-ha-policy”的key/value对就可以了:
引用
//创建集群内全节点复制的镜像队列
...
queue_args = {'x-ha-policy' : 'all'}
channel.queue_declare(queue = 'hello-queue',arguments = queue_args)
...
//创建集群内局部节点复制的镜像队列
...
queue_args = {'x-ha-policy' : 'nodes',
'x-ha-policy-params' : [rabbit@JackyChen,rabbit3@JackyChen]}
channel.queue_declare(queue = 'hello-queue',arguments = queue_args)
...
下面我们通过实际的python代码并执行相关的操作来验证一下镜像队列:
引用
# mkdir -p /data/rabbitmq-pika/c5
# cd /data/rabbitmq-pika/c5
# touch hello_world_mirrored_producer.py
# chmod +x hello_world_mirrored_producer.py
# touch hello_world_mirrored_consumer.py
# chmod +x hello_world_mirrored_consumer.py
其中hello_world_mirrored_producer.py代码如下:
引用
#!/usr/bin/env python
#coding=utf-8
import pika,sys
from pika import spec
#在"/"虚拟主机vhost上通过用户guest建立channel通道
user_name = 'guest'
user_passwd = 'guest'
target_host = 'JackyChen'
vhost = '/'
cred = pika.PlainCredentials(user_name,user_passwd)
conn_params = pika.ConnectionParameters(target_host,
virtual_host = vhost,
credentials = cred)
conn_broker = pika.BlockingConnection(conn_params)
channel = conn_broker.channel()
#创建一个direct类型的、持久化的、没有consumer时队列是否自动删除的exchage交换机
channel.exchange_declare(exchange = 'hello-exch',
type = 'direct',
passive = False,
durable = True,
auto_delete = False)
#使用接收到的信息创建消息
msg = sys.argv[1]
msg_props = pika.BasicProperties()
msg_props.content_type = 'text/plain'
#持久化消息
msg_props.delivery_mode = 2
msg_ids = []
print 'ready to publish...'
#发布消息
channel.basic_publish(body = msg,
exchange = 'hello-exch',
properties = msg_props,
routing_key = 'hala')
print 'published!'
msg_ids.append(len(msg_ids) + 1)
print len(msg_ids)
channel.close()
conn_broker.close()
hello_world_mirrored_consumer.py代码如下:
引用
#!/usr/bin/env python
#coding=utf-8
import pika
#在"/"虚拟主机vhost上通过用户guest建立channel通道
user_name = 'guest'
user_passwd = 'guest'
target_host = 'JackyChen'
vhost = '/'
cred = pika.PlainCredentials(user_name,user_passwd)
conn_params = pika.ConnectionParameters(target_host,
virtual_host = vhost,
credentials = cred)
conn_broker = pika.BlockingConnection(conn_params)
conn_channel = conn_broker.channel()
#创建一个direct类型的、持久化的、没有consumer时,队列是否自动删除exchage交换机
conn_channel.exchange_declare(exchange = 'hello-exch',
type = 'direct',
passive = False,
durable = True,
auto_delete = False)
#创建一个持久化的、没有consumer时队列是否自动删除的名为“hello-queue”
#创建集群内全节点复制的镜像队列
queue_args = {'x-ha-policy' : 'all'}
#创建集群内局部节点复制的镜像队列
#queue_args = {'x-ha-policy' : 'nodes','x-ha-policy-params' : ['rabbit@JackyChen','rabbit3@JackyChen']}
conn_channel.queue_declare(queue = 'hello-queue',
durable = True,
auto_delete = False,
arguments = queue_args)
#将“hello-queue”队列通过routing_key绑定到“hello-exch”交换机
conn_channel.queue_bind(queue = 'hello-queue',
exchange = 'hello-exch',
routing_key = 'hala')
#定义一个消息确认函数,消费者成功处理完消息后会给队列发送一个确认信息,然后该消息会被删除
def ack_info_handler(channel,method,header,body):
"""ack_info_handler """
print 'ack_info_handler() called!'
if body == 'quit':
channel.basic_cancel(consumer_tag = 'hello-hala')
channel.stop_sonsuming()
else:
print body
channel.basic_ack(delivery_tag = method.delivery_tag)
conn_channel.basic_consume(ack_info_handler,
queue = 'hello-queue',
no_ack = False,
consumer_tag = 'hello-hala')
print 'ready to consume msg...'
conn_channel.start_consuming()
打开rabbitmq集群中所有节点:
引用
# /opt/mq/rabbitmq/sbin/rabbitmqctl start_app
# /opt/mq/rabbitmq2/sbin/rabbitmqctl start_app
# /opt/mq/rabbitmq3/sbin/rabbitmqctl start_app
然后执行:
引用
# ./hello_world_mirrored_consumer.py
# ./hello_world_mirrored_producer.py
注意:上面是rabbitmq 3.0之前的创建镜像队列的方法,3.0之后改为通过
引用
//给所有以“hello”开头为名创建的消息队列设置为集群内全节点复制的镜像队列
# ./rabbitmqctl set_policy ha-all2 "^hello.*" '{"ha-mode":"all"}'
创建集群内局部节点复制的镜像队列:
引用
# ./rabbitmqctl set_policy ha-all "^halo.*" '{"ha-mode":"nodes","ha-params":["rabbit@JackyChen","rabbit3@JackyChen"]}'
另外还有一种的镜像队列:
引用
//只指定在整个集群节点中只包含count = n 个镜像的镜像列表
# ./rabbitmqctl set_policy ha-all3 "^alert.*" '{"ha-mode":"exactly","count":2}'