在java中,IO模块占着相当重要的位置,IO效率更是关系着软件的效率高低。下面我就对IO的分析进行的一些记录:
相关的基本概念:
流:是数据的有序序列。按照基本的输入输出流的读写数据的不同类型可以分为字节流与字符流。字节流用于读写子节类型的数据(包括ASCMII表中字符),是使用InputStream、OutputStream及他们的子类。字符流用于读写Unicode字符。包括Reader、Writer及他们的子类。
我们在进行读写操作时候,一定的记得读写操作使用的字符集是一致的。若是不一致的话,即使是代码没有问题也会出现乱码的结果。系统使用的默认字符集是不完全一样的,主要是各个CP的问题。我的系统默认字符集是"GBK ",有的是"UTF-8".下面看代码说话吧。
FileOutputStream fo=new FileOutputStream("text1.txt");
String st="华信欢迎你!Wellcome……";
byte bytes[]=st.getBytes("GBK");
//使用默认字符集编码
fo.write(bytes);
System.out.println("输出结束!---");
fo.close();
输出截图:
FileOutputStream fo=new FileOutputStream("text1.txt");
String st="华信欢迎你!Wellcome……";
byte bytes[]=st.getBytes("UTF-8");
//使用UTF-8字符集编码
fo.write(bytes);
System.out.println("输出结束!---");
fo.close();
结果截图: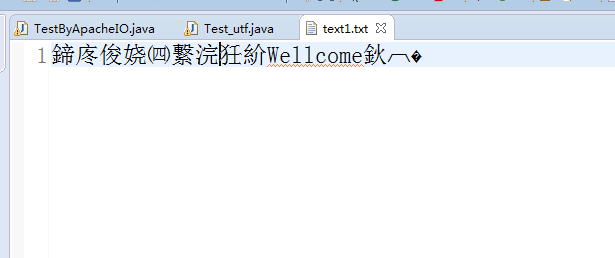
出现乱码是因为读取时候使用默认的"GBK "字符集编码,转为数组写出时候是使用"UTF-8"字符集编码
字节流套上缓冲流之后,字节先读取到缓冲区当中,当要使用到数据时候可以系统会从缓冲区当中提取数据,这样就可以可以提高读写的效率。若是读取大量的数据时候,每次都从数据源提取数据,若每次都是读取一个字节,想想系统要来回数据源多少回?这样的情况会给系统带来不小的负担。还有就是使用字节数组、缓冲流的时候可以自定义他们的容量的大小,合适的大小也可以提供读写的效率,也不会给系统造成浪费这问题,在开发时候要进行去取大量的数据时候,最好先测试出你所需要的字节数组的最佳容量大小和缓冲区的容量的最佳大小。容量的过大或者过小都会降低效率
下面就有无缓冲流,每次都去字节和每次读取数组进行比较效率。(读取MP4文件进行比较,所使用的缓冲区、数组的大小都是测试当时的最佳容量,过大或者过小的容量对效率问题在这就不展示了)
//使用字节流进行复制
FileInputStream fi=new FileInputStream("8.mp4");
FileOutputStream fo=new FileOutputStream("81.mp4");
//使用读取一个整形
int i=fi.read();
while(i!=-1){
fo.write(i);
i=fi.read();
}
//关闭相关流 注意顺序
fo.close();
fi.close();
用时:151960毫秒
FileInputStream fi=
new FileInputStream("8.mp4");
FileOutputStream fo=
new FileOutputStream("81.mp4");
//使用数组
byte []bytes=new byte[256*256];
//测试该文件复制的数组的比较好的数组大小
while(fi.read(bytes)!=-1){
fo.write(bytes);
}
//关闭相关流
fo.close();
fi.close();
用时:109毫秒
//使用字符流进行复制操作
FileInputStream fi=
new FileInputStream("8.mp4");
FileOutputStream fo=
new FileOutputStream("8w_b.mp4");
//创建缓冲区 指定缓冲区的容量大小
BufferedInputStream bi=
new BufferedInputStream(fi,256*512);
//复制该文件比较好的缓冲区的容量大小
BufferedOutputStream bo=
new BufferedOutputStream(fo,256*512);
//使用读取一个整形
int i=bi.read();
while(i!=-1){
bo.write(i);
i=bi.read();
}
//关闭相关流 注意顺序
bo.close();
bi.close();
fo.close();
fi.close();
用时:2369毫秒
FileInputStream fi=
new FileInputStream("8.mp4");
FileOutputStream fo=
new FileOutputStream("8w_b.mp4");
//创建缓冲区
BufferedInputStream bi=
new BufferedInputStream(fi,256*512);
BufferedOutputStream bo=
new BufferedOutputStream(fo,256*512);
//使用数组
byte []bytes=new byte[256];//比较好的大小
while(bi.read(bytes)!=-1){
bo.write(bytes);
}
//关闭相关流 注意顺序
bo.close();
bi.close();
fo.close();
fi.close();
用时:86毫秒
提供的用时仅供参考,没有绝对的。若是更大的文件效果的差异更明显。
BufferedReader ,BufferedWriter的用法和BufferedWriter与PrintWriter的区别:BufferedWriter写出数据时候一定的记得flush一下,不然不能保证数据完全写出来,而PrintWriter(file,true)当第二个参数为true时候,系统会自动flush。在BufferedWriter当中的方法里没有自动换行的方法,在PrintWriter中就有自动换行的方法。
//创建相应的流对象
FileInputStream fi=new FileInputStream("test.txt");
InputStreamReader ir=new InputStreamReader(fi);
BufferedReader br=new BufferedReader(ir,100);
FileOutputStream fo=new FileOutputStream("testw.txt");
OutputStreamWriter or=new OutputStreamWriter(fo);
PrintWriter bw=new PrintWriter(or);
使用PrintWriter写出数据:
String st=br.readLine();
while(st!=null){
pw.println(st);//PrintWriter的写出方法,自动添加换行符
st=br.readLine();
}
结果输出截图: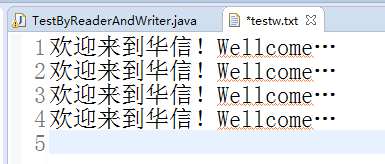
使用BufferedWriter的方法:
String st=br.readLine();
while(st!=null){
bw.write(st);//BufferedWriter的写出方法,没有自动换行
st=br.readLine();
}
输出结果截图:
而两次操作的元数据文本都是一样的
有没有想过,如果读取大量的数据时,把文件分成几段同时读取是不是更快呢?
RandomAccessFile(file,"rw/…")随机访问文件类,参数第一个是操作的文件对象,第二个是的可读、可写、可读可写等操作权限。使用该类进行文件的读些时候可以把文件分成合理的若干段并且指定每段的区域大小。值得注意的是,指定的大小不一过大或者过小。区域制定过小的话,在写出数据时候,数据过大会出现数据丢失。区域指定过大会出现浪费资源。比如说,我把文件分成五段,每段指定区域的大小为100字节,但是我在每一段写出6字节的数据,那么文件的大小回事406字节(前面的4段每段100字节,最后一段6字节。在我的PC机上,前面的每段是一百字节,每段后面会有一大段的空白,但是在苹果的PC上,文字看起来是连着的,但是在第一段文字结束后按右箭头按钮光标是不移动的,要按足94字节才移动)。在使用线程对文件进行读写时候,可以不按照顺序进行读写,但是写出的顺序是不会乱的。还是甩代码说话吧。
package com.lilin.io;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
public class TestBYRandomAccessFile {
/**
* RandomAccessFile类的测试
* @param args
*/
static File file=new File("C:\\Users\\gaosi\\Desktop\\1.txt");
static File file1=new File("testByRAFW.txt");
public static void main(String[] args) {
if(file1.exists()){
file1.delete();
}
for (int i = 0; i < file.length()/10; i++) {
new TestBYRandomAccessFileThread(file,file1,1+i).start();
}
System.out.println("操作完毕");
}
}
package com.lilin.io;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
public class TestBYRandomAccessFileThread extends Thread {
private File file,file1;//文件对象
int blok;//段数
int l=10;//每段区域的大小
/**
* 构造函数,接收对象以及读写的区域段数
* @param file 文件对象
* @param blok 段数
*/
public TestBYRandomAccessFileThread (File file,File file1,int blok){
this.file=file;
this.file1=file1;
this.blok=blok;
}
@Override
public void run() {
try {
//创建随机访问文件流对象
@SuppressWarnings("resource")
RandomAccessFile raf=new RandomAccessFile(file,"rw");
RandomAccessFile raf1=new RandomAccessFile(file1,"rw");
//指定开始读写的帧
raf1.seek((blok-1)*l);
raf.seek((blok-1)*l);
byte []bytes=new byte[10];
// String st=raf.readLine();
raf.read(bytes);
//写出数据
raf1.write(bytes);
// raf1.writeChars(st);
} catch (Exception e) {
e.printStackTrace();
}
}
}
根据比对,数据是一样的。
要是要对问件进行复制,Apache提供的一个IO库,里面的提供的方法就非常简单了。
File file1=new File("8.mp4");
File file2=new File("80.mp4");
FileUtils.copyFile(file1, file2);
几行代码就可以搞定复制文件的操作, 是不是超炫的?但是效率就不是非常高的。该类里面还有很多方法,值得去研究研究。
那么问题来了,怎么使用Apache的IO呢?




导入工程里面lib,在Build path一下就可以了直接使用了,不需要创建实例,FileUtils可以当成静态的变量在使用