Java NIO 之 Buffers
你可以把ByteBuffer看着是一段连续内存(实际却不一定),或Byte的数组。Buffer类则提供了很多方法去访问/设置元素。而基于之上的CharBuffer,IntBuffer等则是是数据类型的抽象。
1. Buffer 类图
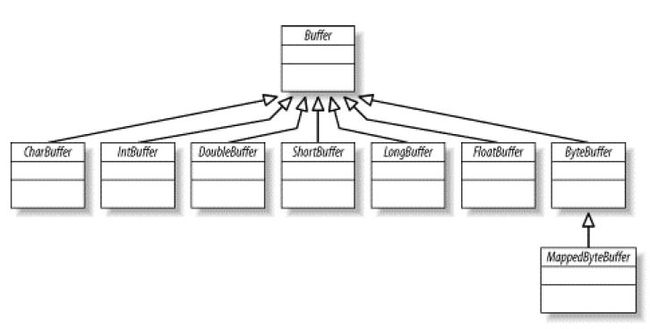
2. 主要属性
Capacity,能容纳的最多元素个数,构造时固定的;
Limit,读写元素的边界,可修改;
Position,当前读写位置,可修改;
Mark,标记位,书签位,不能超过limit,未设置前为undefined状态;
0 <= mark <= position <= limit <= capacity
3. 难理解的API
3.1 flip
将position指向0,limit指向最后一个元素之后的一个位置,为读元素做好准备。
flip前:
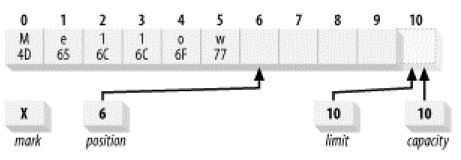
flip后:
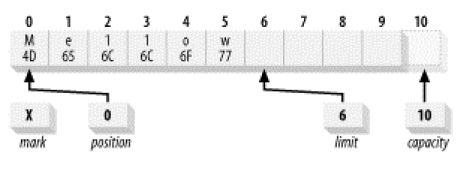
flip两次后,position和limit都变成了0。
3.2 rewind
倒带,设置position为0,相当于position(0);
3.3 compact
将已读完的元素去除,把未读的元素向前移位,将position移到所有未读元素之后,准备写入元素。
compact前:
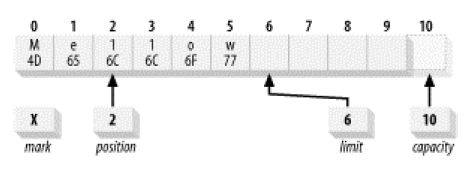
compact后:
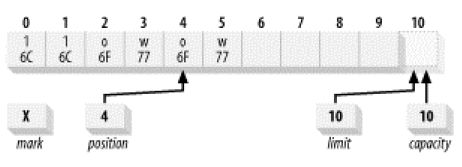
3.4 mark
标记一个位置,reset()将读写指针返回到当前的标记位。
清除标记的方法有:rewind(),clear(),flip(),position(index),limit(index)(如果index < mark).
3.5 clear和reset
clear是清除所有元素,reset是将读写指针返回到当前的标记位。
3.6 equals
下列条件成立则相等:
Buffer同类型;
Buffer剩余元素数目、顺序、值相等,即position和limit之间的元素相等,和capacity,其他元素无关;
3.7 compare
比较也是比较剩余元素,但按照字符串比较的方式进行。
3.8 块移动(Bulk Move)
Buffer可以以块的方式读取或者写入,如:CharBuffer.get(char[] dst); CharBuffer.put(char[] dst),但需注意在读取或写入前,先调用Buffer.remaining()获取剩余的元素个数,或剩余的空间,不然由于目标空间不够会抛出:BufferOverflowException。
3.9 创建Buffer
有两种方式创建Buffer,Buffer.allocate(int capacity);和Buffer.wrap(E[] elements);第一个方法会分配空间,第二种不会,它用elements的空间。
buffer.wrap(E[] elements, int offset, int length);仍然是整个数组,但设置position为offset,limit为length,因为wrap不会分配空间。
这两种方式创建的buffer都不是direct的,都是backing by 数组,hasArray()会返回true;支持数组的操作;
3.10 duplicate
该方法会创建一个新的buffer视图,它的position, limit, mark是独立的,它和原buffer都共享一个backing数组,因此它们任何一个对buffer的更改都会影响另外一个。
asReadyOnlyBuffer则创建一个只读的视图。
slice()则创建部分视图。
3.11 allocateDirect
调用操作系统分配缓冲区,该缓冲区不需要转换就直接可以被底层IO处理,高并发的IO应用重用该缓冲区可以显著提供IO效率,因为它避免了缓冲区的拷贝(JVM内的缓冲区需要拷贝到外部才能被底层IO处理)。
但分配此缓冲区的代价比较大,不能在JVM内部完成,且分配的缓冲区在JVM管理之外,即不是由JVM回收,除非重用率高,不然不推荐使用。
该方法分配的缓冲区,数组的方法是不支持的,会抛UnsupportOperationException。
3.12 asXxxBuffer
ByteBuffer可以创建各种Primitive类型的Buffer视图,如asIntBuffer()。