ORDER BY 可以匹配索引是限制的
具体可以参考下http://dev.mysql.com/doc/refman/5.6/en/order-by-optimization.html
本地做了下测试,发现跟单纯的读文档的理解差别还是挺大的。
知识点一:ORDER BY的字段是否走索引跟表的数据量有关系,表的数据量比较小的时候会走全表扫描,数据量比较大的时候才会走索引,这可能也是MySQL基于代价的结果。
知识点二:WHERE KEY_PART1 > CONST ORDER BY KEY_PART1,KEY_PART2也是可以走索引的,但是官方没有列举这么仔细。
知识点三:MySQL两种排序方式一种是需要回表的,另外一种不需要回表。
一般情况包含大字段的时候会需要回表,否则直接都拿出来了对关键字排序即可。
知识点四:这里filesort并不是说通过磁盘文件进行排序,仅仅告诉我们进行了一个排序操作。
知识点五:如果排序字段同时存在两个表中,或者join完之后排序,则需要在临时表中进行,一般如果order by字段在驱动表上则先对驱动表进行排序再做join也是顺序的。
知识点六:如果无法避免排序,该如何优化。
1.增大max_length_for_sort_data 如果所有字段的最大长度小于这个参数值的时候,MySQL会选择第二种排序算法,否则选择第一种。
2.去掉不必要的字段,如果内存不够但是增大max_length_for_sort_data,则需要排序的数据会分成很多段进行,效率比较低,去掉不必要的字段来适应max_length_for_sort_data。
3.增大sort_buffer_size参数设置:
增大这个参数并不是为了让MySQL可以选择第二种排序算法,而是为了让数据减少排序的分段。
ORDER BY可以走索引的情况:
-- Order by explain SELECT * FROM `mytest`.`table_rm002` ORDER BY `float`,`real`; -- Order by的排序顺序必须一致 explain SELECT * FROM `mytest`.`table_rm002` ORDER BY `float` asc,`real` asc; -- Order by不一定完全匹配索引,但是where中必须是常量 explain SELECT * FROM `mytest`.`table_rm002` where `float` = 100 ORDER BY `real` asc; -- Order by是组合索引,where中必须是常量 explain SELECT * FROM `mytest`.`table_rm002` where `float` = 100 ORDER BY `float` asc,`real` asc; -- Order by是组合索引,where中必须是常量【不能走索引】 explain SELECT * FROM `mytest`.`table_rm002` where `real` = 100 ORDER BY `float` asc,`real` asc; -- 下面三种待验证 SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 < constant ORDER BY key_part1 DESC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2 测试了下官网给出的三个模板SQL有点令人误解: 其实这样的格式也是可以使用索引的 SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1, key_part2;
测试案例:
构建10条数据的表
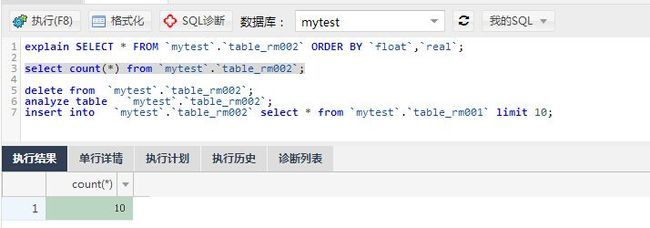
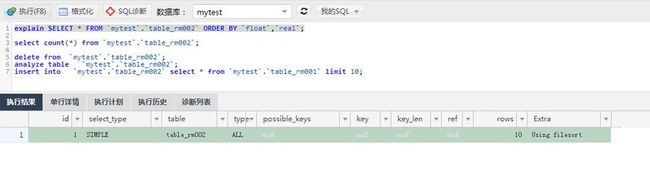
看看10条数据的ORDER BY索引会怎么走,竟然没有走索引,而是使用了using filesort
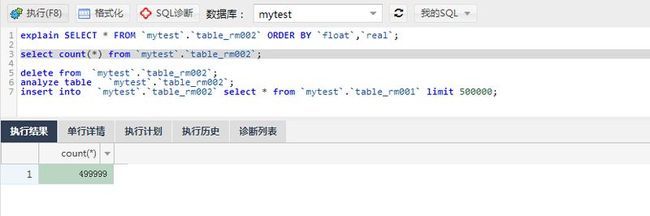
测试50W条数据情况
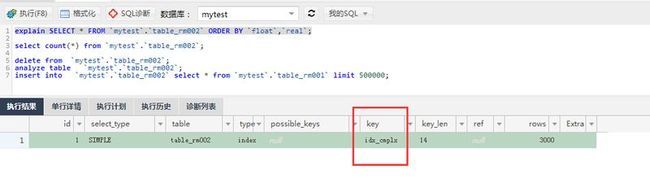
看看50W条数据的ORDER BY索引会怎么走,发现走了索引idx_cmplx,奇怪吧,反正我是有点颠覆了价值观。
看吧,虽然这里的key_part1是< ,order by是key_part1和key_part2但是仍然走了索引
mysql> explain SELECT * FROM `mytest`.`table_rm002` where `float` < 100 order by `float`,`real` \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: table_rm002
type: range
possible_keys: idx_cmplx,idx_float
key: idx_cmplx
key_len: 5
ref: NULL
rows: 59
Extra: Using where
1 row in set (0.01 sec)
附上测试中使用的SQL语句
-- 查看Query的执行计划 explain SELECT * FROM `mytest`.`table_rm002` ORDER BY `float`,`real`; -- 重建表索引 analyze table `mytest`.`table_rm002`; -- 删除数据 delete from `mytest`.`table_rm002`; -- 构造数据 insert into `mytest`.`table_rm002` select * from `mytest`.`table_rm001` limit 500000; -- 表的创建语句 CREATE TABLE `table_rm002` ( `id` int(11) NOT NULL AUTO_INCREMENT, `varchar` varchar(32) DEFAULT NULL, `tinyint` tinyint(4) DEFAULT NULL, `smallint` smallint(6) DEFAULT NULL, `mediumint` mediumint(9) DEFAULT NULL, `bigint` bigint(20) DEFAULT NULL, `integer` int(11) DEFAULT NULL, `float` float DEFAULT NULL, `real` double DEFAULT NULL, `decimal` decimal(10,0) DEFAULT NULL, `boolean` tinyint(1) DEFAULT NULL, `date` date DEFAULT NULL, `datetime` datetime DEFAULT NULL, `time` time DEFAULT NULL, `year` year(4) DEFAULT NULL, `text` text, `blob` blob, PRIMARY KEY (`id`), KEY `idx_float` (`float`), KEY `idx_varchar` (`varchar`), KEY `idx_cmplx` (`float`,`real`) ) ENGINE=MyISAM AUTO_INCREMENT=3000001 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT