GPS trajectory 的提取策略
问题:给定大量的出租车时间轨迹序列,分析出正常的行驶轨迹序列。
时间轨迹序列的提取:出租车轨迹
(1)GPS原始数据是<longitude,latitude,timestamp>→(x,y,t)。但是GPS是有噪声的,而且车辆可能趴活。因此要合理提取行驶轨迹用到如下策略
a) ΔT,定义最大时间间隔,如果2个连续GPS记录pi(xi,yi,ti)和pi+1(xi+1,yi+1,ti+1)的时间间隔大于ΔT,那么在ti时刻分割这个时间序列,即作为不同的行驶轨迹。
b) 给定时间间隔Δt,以及Δdistance。如果当前点与上一点距离Δd>Δdistance,那么该点作为上一个轨迹的终点,下一个轨迹的起点。(在实践中,使用的是,上一个点作为终点,当前点作为下一个轨迹的起点)
在实际大量的出租车轨迹中,由于上传数据,存在出租车ID相同的情况,因此有必要区分。
方法1:发现轨迹异常,即存在ID冲突,几乎同一时刻点的车辆出现在2个或2个以上的坐标位置,把该ID异常数据全部清除。
方法2:不清除数据,而是进行简单分类。发现异常数据,把异常数据,进行分类,即通过聚类找到该异常数据合适的类别。假设存在实际上是2个车辆的轨迹<p1,p1',p2,p3,p2',p3',p4,p5,p6,p4'>,在p1'时发现数据异常,此时只有一个类别cluster1{p1},因此需要新创建一个类别cluster2{p1'}。当分析p2时,因为p2与当前类的前一个序列点p1’有异常,那么判定p2是否属于其他类,最后,将p2分类到p1中。此时cluster1{p1,p2},cluster2{p1'},重复上述过程,可以得到cluster1{p1,p2,p3,p4,p5,p6},cluster2{p1',p2',p3',p4'}
方法1的缺点是:可能只有少部分错误,但却弃掉了大部分有用的数据;方法2,可能不能正确的分类,如果上述例子中p2,既可以属于cluster1,也可以属于cluster2,则无法正确分类。即,如果有相同的车辆ID上传数据,而且两辆车在物理距离上也很相近,那么该方法失效。
实践中,采用的是方法2。
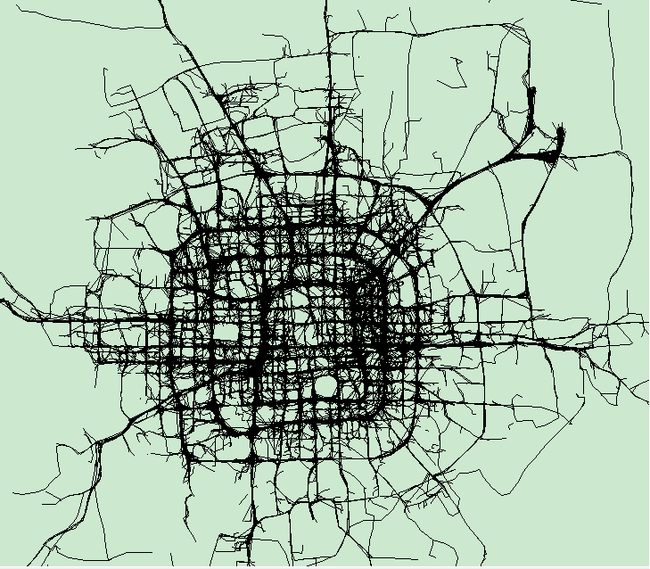
这是某天凌晨到凌晨3点形成的出租车行驶轨迹图: