Terrocotta - 基于JVM的Java应用集群解决方案
Terrocotta - 基于JVM的Java应用集群解决方案
前言
越来越多的企业关键应用都必须采用集群技术,实现负载均衡(Load Balancing)、容错(Fault Tolerance)和灾难恢复(Failover)。以达到系统可用性(High Availability)和可伸缩性(Scalability)的要求。
关于J2EE集群技术的基本原理和常用实现方式,TheServerSide.com有一篇经典的文章:
http://www.theserverside.com/tt/articles/article.tss?l=J2EEClustering
CSDN上,陶建风先生在他的博客中也作了翻译:
http://blog.csdn.net/ESoftWind/archive/2006/10/19/1341089.aspx
这篇文章虽然发表于2005年,但它对集群技术的概念、原理和实现的基本描述至今依然适用。刚刚接触集群技术的朋友不妨阅读一下这篇文章,以便掌握集群技术的基本知识。
我写这篇文章是想介绍一个新的Java集群技术,Terracotta。它采用了与众不同的手段,解决了传统集群技术面临的一些关键问题。可以说为Java集群技术的实现吹来了一股新鲜的空气。
Terracotta(http://terracotta.org/)是一个开源的框架。他的创始人Ari Zilka原本是Walmat.com的首席架构师。他于2003年成立Terracotta公司,并且将产品开源。该产品在2006年左右趋于成熟,在很多财富500强企业获得成功应用。2009年Terracotta在该年度的JavaOne会议中获得Duke奖,并由Java创始人James Gosling先生亲自把该奖颁发给了Ari Zilka先生。
本文着重介绍Terracotta技术的基本原理,尤其是它与其它集群技术的根本区别之处。然后会用一个简单的例子说明Terracotta的基本使用方式。在以后的文章里,我会陆续详细介绍Terrocotta的不同应用场景和技巧。
基本原理
Terracotta最大的特点是它使用Java二进制代码增强的方式(binary code injection)截获集群节点对数据的修改和获取的请求,利用单独的Terracotta服务器调配数据的流向,以达到最高的网络效率。这两点可以说是与传统集群技术采用的序列化和网络广播机制在实现思路上的根本不同。另外从开发人员角度来说,Teraccotta隐藏在Java API之后,开发人员不需要学习新的API。只需要使用标准的JDK数据结构(java.util.*, java.concurent.*等)、内置Java协同、加锁机制(synchronized, object.wait, object.notify等)开发代码,在Terracotta平台之上就可以把单机基于POJO的应用扩展到多机集群上。因此开发人员的学习曲线很短。
Terracotta集群方案由两部分组成:Terracotta驱动器和Terracotta服务器: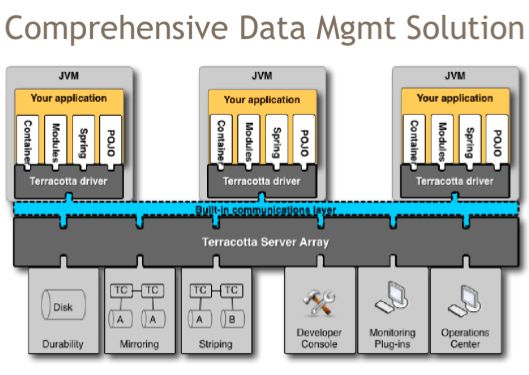
其中驱动器部分(也称为Terracotta客户端)与应用程序执行在相同的JVM中。实际上应用程序是由Terracotta驱动器载入到内存中的。载入的同时,会对Java二进制代码进行增强。用户提供Terracotta配置文件指定本地程序中哪些数据需要在集群中共享。这样Terracotta就可以通过增强的代码截获对这些共享数据的读写请求,并且与Terracotta服务器协作,实现共享数据在集群中的一致性。对于Java代码中使用的“锁”也是利用相同的机制实现全局协同;
Terracotta服务器则首先记录所有节点对共享数据和锁的访问信息,为读取数据的节点提供最新数据,把修改的数据通知给正在使用中这些数据的节点等等。服务器除了协调节点间数据的获取和变化通知以外,还利用其本地内存和硬盘实现共享数据的缓存和持久化。
由于Terracotta驱动器和服务器都有缓存数据的能力,有时我们也称Terracotta驱动器为一级缓存L1,服务器为二级缓存L2。
Terracotta这一体系架构跟其它集群解决方案相比,有如下几点好处:
1、避免Java序列化,只把被修改的字段的数据传递给服务器和使用节点,大大减少CPU和内存消耗;
2、避免数据的广播,只把修改的数据通知给正在使用该数据的节点,大大降低了网络流量;
3、利用服务器实现网络扩展内存,使得有限内存的客户端节点可以访问远大于其内存容量的数据结构,而不必担心发生内存逸出的异常;
4、通过服务器实现共享数据持久化,通过服务器集群实现容错性等等
5、无须学习新的API,大大降低开发成本
企业版的Terracotta服务器还提供了数据分片(striping)的功能,使得集群吞吐量随着Terracotta服务器数量的增加达到线性增长。
Terracotta插件
在核心产品的基础上,Terracotta制定了通用扩展机制Terracotta Integration Module - TIM。Terracotta本身提供了大量的插件,应用于不同的集群应用场景,比如Tomcat session复制、Spring Security整合、与Hibernate的整合、异步数据库持久化等等。所有官方TIM可以在如下网站中找到:
http://forge.terracotta.org/releases/projects.html
用户也可以开发新的TIM,以适应自己的应用需求。
比如TIM-Session实现了Web应用服务器结点间session信息的共享。由于它利用了Terracotta集群间高效数据共享的机制实现session共享,整个集群的吞吐量可以随着服务器节点的增加而线性增长。与之相比,Tomcat自带的session集群实现,最多只能支持到4个节点左右。当节点数目进一步增加的时候,各节点的CPU使用率和网络负载会达到极限,反而降低整个集群的吞吐量。基于Terracotta的Tomcat集群可以达到几十个节点甚至更多。
我会在以后的文章中详细介绍重要的TIM插件和他们的应用场景。
基于Terracotta的Java集群
下面用一个简单的Java程序描述如何利用Teracotta事件Java集群。这个例子大概只比一般的Hello World稍微复杂一点。目的主要是介绍使用Terracotta的最简单流程。我会在以后的文章中详细介绍不同应用场景下Terracotta不用的使用方式和解决问题的方法。
首先看看Java代码。这是一个简单的多线程程序,启动后生成两个线程,给一个共享的计数器加一,然后打印出计数器的值:
- package simpleparallel;
- public class Main implements Runnable{
-
- private Object lock = new Object();
- private int count = 0;
- private static Main inst = new Main();
- /**
- * @param args
- */
- public static void main(String[] args) {
- new Thread(inst).start();
- new Thread(inst).start();
- }
- public void run() {
- //keep increasing count by one every few seconds
- while(true){
- synchronized(lock){
- count++;
- System.out.println(Thread.currentThread().getName() + " increased count to:"+count);
- }
- try{
- Thread.sleep((int)(5000*Math.random()));
- }
- catch(Exception e){
- e.printStackTrace();
- }
- }
-
- }
- }
Details
注意代码中没有任何特殊的JDK以外的API。
单独执行这个程序,会看到如下现实的结果。
现在我们要把这个代码放到集群上。目的是让多个JVM共同访问同一个计数器,并且能够互斥地对它进行累加,而在全集群范围内不会产生数据冲突。
具体的操作步骤如下:
1、下载并安装JDK 1.5或1.6,设置系统的JAVA_HOME环境变量
2、下载、安装Terracotta环境
- 目前最新的Terracotta版本是3.0.1, 不过3.1马上就要发布了,所以我们使用3.1 stable1,可以从下列地址下载:
http://terracotta.org/web/display/orgsite/Download
或者直接从这个地址下载3.1 stable1 。 - 用 java -jar terracotta-3.1.0-stable1-installer.jar 启动安装程序,把Terracotta安装到指定的目标目录。
假设安装目录是 $TC_HOME(Unix/Linux)或%TC_HOME%(Windows)
3、到刚才的Java代码的开发目录下,确认代码已经用javac编译好。假设编译目标文件在bin目录下。
4、创建一个文本文件tc-config.xml, 把下面的配置保存在该文件中:
- <?xml version="1.0" encoding="UTF-8"?>
- <con:tc-config xmlns:con="http://www.terracotta.org/config">
- <servers>
- <server host="%i" name="localhost">
- <dso-port>9510</dso-port>
- <jmx-port>9520</jmx-port>
- <data>terracotta/server-data</data>
- <logs>terracotta/server-logs</logs>
- <statistics>terracotta/cluster-statistics</statistics>
- </server>
- </servers>
- <clients>
- <logs>terracotta/client-logs</logs>
- <statistics>terracotta/client-statistics/%D</statistics>
- </clients>
- <application>
- <dso>
- <instrumented-classes>
- <include>
- <class-expression>simpleparallel.Main</class-expression>
- </include>
- </instrumented-classes>
- <roots>
- <root>
- <field-name>simpleparallel.Main.inst</field-name>
- </root>
- </roots>
- <locks>
- <autolock>
- <method-expression>void simpleparallel.Main.run()</method-expression>
- <lock-level>write</lock-level>
- </autolock>
- </locks>
- </dso>
- </application>
- </con:tc-config>
Details
5、启动Terracotta服务器:
$TC_HOME/bin/start-tc-server.sh
or
%TC_HOME%/bin/start-tc-server.bat
6、打开两个或者更多的Terminal或DOS窗口,分别启动一个测试程序:
$TC_HOME/bin/dso-java.sh -cp . simpleparallel.Main
or
%TC_HOME%/bin/dso-java.bat -cp . simpleparallel.Main
下图是同时执行三个程序的屏幕截图:

可见计数器已经在集群中被3个Java程序实例所共享。每个程序有两个线程访问计数器。这样整个集群中实际上有6个线程在同时累加计数器。
从上面的启动顺序看,整个Java代码没有作任何改动。只是增加了一个tc-config.xml文件,并且用Terracotta的dso-java启动程序启动这个Java程序就可以了。
tc-config.xml文件是使用Terracotta时最重要的配置文件。
这里面最重要的几个配置为:
1、roots:用来制定集群中要共享的数据。
<roots>
<root>
<field-name>simpleparallel.Main.inst</field-name>
</root>
</roots>
我们的例子制定共享Main类的inst对象,它包含的count和lock对象也就随之被整个集群共享了。
2、locks:
用来制定对共享数据操作的时候采用的加锁机制。
<locks>
<autolock>
<method-expression>void simpleparallel.Main.run()</method-expression>
<lock-level>write</lock-level>
</autolock>
</locks>
这个例子中给Main.run()方法定义了自动锁(autolock)。他告诉Teraccotta当这个方法对共享的数据加锁的时候(注意:Main.lock对象是共享的),使得这个锁在整个集群范围内生效。这样一来集群中任何一个线程锁住这个对象的时候,其它任何线程都要等这个锁解除后才能访问被保护的数据(Main.count)。这样计数器的访问也就在整个集群中得到了保护。
总结
Terracotta是唯一一个在JVM层实现Java集群的平台。开发团队可以在对已有的Java程序作最小修改的情况下,把系统移植到集群中。在开发新的Java代码时,也只需要按照正常的Java代码开发方式编写代码即可,无需学习任何新的API。
Terracotta通过配置文件指定集群中要共享的数据和对该数据进行访问的方法的加锁方式。这也保证了代码跟平台的松散耦合。
今天介绍的主要还是Terracotta的基本原理。实际开发的Java应用大部分都是基于Web的应用,并且有很多系统使用了Hibernate, Tomcat, Spring等工具和平台。在以后的文章中我会陆续介绍Terracotta是如何支持这些工具的。