Avoid traps when porting Java Web applications from Windows to AIX
Nowadays you typically develop applications in a development environment, and then deploy them to a production environment. Most of the time, Windows® is a good choice for the development platform, because there are so many powerful integrated development environments (IDEs) to use. UNIX®-like platforms, such as UNIX, Linux®, or AIX®, are good production platforms due to their stability. The Java™ programming language is claimed as a highly platform-independent programming language with its Write once, run anywhere features. In most situations, it saves hours for developers when porting among different platforms. However, there are some traps or gotchas you should be aware of to ensure your applications behave exactly as you want in the target platform.
This article discuss three traps you can fall into during the porting process. It provides information to help you bypass the traps to safely enjoy the power of the Java programming language.
HTTP communication is common in every kind of Web application. Whenever invoking a servlet or JavaServer Pages (JSP), HTTP communication happens. Though HTTP protocol is platform-independent, special consideration is required when communication happens between different platforms.
In this scenario, a client initiates a special request to a gateway, the gateway processes the request, and then it sends back a response to the client. The client uses a proprietary XML-based protocol to communicate with the gateway, and the gateway only processes messages complying with the protocol. The protocol requires a line break between the two XML elements, <Name> and <Greeting>.
As shown in the code in Listing 1, a line break is added to the request body. But, does the server process it smoothly and respond correctly? It depends. This is a common problem when porting Java applications across different platforms.
Listing 1. Client sends out an HTTP request
try {
URL url = new URL("http://localhost:9081/SampleWeb/Simulator");
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setRequestProperty("Content-Type", "application/xml");
OutputStream os = conn.getOutputStream();
PrintWriter writer = new PrintWriter(os);
writer.println("<?xml version=\"1.0\" encoding=\"iso-8859-1\"?>");
writer.println("<Name>");
writer.print("<first name>");
writer.print(“Rachel");
writer.println("</first name>");
writer.println("</Name>");
//A line break is required here
writer.println();
writer.println("<Greeting>");
writer.println("Hello!");
writer.println("</Greeting>");
writer.flush();
conn.getInputStream();
} catch (MalformedURLException mue) {
System.err.println("error, message =" + mue);
} catch (IOException ioe) {
System.err.println("error, message =" + ioe);
} |
The code works well in the development environment on Windows, but when deployed on a production environment on AIX, you get a surprise when no response is returned by the gateway. So what happens with this seemingly correct code?
The gateway, which is out of your control, is a C program running on the Windows platform. It makes a wrong assumption that all received requests are from Windows, and the \r\n line break character should sit between the <Name> and <Greeting> elements. So, it tries to parse the request with a \r\n character between the <Name> and <Greeting> elements. However, on AIX and most UNIX-like platforms, if the line.separator Java system property variable is not set in advance, the default value is \n, and that's why the gateway complains of a bad request format.
Fixing this problem is quite easy, once you know why things went wrong. The fix can be made either in the client or the gateway code.
- If you don't have control of the gateway code, you can just hard-code your client with
“System.setProperty(“line.separator", "\r\n")" ;. - Otherwise, make the gateway code deal with different platforms as it should. For UNIX-like platforms, deal with the
\ncharacter as the line break. For the Mac OS, deal with\r. On the Windows platform, deal with\r\n.
Be aware of the Java application programming interfaces (APIs), such as java.io.Writer, java.io.Reader, and their inherited APIs. They're all character-based APIs, and they get the default line separator value from the system property, if not set otherwise. If no strict character format is required, you should consider using byte-based Java APIs for better performance.
When porting among different platforms, hard coding the platform-dependent content is often one of the causes for your Java applications to lose compatibility. Line separator is just one of the most common constants. The possible contents include file separator, path separator, and so on. When you want to include these constants in your code, useSystem.getProperty("property name") to get the property value instead of hard coding the character.
Another common problem when porting Java applications among different platforms is locating a file. There are different file locating methods in different environments.
In this scenario, suppose you want to locate a DTD file in one of your utility Java projects, which is used by a Web project in an enterprise application project. To locate sample.dtd in the DtdEntityResolver class in WebSphere® Studio Application Developer (Application Developer) V5.1.2, you might write the code in Listing 2, and it gets a path like E:/workspace/UtilProj/bin/com/ibm/util/sample.dtd.
Listing 2. Sample code to locate a file
Class clazz = getClass();
URL url = clazz.getResource("."); //Trying to get the URL of current directory
String currentPath = url.getPath();
String filePath = currentPath + "sample.dtd";
|
After looking at this code, you might say, well, I have a better solution. There is indeed a better solution, but let's just use the code first, which works fine in the WebSphere Test Environment of Application Developer V5.1.2. In this way, you locate the file.
After finishing all the other modules, your team decides to deploy the enterprise application project to the production environment -- WebSphere Application Server (Application Server) V5.1 running on AIX. This time, you're not so lucky.java.lang.NullPointerException is thrown and you failed to locate the file.
Why does this happen? It works fine on Windows, but it fails on AIX. Is this a cross-platform bug with your Java code? You might think so at first. However, this is not the case. Let's look at the resulting file path of the above code again. It's $Workspace/$ProjectName/$bin/$packageName/sample.dtd. There is a bin directory in your project home, which is used to store the compiled binary classes. Is there still a bin directory after you deploy the enterprise archive (EAR) file on the Application Server running on AIX? As you know, after exporting an enterprise project as an EAR, the utility Java project is included in a Java archive (JAR) file. In a JAR file, it's impossible to locate the resource using "." (current directory indicator), sojava.lang.Class.getResource(".") returns a null object.
After figuring this out, you might think that with a standalone Application Server running on the Windows platform, the code above would also probably give the same NullPointerException. When deploying the same EAR on a standalone Application Server rather than in the built-in WebSphere Test Environment, the same error happens. It sounds strange that your code behaves differently in a test environment shipped with Application Developer V5.1.2 than in Application Server 5.1.x, even if they run on the same Windows platform. For a Java project in an enterprise application project, WTE loads the binary classes directly from the bin directory in your workspace, while a standalone application server loads them from the deployed JAR file. If you're interested in the comparison of the two environments, see Rational® Application Developer Information Center (see Resources). More details on the WebSphere Test Environment are in the WebSphere Application Server Test Environment Guide (see Resources).
In Rational Application Developer V6.0, the test environment is designed to be a standalone application server, so differences between Application Server as a test environment and Application Server as a standalone server are gone. The above code has the same behavior on both Rational Application Developer V6.0 and the standalone Application Server 6, either on Windows or AIX. NullPointerException is always thrown, as both environments treat the utility Java project in an enterprise application project as a JAR file.
Now that you know why things went wrong, let's change to the better solution: using getClass().getResource("sample.dtd"). Here, java.lang.Class.getResource(String filename) delegates the task of finding resource to the associated ClassLoader. Whether the file is in a JAR or in a bin directory, it always returns the resolved file path. Figure 1 shows a comparison among different run time environments on Windows and AIX platforms.
In Figure 1 below, notice that java.lang.Class.getResource(String filename) works on every environment, no matter if it's a built-in test environment of Application Developer, a built-in test environment of Rational Application Developer, a standalone application server running on Windows, or a standalone application server running on AIX. The conclusion is thatjava.lang.Class.getResource(String filename) is always preferred to ensure the platform portability.
Figure 1. Results of getResource(fileName) on Windows and AIX 
JAR files are packaged with the ZIP file format, so you can use them for ZIP-like tasks, such as lossless data compression, archiving, decompression, and archive unpacking. After you locate the file URL using getClass().getResource(String filename), let's say it's $INSTALLEDAPP_HOME/SampleEAR.ear/UtilProj.jar!/com/ibm/util/sample.dtd. The next task is to read the contents from the JAR file; see Listing 3.
Listing 3. Wrong way to read content from a JAR file
URL jarUrl = getClass().getResource(“simple.dtd"); String path = fileUrl.getPath(); FileInputStream fis = new FileInputStream(path); |
It's tricky to read the content from a JAR file. Listing 3 shows an intuitive method to get the FileInputStream for file simple.dtd, but it won't work. Java.io.FileNotFoundException is thrown. See Listing 4 and Listing 5 for the right way to do it.
Listing 4. Right way to read content from a JAR file
URL jarUrl = getClass().getResource(“simple.dtd"); URLConnection urlConn = jarUrl.openConnection(); InputStream is = urlConn.getInputStream(); |
Listing 5. Right way to read content from a JAR file
InputStream is = getClass().getResourceAsInputStream("simple.dtd");
|
Why new FileInputStream(String name) doesn't work while URL.openConnection().getInputStream() does work? Because every instance of java.net.URL is associated with a protocol, such as HTTP, JAR, file, and so on. And, every protocol has a specific handler, which is an instance of java.net.URLStreamHandler, to handle the connection details of related protocols.URL.openConnection() calls URLStreamHandler.openConnection() to get the URLConnection object that represents the connection to the remote object referred to by the URL. For the HTTP protocol, one HttpURLConnection object is returned; for the JAR protocol, one JarURLConnection object is returned.
For the code in Listing 4, the urlConn is an instance of JarURLConnection. When invoking getInputStream of JarURLConnection, it calls JarFile.getInputStream(JarEntry jarEntry) and the jarEntry in your case is the file named simple.dtd. Finally, aJarInputStream instance is returned, which is used to read the contents from a JAR file.
Why FileInputStream doesn't work might be obvious -- the JarEntry in a JAR file uses a Jar protocol. FileInputStream only deals with the file protocol, so naturally it cannot work successfully on sample.dtd (a JarEntry in a JAR file that uses JAR protocol).
For the code in Listing 5, the class literal returned by getClass() calls ClassLoader.getResourceAsInputStream(). The latter then calls getResource(fileName).openConnection().getInputStream(). The code in Listing 5 is equal to the code in Listing 4 in function.
All in all, when reading content from a JAR file, use the code in Listing 4 or Listing 5; never use FileInputStream, because it won't deal with JAR protocol.
No read process in socket communication
This section discusses a problem commonly encountered in socket communication on the AIX platform. Performance test is a good thing. It helps you find bugs that aren't as obvious as those found in a functional test. These bugs include memory leaks and race condition of multi-thread programming. They're like gremlins in your code, and they can make it behave weirdly sometimes.
In this performance test scenario, a test client keeps sending Web service requests to a Web application running on Application Server. The Web application processes it and constructs a new message, and then sends the newly built message to a gateway. The gateway then sends back a response to the Web application, and the Web application sends a response to the test client. Figure 2 shows the process flow.
Figure 2. Performance test on a Web application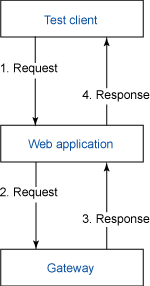
The above scenario is common and quite easy to verify in a functional test. However, in a performance test when the enterprise application is undergoing a high transaction per second (TPS), your application has a good reason to throw an exception if no performance test was conducted before.
The exception happens in socket communication, and the main feature is:
java.net.SocketException: There is no process to read data written to a pipe |
The "There is no process to read data written to a pipe" error is an AIX-specific error message, which lies in the native method implementation of the corresponding Java code. It's thrown by the C code that implements socket communication on AIX.
As the message says, it happens when the message written to a pipe is not read by any process. When plenty of requests are sent to the accepting side, the accepting side might fail to read the request because of timeouts, blocked threads or other reasons, and then this exception is thrown.
Most of the time, this problem is caused by potential bugs. For example:
- The Web application establishes an HTTP connection with the gateway, and it tries to send it a request (Step 2 in Figure 2), as shown in Listing 6.
Listing 6. Send HTTP request to Web Application
URL url = new URL(serverAddress); URLConnection conn = url.openConnection(); conn.setDoOutput(true); OutputStream os = conn.getOutputStream(); PrintWriter writer = new PrintWriter(os); writer.println("Hello, dude"); writer.flush(); writer.close(); InputStream is = conn.getInputStream();Without the last line
InputStream is = conn.getInputStream, thejava.net.SocketException: There is no process to read data written to a pipeexception is thrown. Withoutconn.getInputStream(), the request message won't be posted to the accepting side at all. As a result, the accepting side won't receive any message, so of course there won't be any process to read the request data written to the connection socket, so it causes the exception. - Timeout when listening to a response, as shown in Step 4 in Figure 2.
Performance test might expect that the test client can get a response within five seconds. If the response is returned after five seconds, the test client that sends out the request won't process it anymore. As a result, the test client won't read the response data. For the socket pipe, data is written, but it lacks a reading process.
- The responding thread is blocked by another thread, as shown in Step 3 in Figure 2.
Suppose you manage a thread pool in the gateway to respond to the requests sent by the Web application. When a pretty high TPS is reached but, due to inefficient thread scheduling, it's quite probable that no thread can be scheduled to handle a new request. As a result, the request is not read and processed by any thread. This can also cause the error.
For input or output stream-based APIs, make sure all the opened connections (opened InputStream(Reader) orOutputStream(Writer)) are closed when they're no longer needed.
Though not huge, porting Java Web applications from one platform to another does cost some effort. Three points to remember are:
- When writing OS-dependent code, avoid hard-coding. Using
java.lang.System.getProtery(String name)is always more secure. - Use
java.lang.Class.getResource(String filename)to locate resources works on Application Developer V5.1.2, Rational Application Developer V6.0, and the related version of Application Server, whether on Windows or AIX. - For error-prone network programs, read and write operate in pairs. If you write data into a socket, there must be some process to read them out.
Learn
- "Enable C++ applications for Web services using XML-RPC" (developerWorks, Jun 2006): Read this step-by-step guide to exposing C++ methods as services.
- Rational Application Developer Information Center: Visit this center to learn how to use this integrated development environment.
- WebSphere Application Server Test Environment Guide: Get the latest details on the WebSphere Test Environment.
- Search the AIX and UNIX library by topic:
- System administration
- Application development
- Performance
- Porting
- Security
- Tips
- Tools and utilities
- Java technology
- Linux
- Open source
- AIX and UNIX: The AIX and UNIX developerWorks zone provides a wealth of information relating to all aspects of AIX systems administration and expanding your UNIX skills.
- New to AIX and UNIX: Visit the New to AIX and UNIX page to learn more about AIX and UNIX.
- AIX 5L™ Wiki: A collaborative environment for technical information related to AIX.
- Safari bookstore: Visit this e-reference library to find specific technical resources.
- developerWorks technical events and webcasts: Stay current with developerWorks technical events and webcasts.
- Podcasts: Tune in and catch up with IBM technical experts.
Get products and technologies
- IBM trial software: Build your next development project with software for download directly from developerWorks.
Discuss
- Participate in the developerWorks blogs and get involved in the developerWorks community.
- Participate in the AIX and UNIX forums:
- AIX 5L -- technical forum
- AIX for Developers Forum
- Cluster Systems Management
- IBM Support Assistant
- Performance Tools -- technical
- Virtualization -- technical
- More AIX and UNIX forums