- Java 结合elasticsearch-ik分词器,实现评论的违规词汇脱敏等操作
八百码
elasticsearch大数据搜索引擎
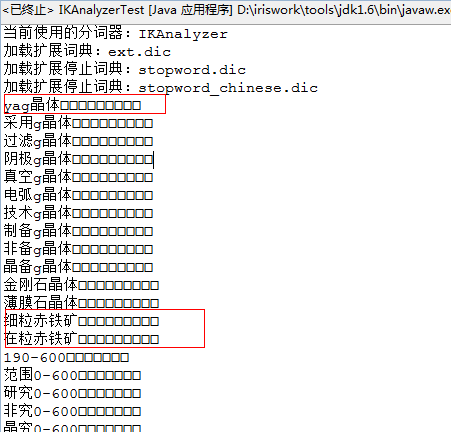
IK分词(IKAnalyzer)是一款基于Java开发的中文分词工具,它结合了词典分词和基于统计的分词方法,旨在为用户提供高效、准确、灵活的中文分词服务。注意:需要自己建立一个敏感词库,然后自己选择方式同步到elasticsearch中,方便比对操作话不多说,直接上后台代码这个依赖是我使用的,可以结合自己的情况自己选择适用版本的相关依赖org.elasticsearchelasticsearcho
- Java——ikanalyzer分词·只用自定义词库
weixin_30902251
java数据库c/c++
需要包:IKAnalyzer2012_FF_hf1.jarlucene-core-5.5.4.jar需要文件:IKAnalyzer.cfg.xmlext.dicstopword.dic整理好的下载地址:http://download.csdn.net/detail/talkwah/9770635importjava.io.IOException;importjava.io.StringReader
- windows安装Elasticsearch后使用ik分词器报错解决办法
qqcoming
elasticsearchjenkins大数据
最近在学习Elasticsearch,安装完成后下载了ik分词器压缩到plugins目录下启动es报错如下:java.security.AccessControlException:accessdenied(“java.io.FilePermission”“D:…\plugins\ik-analyzer\config\IKAnalyzer.cfg.xml”“read”)咋一看以为是es对应的jdk
- solr中文分词
墨夕晨
创建一个存储位置mkdir-p/usr/local/Ikcd/usr/local/Ikhttps://pan.baidu.com/share/init?surl=P49uuVqT9PubcAHP8onOBw提取码:kcs2把ikanalyzer-solr5文件夹内的jar放入/usr/local/solr/solr-7.7.3/server/solr-webapp/webapp/WEB-INF/l
- es-ik分词器的拓展和停用字典
Crhy、Y
大数据JavaSpringCloudelasticsearch大数据搜索引擎springcloudmysql分布式tomcat
目录一、分词器一、分词器分词器的作用是什么?创建倒排索引时对文档分词用户搜索时,对输入的内容分词IK分词器有几种模式?ik_smart:智能切分,粗粒度ik_max_word:最细切分,细粒度IK分词器如何拓展词条?如何停用词条?利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典在词典中添加拓展词条或者停用词条ik分词器-拓展词库要拓展ik分词器的词库,只需要修改
- 修改ES IK插件源码,配合MySQL实现词库热更新
LittleMagic
ESIK词库热更新简介在实际工作中,我们经常需要更新ElasticSearch中IKAnalyzer插件的自定义词库,以获得更好的中文分词和搜索效果。在默认情况下,每次更新之后都需要重启ES集群才能生效,极其不方便。因此IKAnalyzer官方也提供了一种热更新的方法,在其GitHub主页上写道:在其源码内部对应的是Monitor类,实现了Runnable接口。我们采用的ES版本是2.3.2,对应
- IK分词器源码解析(一):构造字典树
Tristeza
最近在搞ES,结合了IK分词器,偶然间看到IK的主词典中有27万的词,加上其他的拓展词库差不多也有小一百万了,于是比较好奇IK是如何判断用户输入的词是否在词库中的,于是索性下载了IK的源码读一读,接下来是分词流程的解析。首先先看一下主类,是一个用来测试的类publicclassIKSegmenterTest{staticStringtext="IKAnalyzer是一个结合词典分词和文法分词的中文
- es ik 词库添加词语_ElasticSearch学习笔记——ik分词添加词库
非流
esik词库添加词语
前置条件是安装ik分词,请参考1.在ik分词的config下添加词库文件~/software/apache/elasticsearch-6.2.4/config/analysis-ik$ls|grepmydic.dicmydic.dic内容为我给祖国献石油2.配置词库路径,编辑IKAnalyzer.cfg.xml配置文件,添加新增的词库3.重启es4.测试data.json{"analyzer":
- IKAnalyzer2012FF_u1.jar 以及PinYin4J 使用出现的问题
YangFanJ
异常异常处理solr
1.jar包不存在于maven仓库需要添加到仓库中或者使用本地依赖。org.wltea.ik-analyzerik-analyzer2012FF_u1system${basedir}/src/main/webapp/WEB-INF/lib/IKAnalyzer2012FF_u1.jar-->C:/Users/Administrator/Desktop/ik/IKAnalyzer2012FF_u1.
- ik分词和jieba分词哪个好_Jieba&IK Analyzer——分词工具的比较与使用
weixin_39943000
ik分词和jieba分词哪个好
现有的分词工具包概览现有的分词工具包种类繁多,我选取了几个比较常见的开源中文分词工具包进行了简单的调查。有感兴趣的同学可以通过下表中的Giuthub链接进行详细地了解。常见开源的中文分词工具接下来,我具体介绍Jieba和IKAnalyzer的使用。一、jieba的分词使用1、安装jieba安装jieba2、三种分词模式及比较编写代码对“古蜀青铜艺术与蜀绣非遗技艺结合创新的探讨——现代首饰设计”进行
- 基于IKAnalyzer lucener的中文分词-java版本
zhaoyang66
用到2个jar包,本别是lucene-core和IKAnalyzer-lucene,版本号一定要对应,见pox.xml的版本号我这里用的maven仓库地址是:https://maven.aliyun.com/repository/central和https://maven.aliyun.com/repository/publicpox.xml里面的配置如下:com.jianggujinIKAnal
- 【Docker】Docker安装Elasticsearch服务的正确方式
Fire Fish
Dockerdockerelasticsearch
文章目录1.什么是Elasticsearch2.Docker安装Elasticsearch2.1确定Elasticsearch的版本2.2.Docker安装Elasticsearch2.3.给Elasticsearch安装中文分词器IKAnalyzer(可选)点击跳转:Docker安装MySQL、Redis、RabbitMQ、Elasticsearch、Nacos等常见服务全套(质量有保证,内容详
- IKAnalyzer 添加扩展词库和自定义词
赵侠客
搜索引擎ikanalyzer分词扩展
原文链接http://blog.csdn.net/whzhaochao/article/details/50130605IKanalyzer分词器IK分词器源码位置http://git.oschina.net/wltea/IK-Analyzer-2012FFIKanalyzer源码基本配置如图所示是IKanlyzer加载默认配置的路径项目中配置扩展词库如图所示,当我们导入Ikanlyzerjar包
- ik 分词器怎么调用缓存的词库
猹里。
缓存
IK分词器是一个基于Java实现的中文分词器,它支持在分词时调用缓存的词库。要使用IK分词器调用缓存的词库,你需要完成以下步骤:创建IK分词器实例首先,你需要创建一个IK分词器的实例。可以通过以下代码创建一个IK分词器实例:Analyzeranalyzer=newIKAnalyzer();加载词库接下来,你需要将缓存的词库加载到分词器中。可以使用IKAnalyzer类的setConfig方法来加载
- Spring Data Solr搜索引擎的使用
ronybo
分布式系统SpringDataSolr搜索引擎索引库域配置
下一节文章目录一、完成Solr环境安装,中文分析器和业务域的配置1.1Solr安装与配置1.1.1什么是Solr1.1.2Solr安装1.1.3中文分析器IKAnalyzer配置1.2入门小Demo1.2.1引入依赖1.2.2配置文件1.2.3@Field注解二、使用SpringDataSolr完成增删改查操作2.1增加2.2修改2.3查询三、完成批量数据导入功能一、完成Solr环境安装,中文分析
- 无标题文章
炮炮_06ac
Ik分词器有的时候,用户搜索的关键字,可能是一句话,不是很规范。所以在Solr中查询出的时候,就需要将用户输入的关键字进行分词。目前有很多优秀的中文分词组件。本篇只以IKAnalyzer分词为例,讲解如何在solr中及集成中文分词,使用IKAnalyzer的原因IK比其他中文分词维护的勤快,和Solr集成也相对容易。具体就不多介绍,这里直接solr集成IK的方法.分词的测试使用curl或者post
- 2018-11-09 Solr学习笔记(一)-Solr5.5.5服务器搭建详细教程
知者半省者无
2018-11-09Solr5.5.5服务器搭建详细教程[TOC]1.solr、jdk、tomcat、IKAnalyzer要求a注意:solr5以上的的标配tomcat8+jdk1.8本教程使用的版本是:solr5:solr-5.5.5tomcat8:apache-tomcat-8.5.35-windows-x64jdk8:jdk-8u181-windows-x64.exeIKAnalyzer:i
- ik分词器的拓展
xzm_
esIk分词器elasticsearch
注意在IkAnalyzer.xml的同级目录下创建自己的文件并进行编辑例:(每一行为一个词,如果在拓展字典中则是新增词汇,如果在删除字典中,则代表此词不参与分词)奥里给tmd
- elasticsearch分词器词库热更新三种方案
喜欢粉红的糙汉
elasticsearchjdbc数据库javamysql
文章目录一、本地文件读取方式二、远程扩展热更新IK分词三、重写ik源码连接mysql一、本地文件读取方式首先进入elasticsearch目录的plugins目录下,查看目录结构2.进入confg目录下创建文件mydic.dic并添加:“我是中国人”3.打开config目录下IKAnalyzer.cfg.xml配置文件vimIKAnalyzer.cfg.xml修改内容如下:4.保存启动es观察日志
- ElasticSearch集群配置IK分词
水彩橘子
大数据
1、环境介绍操作系统:centos7.9elasticsearch版本:7.13.3IK分词版本:elasticsearch-analysis-ik-7.13.3IK分词下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases注意:下载分词要和elasticsearch版本对应2、配置自定义字典IKAnalyzer扩展配置my
- ES集群添加IK分词器
夜月行者
#使用经验elasticsearch搜索引擎大数据
ES集群添加IK分词器ES:7.5.0官方文档其实已经够优秀了,毕竟是中文的,这里只给出一些建议。IKAnalyzer.cfg.xml建议放到插件的目录下,要不然有可能会有一些问题{plugins}/elasticsearch-analysis-ik-*/config/IKAnalyzer.cfg.xml提供的http接口要支持head请求locationhttp://xxx.com/xxx.di
- ElasticSearch集群
小乞丐程序员
elasticsearchlucene搜索引擎
5.2IK分词器简介IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
- IK分词器配置文件讲解以及自定义词库实战
Shaw_Young
1、ik配置文件ik配置文件地址:es/plugins/ik/config目录IKAnalyzer.cfg.xml:用来配置自定义词库main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起quantifier.dic:放了一些单位相关的词suffix.dic:放了一些后缀surname.dic:中国的姓氏stopword.dic:英文停用词ik原生最重要的两个配
- IKSegmenter 分词
开发老张
JavajavaIKSegmenter分词搜索智能分词
使用IKSegmenter进行字符串的分词操作packagecom.zsoft.test;importjava.io.StringReader;importorg.wltea.analyzer.core.IKSegmenter;importorg.wltea.analyzer.core.Lexeme;/***测试IKAnalyzer分词架构中的独立使用分词方法IKSegmenter*需要加载IKA
- ElasticSearch 中文分词器对比
阳关彩虹小白马
常用的中文分词器SmartChineseAnalysis:官方提供的中文分词器,不好用。IKAnalyzer:免费开源的java分词器,目前比较流行的中文分词器之一,简单、稳定,想要特别好的效果,需要自行维护词库,支持自定义词典。结巴分词:开源的python分词器,github有对应的java版本,有自行识别新词的功能,支持自定义词典。Ansj中文分词:基于n-Gram+CRF+HMM的中文分词的
- Elasticsearch的基本操作
wudl
1.es的集成ik分词1.1ik分词IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene
- Elasticsearch的IK分词器配置说明
simonsgj
1、IK配置文件ik配置文件地址:es/plugins/ik/config目录下IKAnalyzer.cfg.xml:用来配置自定义词库main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起quantifier.dic:放了一些单位相关的词suffix.dic:放了一些后缀surname.dic:中国的姓氏stopword.dic:英文停用词2、ik原生最重要的
- MapReduce的案列
卿恋今生
1、汉字分词工具使用,以及统计每个汉字出现的次数思路:Wordcount—>难点怎么去切分一个词汇:中国很大,很美,很富有。Map---->v:一行文本内容,。“”‘’IKAnalyzer2012_u6_source.jarIKAnalyzer2012_u62、输出每个月平均气温思路:求平均值---->难点:怎么去设定MapOutKey—年份月份作为key3对:Mapper–>Reducer–>–
- 搜索引擎ES--IK分词器
李嘉图呀李嘉图
ElasticSearch搜索引擎elasticsearch
目录集成IK分词器扩展词典使用停用词典使用同义词典使用集成IK分词器概要:IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。新版本的IKAnalyzer3.0发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。3.0特性:1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。2)采用了多子处理器分析
- Elasticsearch安装IK分词器,kibana安装是基本使用,DSL语句入门
strive_day
ElasticSearch环境安装elasticsearchkibanaDSLikjson
文章目录1.安装IK分词器2.Kibana安装和使用2.1ELK概述2.2Kibana下载2.3DSL语句1.安装IK分词器ElasticSearch默认采用的分词器,是单个字分词,效果很差,所以我们需要安装一个更实用的分词器,这里采用IK分词器中文分词器IKAnalyzer3.0发布jar包下载地址:https://github.com/medcl/elasticsearch-analysis-
- 解线性方程组
qiuwanchi
package gaodai.matrix;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Test {
public static void main(String[] args) {
Scanner scanner = new Sc
- 在mysql内部存储代码
annan211
性能mysql存储过程触发器
在mysql内部存储代码
在mysql内部存储代码,既有优点也有缺点,而且有人倡导有人反对。
先看优点:
1 她在服务器内部执行,离数据最近,另外在服务器上执行还可以节省带宽和网络延迟。
2 这是一种代码重用。可以方便的统一业务规则,保证某些行为的一致性,所以也可以提供一定的安全性。
3 可以简化代码的维护和版本更新。
4 可以帮助提升安全,比如提供更细
- Android使用Asynchronous Http Client完成登录保存cookie的问题
hotsunshine
android
Asynchronous Http Client是android中非常好的异步请求工具
除了异步之外还有很多封装比如json的处理,cookie的处理
引用
Persistent Cookie Storage with PersistentCookieStore
This library also includes a PersistentCookieStore whi
- java面试题
Array_06
java面试
java面试题
第一,谈谈final, finally, finalize的区别。
final-修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承。因此一个类不能既被声明为 abstract的,又被声明为final的。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在声明时给定初值,而在以后的引用中只能
- 网站加速
oloz
网站加速
前序:本人菜鸟,此文研究总结来源于互联网上的资料,大牛请勿喷!本人虚心学习,多指教.
1、减小网页体积的大小,尽量采用div+css模式,尽量避免复杂的页面结构,能简约就简约。
2、采用Gzip对网页进行压缩;
GZIP最早由Jean-loup Gailly和Mark Adler创建,用于UNⅨ系统的文件压缩。我们在Linux中经常会用到后缀为.gz
- 正确书写单例模式
随意而生
java 设计模式 单例
单例模式算是设计模式中最容易理解,也是最容易手写代码的模式了吧。但是其中的坑却不少,所以也常作为面试题来考。本文主要对几种单例写法的整理,并分析其优缺点。很多都是一些老生常谈的问题,但如果你不知道如何创建一个线程安全的单例,不知道什么是双检锁,那这篇文章可能会帮助到你。
懒汉式,线程不安全
当被问到要实现一个单例模式时,很多人的第一反应是写出如下的代码,包括教科书上也是这样
- 单例模式
香水浓
java
懒汉 调用getInstance方法时实例化
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if(null == ins
- 安装Apache问题:系统找不到指定的文件 No installed service named "Apache2"
AdyZhang
apachehttp server
安装Apache问题:系统找不到指定的文件 No installed service named "Apache2"
每次到这一步都很小心防它的端口冲突问题,结果,特意留出来的80端口就是不能用,烦。
解决方法确保几处:
1、停止IIS启动
2、把端口80改成其它 (譬如90,800,,,什么数字都好)
3、防火墙(关掉试试)
在运行处输入 cmd 回车,转到apa
- 如何在android 文件选择器中选择多个图片或者视频?
aijuans
android
我的android app有这样的需求,在进行照片和视频上传的时候,需要一次性的从照片/视频库选择多条进行上传
但是android原生态的sdk中,只能一个一个的进行选择和上传。
我想知道是否有其他的android上传库可以解决这个问题,提供一个多选的功能,可以使checkbox之类的,一次选择多个 处理方法
官方的图片选择器(但是不支持所有版本的androi,只支持API Level
- mysql中查询生日提醒的日期相关的sql
baalwolf
mysql
SELECT sysid,user_name,birthday,listid,userhead_50,CONCAT(YEAR(CURDATE()),DATE_FORMAT(birthday,'-%m-%d')),CURDATE(), dayofyear( CONCAT(YEAR(CURDATE()),DATE_FORMAT(birthday,'-%m-%d')))-dayofyear(
- MongoDB索引文件破坏后导致查询错误的问题
BigBird2012
mongodb
问题描述:
MongoDB在非正常情况下关闭时,可能会导致索引文件破坏,造成数据在更新时没有反映到索引上。
解决方案:
使用脚本,重建MongoDB所有表的索引。
var names = db.getCollectionNames();
for( var i in names ){
var name = names[i];
print(name);
- Javascript Promise
bijian1013
JavaScriptPromise
Parse JavaScript SDK现在提供了支持大多数异步方法的兼容jquery的Promises模式,那么这意味着什么呢,读完下文你就了解了。
一.认识Promises
“Promises”代表着在javascript程序里下一个伟大的范式,但是理解他们为什么如此伟大不是件简
- [Zookeeper学习笔记九]Zookeeper源代码分析之Zookeeper构造过程
bit1129
zookeeper
Zookeeper重载了几个构造函数,其中构造者可以提供参数最多,可定制性最多的构造函数是
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolea
- 【Java命令三】jstack
bit1129
jstack
jstack是用于获得当前运行的Java程序所有的线程的运行情况(thread dump),不同于jmap用于获得memory dump
[hadoop@hadoop sbin]$ jstack
Usage:
jstack [-l] <pid>
(to connect to running process)
jstack -F
- jboss 5.1启停脚本 动静分离部署
ronin47
以前启动jboss,往各种xml配置文件,现只要运行一句脚本即可。start nohup sh /**/run.sh -c servicename -b ip -g clustername -u broatcast jboss.messaging.ServerPeerID=int -Djboss.service.binding.set=p
- UI之如何打磨设计能力?
brotherlamp
UIui教程ui自学ui资料ui视频
在越来越拥挤的初创企业世界里,视觉设计的重要性往往可以与杀手级用户体验比肩。在许多情况下,尤其对于 Web 初创企业而言,这两者都是不可或缺的。前不久我们在《右脑革命:别学编程了,学艺术吧》中也曾发出过重视设计的呼吁。如何才能提高初创企业的设计能力呢?以下是 9 位创始人的体会。
1.找到自己的方式
如果你是设计师,要想提高技能可以去设计博客和展示好设计的网站如D-lists或
- 三色旗算法
bylijinnan
java算法
import java.util.Arrays;
/**
问题:
假设有一条绳子,上面有红、白、蓝三种颜色的旗子,起初绳子上的旗子颜色并没有顺序,
您希望将之分类,并排列为蓝、白、红的顺序,要如何移动次数才会最少,注意您只能在绳
子上进行这个动作,而且一次只能调换两个旗子。
网上的解法大多类似:
在一条绳子上移动,在程式中也就意味只能使用一个阵列,而不使用其它的阵列来
- 警告:No configuration found for the specified action: \'s
chiangfai
configuration
1.index.jsp页面form标签未指定namespace属性。
<!--index.jsp代码-->
<%@taglib prefix="s" uri="/struts-tags"%>
...
<s:form action="submit" method="post"&g
- redis -- hash_max_zipmap_entries设置过大有问题
chenchao051
redishash
使用redis时为了使用hash追求更高的内存使用率,我们一般都用hash结构,并且有时候会把hash_max_zipmap_entries这个值设置的很大,很多资料也推荐设置到1000,默认设置为了512,但是这里有个坑
#define ZIPMAP_BIGLEN 254
#define ZIPMAP_END 255
/* Return th
- select into outfile access deny问题
daizj
mysqltxt导出数据到文件
本文转自:http://hatemysql.com/2010/06/29/select-into-outfile-access-deny%E9%97%AE%E9%A2%98/
为应用建立了rnd的帐号,专门为他们查询线上数据库用的,当然,只有他们上了生产网络以后才能连上数据库,安全方面我们还是很注意的,呵呵。
授权的语句如下:
grant select on armory.* to rn
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('This example should only be run from a Web Brows
- 美国电影超短200句
dcj3sjt126com
电影
1. I see. 我明白了。2. I quit! 我不干了!3. Let go! 放手!4. Me too. 我也是。5. My god! 天哪!6. No way! 不行!7. Come on. 来吧(赶快)8. Hold on. 等一等。9. I agree。 我同意。10. Not bad. 还不错。11. Not yet. 还没。12. See you. 再见。13. Shut up!
- Java访问远程服务
dyy_gusi
httpclientwebservicegetpost
随着webService的崛起,我们开始中会越来越多的使用到访问远程webService服务。当然对于不同的webService框架一般都有自己的client包供使用,但是如果使用webService框架自己的client包,那么必然需要在自己的代码中引入它的包,如果同时调运了多个不同框架的webService,那么就需要同时引入多个不同的clien
- Maven的settings.xml配置
geeksun
settings.xml
settings.xml是Maven的配置文件,下面解释一下其中的配置含义:
settings.xml存在于两个地方:
1.安装的地方:$M2_HOME/conf/settings.xml
2.用户的目录:${user.home}/.m2/settings.xml
前者又被叫做全局配置,后者被称为用户配置。如果两者都存在,它们的内容将被合并,并且用户范围的settings.xml优先。
- ubuntu的init与系统服务设置
hongtoushizi
ubuntu
转载自:
http://iysm.net/?p=178 init
Init是位于/sbin/init的一个程序,它是在linux下,在系统启动过程中,初始化所有的设备驱动程序和数据结构等之后,由内核启动的一个用户级程序,并由此init程序进而完成系统的启动过程。
ubuntu与传统的linux略有不同,使用upstart完成系统的启动,但表面上仍维持init程序的形式。
运行
- 跟我学Nginx+Lua开发目录贴
jinnianshilongnian
nginxlua
使用Nginx+Lua开发近一年的时间,学习和实践了一些Nginx+Lua开发的架构,为了让更多人使用Nginx+Lua架构开发,利用春节期间总结了一份基本的学习教程,希望对大家有用。也欢迎谈探讨学习一些经验。
目录
第一章 安装Nginx+Lua开发环境
第二章 Nginx+Lua开发入门
第三章 Redis/SSDB+Twemproxy安装与使用
第四章 L
- php位运算符注意事项
home198979
位运算PHP&
$a = $b = $c = 0;
$a & $b = 1;
$b | $c = 1
问a,b,c最终为多少?
当看到这题时,我犯了一个低级错误,误 以为位运算符会改变变量的值。所以得出结果是1 1 0
但是位运算符是不会改变变量的值的,例如:
$a=1;$b=2;
$a&$b;
这样a,b的值不会有任何改变
- Linux shell数组建立和使用技巧
pda158
linux
1.数组定义 [chengmo@centos5 ~]$ a=(1 2 3 4 5) [chengmo@centos5 ~]$ echo $a 1 一对括号表示是数组,数组元素用“空格”符号分割开。
2.数组读取与赋值 得到长度: [chengmo@centos5 ~]$ echo ${#a[@]} 5 用${#数组名[@或
- hotspot源码(JDK7)
ol_beta
javaHotSpotjvm
源码结构图,方便理解:
├─agent Serviceab
- Oracle基本事务和ForAll执行批量DML练习
vipbooks
oraclesql
基本事务的使用:
从账户一的余额中转100到账户二的余额中去,如果账户二不存在或账户一中的余额不足100则整笔交易回滚
select * from account;
-- 创建一张账户表
create table account(
-- 账户ID
id number(3) not null,
-- 账户名称
nam