Hadoop深入学习:HDFS主要流程——写文件
本节我们主要学习HDFS主流程中的写文件的整个流程。
向HDFS中写入数据,即使不考虑节点出戳后的故障处理,也是最复杂的流程。
相关的些命令有:
在向HDFS的写操作中,不得不提以下 “数据流管道”。数据流管道在Google实现他们的分布式文件系统(GFS)时就已引入, 其目的是:在写一份数据的多个副本时,可以充分利用集群中每一台机器的带宽,避免网络瓶颈和高延时的连接,最小化推送所有数据的延时。
Hadoop的HDFS也实现了自己的数据流管道,如下图所示:
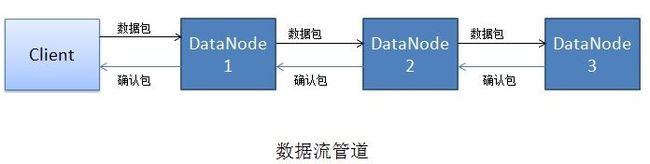
假设HDFS中的文件副本被配置成3个,也就是说,在该HDFS集群上,一共会有三个数据节点来保存一个数据文件的副本。在写数据的时候,不是同时往三个DateNode节点上写数据,而是将数据发送到第一个数据节点 DateNode 1,然后在第一个DateNode节点在本地保存数据的同时,将数据推送到第二个数据节点 DateNode 2,同理在第二个节点本地保存数据的同时,也会由第二个数据节点将数据同送给第三个数据节点 DateNode 3;确认包有最后一个数据节点产生,沿途的数据节点在确认本地写成功后,才往上游传递确认应答。这样处于管道上的每个节点都承担了写数据时的部分网络流量,降低了客户端发送多分数据时对网络的冲击。
本节我们就一向HDFSzhong写一个新文件为例,描述一个整个过程。首先先看一下流程示意图:
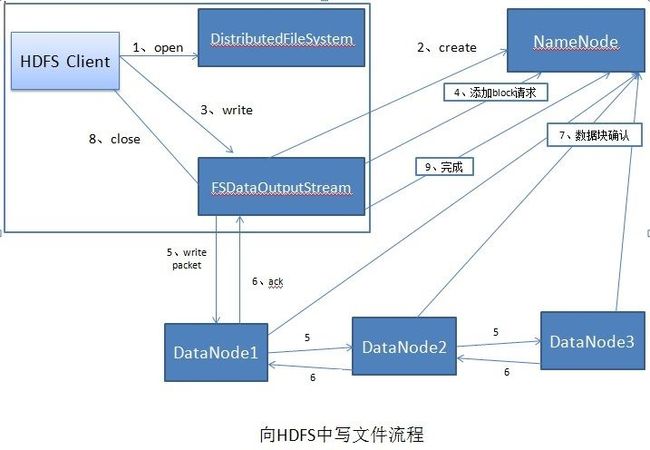
具体步骤如下:
1)、客户端调用DistributedFileSystem的create()方法,创建新文件(上图中的第1步),这时DistributedFileSystem创建DFSOutputStream,并由用远程调用,让NameNode节点执行同名方法在文件系统的命名空间中创建这一新文件。在DataNode中创建新节点时,需要执行各种检查,如DataNode是否处于正常状态,被创建文件是否存在,客户端是否有权限创建文件,这些检查都通过后才会创建一个新文件,并将操作记录到编辑日志。远程方法调用完后,DistributedFileSystem会将DFSOutputStream对象包装在FSDataOutStream实例中,返回客户端;
2)、在客户端写入数据时,由于之前创建的时空文件,所以FSDataOutStream对象会向NameNode节点申请数据块并得到可以保存数据块的DataNode节点,然后FSDataOutStream就会和DataNode节点联系建立数据流管道;
3)、建立数据流管道后,客户端写入FSDataOutStream流中的数据,被分成一个一个的文件包,放入FSDataOutStream流中的内部队列。该队列中的文件包最后被打包成数据包,发往数据流管道,流经管道上的各个DateNode节点并持久化;
4)、确认包按数据流管道的逆方向向上一个DataNode节点发送确认包,当客户端收到确认包后,就将对应的包从内部队列中删除;
5)、FSDataOutStream在写玩一个数据块后,数据流管道上的节点会向NameNode节点提交数据块,如果数据队列中还有待输出数据,FSDataOutStream对象会再次向NameNode申请新的数据块节点,为文件添加在新的数据块;
6)、客户端写完数据后关闭输出流,然后再通知NameNode节点关闭文件,从而完成一次正常的写文件操作。
如果在写数据期间,数据节点发生故障怎么办呢?首先数据流管道会被关闭,已经发送到管道但还没有收到确认的文件包,会重新添加到FSDataOutStream的输出队列,这样就保证了无论数据流管道中的哪个节点有故障,都不会丢失数据;然后当前正常工作的数据节点上的数据块会被赋予一个新的版本号,并通知NameNode节点,这样在失败的DataNode节点恢复过来后将删除与NameNode节点中版本号不一致的数据块,然后在数据流管道中删除错误DataNode节点并重新建立新管道连接,继续像正常的DataNode节点写数据。
、在写数据的过程中,有可能出现多于一个数据节点出现故障的情况,这时只要管道中的数据节点数目满足配置项${dfs.replication.min}的值,改制默认为1,就认为写操作是成功的,后续这些数据快后被复制,直到满足配置的${dfs.replication}的值的数目。
向HDFS中写入数据,即使不考虑节点出戳后的故障处理,也是最复杂的流程。
相关的些命令有:
hadoop fs -put example.txt //写单个文件
hadoop fs -CopyFromLocal /data/test/foo /data/test //写多个文件
在向HDFS的写操作中,不得不提以下 “数据流管道”。数据流管道在Google实现他们的分布式文件系统(GFS)时就已引入, 其目的是:在写一份数据的多个副本时,可以充分利用集群中每一台机器的带宽,避免网络瓶颈和高延时的连接,最小化推送所有数据的延时。
Hadoop的HDFS也实现了自己的数据流管道,如下图所示:
假设HDFS中的文件副本被配置成3个,也就是说,在该HDFS集群上,一共会有三个数据节点来保存一个数据文件的副本。在写数据的时候,不是同时往三个DateNode节点上写数据,而是将数据发送到第一个数据节点 DateNode 1,然后在第一个DateNode节点在本地保存数据的同时,将数据推送到第二个数据节点 DateNode 2,同理在第二个节点本地保存数据的同时,也会由第二个数据节点将数据同送给第三个数据节点 DateNode 3;确认包有最后一个数据节点产生,沿途的数据节点在确认本地写成功后,才往上游传递确认应答。这样处于管道上的每个节点都承担了写数据时的部分网络流量,降低了客户端发送多分数据时对网络的冲击。
本节我们就一向HDFSzhong写一个新文件为例,描述一个整个过程。首先先看一下流程示意图:
具体步骤如下:
1)、客户端调用DistributedFileSystem的create()方法,创建新文件(上图中的第1步),这时DistributedFileSystem创建DFSOutputStream,并由用远程调用,让NameNode节点执行同名方法在文件系统的命名空间中创建这一新文件。在DataNode中创建新节点时,需要执行各种检查,如DataNode是否处于正常状态,被创建文件是否存在,客户端是否有权限创建文件,这些检查都通过后才会创建一个新文件,并将操作记录到编辑日志。远程方法调用完后,DistributedFileSystem会将DFSOutputStream对象包装在FSDataOutStream实例中,返回客户端;
2)、在客户端写入数据时,由于之前创建的时空文件,所以FSDataOutStream对象会向NameNode节点申请数据块并得到可以保存数据块的DataNode节点,然后FSDataOutStream就会和DataNode节点联系建立数据流管道;
3)、建立数据流管道后,客户端写入FSDataOutStream流中的数据,被分成一个一个的文件包,放入FSDataOutStream流中的内部队列。该队列中的文件包最后被打包成数据包,发往数据流管道,流经管道上的各个DateNode节点并持久化;
4)、确认包按数据流管道的逆方向向上一个DataNode节点发送确认包,当客户端收到确认包后,就将对应的包从内部队列中删除;
5)、FSDataOutStream在写玩一个数据块后,数据流管道上的节点会向NameNode节点提交数据块,如果数据队列中还有待输出数据,FSDataOutStream对象会再次向NameNode申请新的数据块节点,为文件添加在新的数据块;
6)、客户端写完数据后关闭输出流,然后再通知NameNode节点关闭文件,从而完成一次正常的写文件操作。
如果在写数据期间,数据节点发生故障怎么办呢?首先数据流管道会被关闭,已经发送到管道但还没有收到确认的文件包,会重新添加到FSDataOutStream的输出队列,这样就保证了无论数据流管道中的哪个节点有故障,都不会丢失数据;然后当前正常工作的数据节点上的数据块会被赋予一个新的版本号,并通知NameNode节点,这样在失败的DataNode节点恢复过来后将删除与NameNode节点中版本号不一致的数据块,然后在数据流管道中删除错误DataNode节点并重新建立新管道连接,继续像正常的DataNode节点写数据。
、在写数据的过程中,有可能出现多于一个数据节点出现故障的情况,这时只要管道中的数据节点数目满足配置项${dfs.replication.min}的值,改制默认为1,就认为写操作是成功的,后续这些数据快后被复制,直到满足配置的${dfs.replication}的值的数目。