1IO子系统屏蔽了不同io设备的差异。
2 IO过程图,一个IO过程也是要消耗很多的cpu时间的。

- 用户进程对已打开文件的文件描述符调用阻塞read系统调用。
- 内核系统调用代码检查参数的正确性。对于输入,如果数据已经在高速缓存中,那么直接返回数据给用户进程,并完成io请求。
- 否则就执行物理的io请求。该进程也会从运行队列转移到设备的等待队列,并调度io请求。io子系统会向设备驱动程序发起io请求。
- 设备驱动程序会开辟内存空间已接收数据,并调度io。最后,设备驱动程序通过写入设备控制器的寄存器来对设备控制器发起命令。
- 设备控制器控制设备硬件以执行数据传输。
- 驱动程序轮询检查状态和数据,或设置DMA将数据传到内核内存。假定DMA控制器管理传输,当传输完成后产生中断。
- 合适的中断处理程序通过中断向量表收到中断,保存必要数据,并向内核设备驱动程序发送通知,然后从中断返回。
- 设备驱动程序接收到信号,确定io请求是否已完成,确定请求状态,并向内核io子系统发送信号,通知请求已完成。
- 内核将数据或者返回代码传递给发送请求的进程的地址空间,将进程从等待队列移到就绪队列。
- 移到就绪队列后,进程不再阻塞。当调度器给进程分配cpu时,该进程就可以在系统调用后完成后续的操作
3 磁盘是基于块的设备,键盘、鼠标是基于字符的设备。块和字符是操作系统逻辑上的概念,块设备提供read()\write()\seek()接口,而字符设备则是get()\put()接口。
4 直接io,内存映射文件访问是基于块设备的。内存映射接口不提供read,write操作,而是直接通过内存byte数组来访问磁盘数据,这种io方式比传统的更为高效
5 DMA直接内存访问,是用来避免程序控制io(PIO)产生的cpu负担。在无cpu的帮助下进行数据传输。DMA控制器直接和设备控制器进行通信。
6 同步io和异步io。同步阻塞调用,线程挂起,会从操作系统运行队列转移到等待队列;等系统调用完成后,线程在回到运行队列。
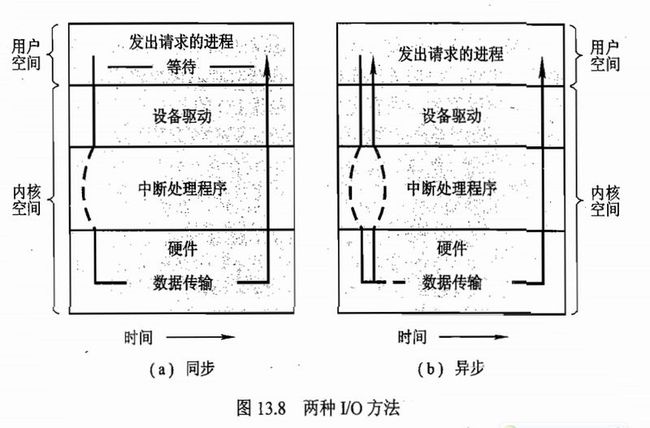
同步与异步的区别在于,同步是发起请求的线程,需要自己去check数据是否已经准备好,而异步则是通过事件触发的机制,有另外一个线程来通知数据已经准备好;阻塞与非阻塞的区别是,阻塞调用在数据准备好之前不会返回,非阻塞调用则是直接返回。
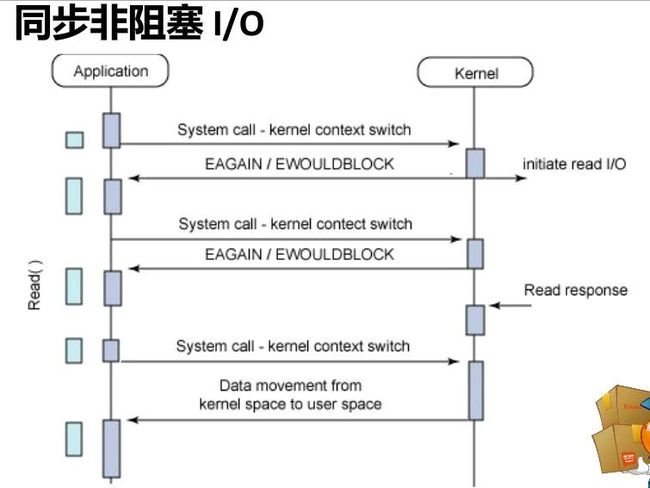

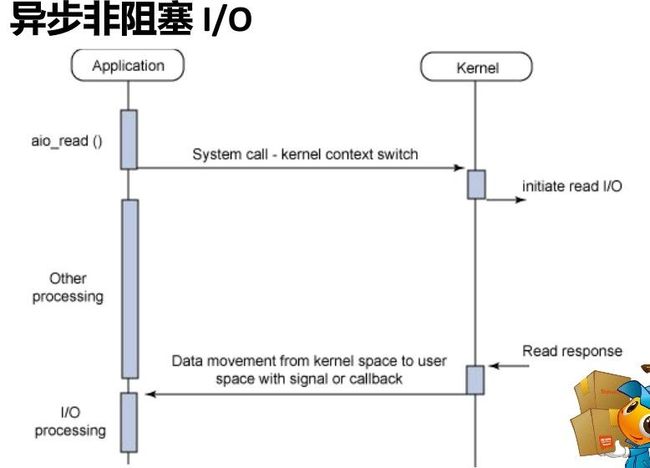
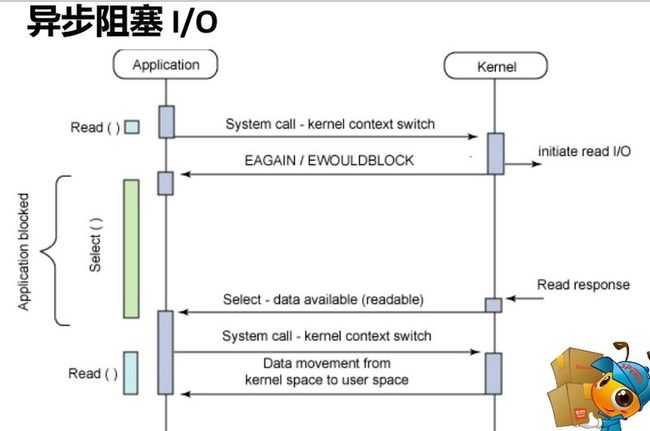
7 cpu调度发生调度决策,有以下四种:
》 进程进入等待io区间。
》进程从运行状态切换到就绪状态,例如中断
》进程从等待状态切换到就绪状态,例如IO完成
》进程运行终止。
1和4出现时,没有选择只有调度。当cpu调度只会在1 4发生时,成为非抢占式,只有当线程进入io等待和进程结束时才调度,一根筋跑到底;其他的为抢占式。
8 cpu调度算法的分类:
》先到先得服务,实现简单,但是如果遇到第一个进程是长cpu区间的,会导致平均rt变长。
》最短剩余时间优先调度,一般是抢占式的,他具有最小的平均响应时间的优势,难度在于很难预测就绪队列中的进程cpu区间长度。
》第2种是优先级调度算法的一种特例,用户可以给进程分配优先级。这种调度策略可以是抢占式和非抢占式的,他的一个致命缺点就是,优先级低的会饥饿。需要通过老化算法来平衡,老化的时候,提高优先级。
》轮转法,10~100ms为一个时间片,就绪队列是一种循环队列,如果任务在一个时间片内完成,cpu调度下一个任务。如果任务在一个时间片内完不成,cpu将之放入队列尾部,调度下一个任务。这种算法的性能,取决于时间片和任务的cpu时间的平衡。当时间片超大时,效果和先到先得服务一样。
》多级队列调度,不同任务进入不同优先级的队列,cpu优先调度高优先级队列。每个队列根据特点采用不同的调度算法,如轮转法,先到先得法。
》多级反馈队列,上一个算法的升级版,最智能也最复杂,根据进程的特点反馈,移动进程到另一个优先级的队列。
linux采用了优先级队列的抢占式调度方法,0-99实时优先级,100-140的nice优先级,数值越低优先级越高。
不同优先级队列分配不一样的时间片,越高优先级时间片越高,10-200ms。任务耗尽其时间片则从活动队列转移至到期队列,等活动队列的任务都耗尽其时间片,那么到期队列切换成活动队列。一般来说,越耗cpu的任务,优先级会更低。
9 文件系统存储基于磁盘块,块大小取决于磁盘的扇区。操作系统将逻辑位置和物理磁盘块映射起来,让应用程序得以访问文件。文件可以是普通文本,也可以是结构化的。对于文件本身来说都是byte流,由应用程序去解释。
访问可以分为直接访问和顺序访问,直接访问必须具备一定的索引结构。顺序访问可以用直接访问来模拟。
直接访问和顺序访问的模式类似于数据库的查询,全表扫描和索引查询。
10 文件空间分配可以是连续分配或者是链式分配,连续分配具备高性能的随机访问,就跟顺序存储的数组一样,可以迅速的定位块i,在尽可能少的磁盘寻道次数下,缺点是外部碎片会比较大;链式分配就如同链表,在分配空间时较为灵活,尽可能少的外部碎片,但是随机访问性能太差,需要多次寻道,一般会通过文件分配表FAT、索引块来提高性能。各有利弊,有些操作系统会同时采用这两种机制,根据文件访问的特点,以及大小,动态切换分配方式。
对于空闲空间的管理,一般会采用位图,每个块(一般来说是512b)或者簇占用一位。
11 总线是一组线和一组严格定义的可以描述在线上传输信息的协议,用电子学的话说,信息是通过线上具有一定时序的电压模式来传送的。图中的pci总线是用来连接处理器-内存子系统和快速设备的,扩展总线是用于连接串行、并行端口和相对较慢的设备,如键盘。
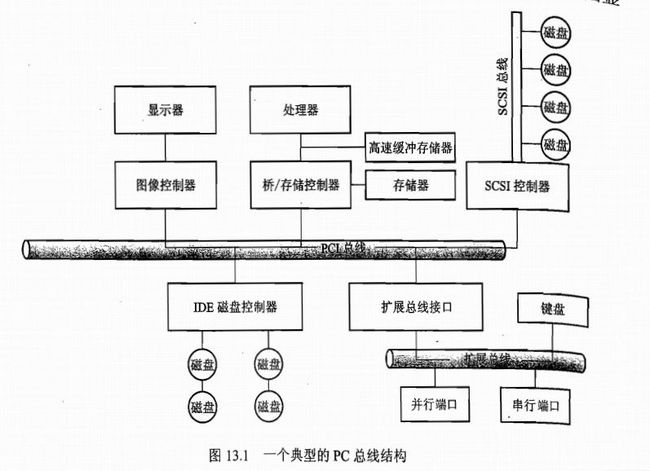
控制器是用于操作端口、总线或设备的一组电子器件。
主机完成io数据传输的过程是通过cpu和控制器的状态、数据、控制寄存器以某种协议完成的。
例如输出数据的协议-轮询:
- 主机不断读取控制器的状态寄存器的忙位,直到控制器处于闲时
- 主机set命令寄存器的写位,并向数据输出寄存器写入一个字节。
- 主机设置命令就绪位
- 控制器注意到主机命令就绪,那么则set状态为忙时。
- 控制器读取命令寄存器为写,并向数据输出寄存器读取一个字节,并向设备执行io操作。
- 控制器清除命令就绪位,清除状态寄存器的故障位表示为设备io成功,清除忙位表示完成。
轮询是忙等待,在某些情况下效率低,于是就有了中断机制,即让外部设备完成io时通知处理器。
cpu硬件有一条中断请求线IRL,cpu每执行完一条指令,都会检测IRL。当发现有控制器发送的中断请求信号,那么cpu会保留当前的状态,然后跳转到中断处理程序进行处理。这一个特性使得cpu能够响应异步事件。其实现在的io编程的反应器模式就是采用这样的思路来设计的。
例如当io输出已经完成或者输入数据已经就绪,那么设备控制器就会触发中断。触发中断事件的共同特点是:他们会让cpu去执行一个紧迫的自我独立的程序的事件。中断处理程序根据不同的事件会有不同的优先级。

12 io子系统的优化
IO调度是通过确定一个合理的执行顺序还提高io效率,例如磁盘读,可以优化执行顺序来减少磁头移动距离,提高平均响应速度。
使用缓冲,用于保存设备之间,设备和应用程序之间所传输数据的内存区域。用途有:
- 处理数据生产者和消费者的速度差异,累积数据,批量处理
- 用于协调传输数据大小不一致的问题。例如消息发送和接收,会有半包和粘包的问题,需要一个缓冲区来重组一个完整的消息。
- 用于支持应用程序的io复制语义,例如写数据时传入一个缓冲区,操作系统把这个数据复制到内核缓冲区,后面程序对用户缓冲区进行的修改都不会影响之前写入的版本,这边的copy on write的语义。
使用高速缓存,直接从内存中读数据,避免io操作。
13 io的性能
执行设备驱动程序,中断处理,io调度、上下文切换都很消耗cpu。如果忙等待的计算周期不长的话,那么程序控制io会比中断驱动更为有效,这也使用自旋锁的一个原因。
优化原则:
- 减少上下文切换
- 减少设备和应用程序之间传输数据在内存的数据复制次数
- 通过使用大传输、智能控制器、轮询(使忙等待最小化),以减少中断频率
- 使用DMA减少cpu负担
- 将处理原语移入硬件
- 平衡cpu、内存子系统、总线和io的性能
14 虚拟内存
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
http://www.oschina.net/translate/what-every-programmer-should-know-about-memory-part1
15 内存管理
cpu只能直接访问到cpu寄存器,高速缓存和内存。
一个典型的cpu执行指令,首先根据pc程序计数器从内存中读取指令,接着指令被解码,可能需要从内存中读取操作数。指令对操作数执行完之后,还可能需要存入内存。执行指令,和执行指令需要的数据都必须要先载入到内存中。
每个进程都有独立的访问空间,cpu通过基地址寄存器和界限地址寄存器来控制用户进程能够访问到的合法地址范围。
cpu所生成的地址成为逻辑地址,而内存单元看到的为物理地址,运行时逻辑地址到物理地址的映射是通过MMU内存管理单元来完成的。
由于内存空间有限,操作系统要支持多道程序处理时,经常会用到swap技术,当内存吃紧时,把非运行态的进程swap到硬盘中,当要执行进程时,再提前把进程载入到内存中。
连续内存分配,内核维护一个输入队列和一组可用孔大小,采用首次适应、最佳适应和最差适应三种算法来分配内存。一般来说效率最高的算法是首次适应。连续内存分配的缺点是容易产生外部碎片。解决办法是采用压缩,例如把所有的进程移到到一端,所有的空闲孔移动到另外一端,这种方式开销较大。
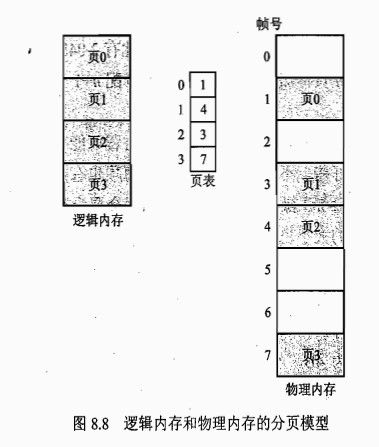
为了解决连续内存分配的问题,操作系统采用分页和分段的技术,允许进程使用非连续的物理内存空间。分页把物理内存分为固定大小的块称为帧,虚拟内存分为页,每一页映射到一个帧。分页模型如下图,分页的优势是不会产生外部碎片,但是当进程需要的内存大小不是页的整数倍的时候,就会出现内部碎片,理论上每个进程产生的内部碎片为0.5个页
分段???