贫血模型与领域模型,在重构中的答案!
我们从一个实例中来分析这个问题,此例子摘自<重构-改善既有代码的设计>.
实例非常简单,这是一个影片出租店用的程序,计算每一位顾客的消费金额并打印报表.操作者告诉程序:顾客租了那些影片,租多长时间,程序更具租凭时间和影片类型算出费用.影片分三类:普通片,儿童片,芯片.除了计算费用,还要为常客积分,积分数会随着[租片种类是否为新片]而又不同.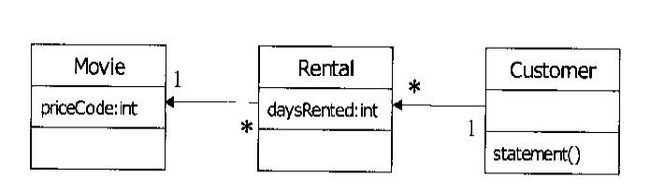
在这张图里,三个对象,Movie和Rental都是没有逻辑的普通JavaBean,Customer只有一个打印报表的方法(返回字符串)
调用关系如图:
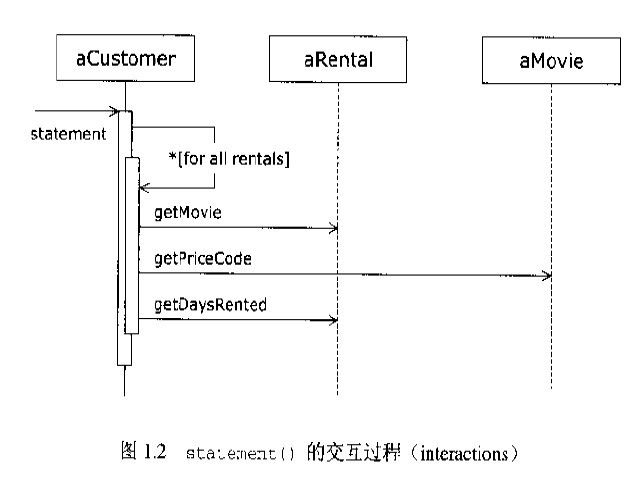
有什么感觉?是不是类似所谓的贫血模式?
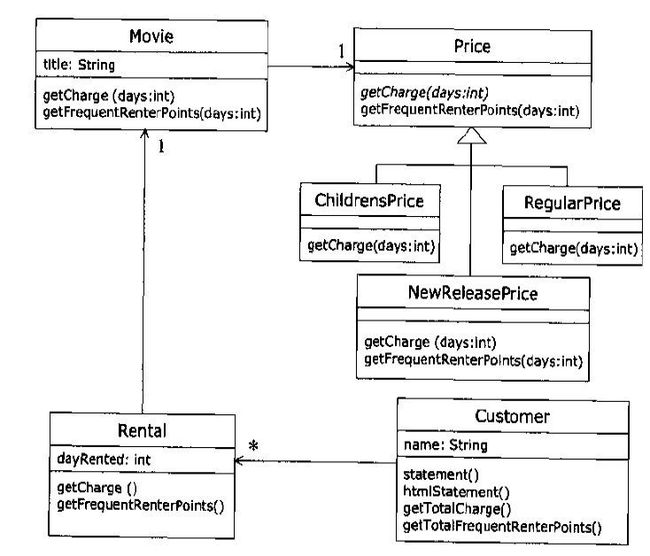
OK 让我们在来看经过重新设计后的类图:
调用过程:
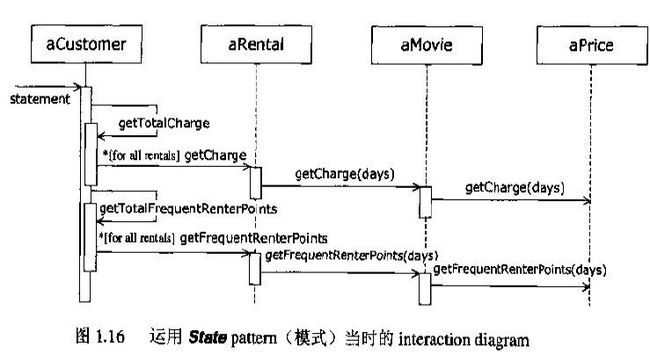
当然,当我们看到这两个类图和调用过程时,我们可以很明显的判断出那个简单,那个复杂.但是复杂的背后带来的好处是显而易见的.(便于维护和扩展,也让我们很清楚的看到我们的"领域").
举个最简单的例子来说明扩展和维护性的差别.客户提出了一个新需求:希望返回的报表不使用字符而是一个HTML.
对于重构前的模式(即Service模式),我们几乎要重新写一个方法来完成客户的新需求,这给我们带来的是:在两个方法中有完全同样的计算方式(程序逻辑),唯一不同的是一个有HTML样式的控制,一个只是一个字符串,这就出现了代码冗余.如果我们需要修改计算方式时,我们需要维护两个代码完全一样的地方,即对同一个功能修改两次.如果随着我们程序的扩大,我们就会很难找出这些代码,并修改他们.
对于使用设计后的类图和调用关系图来解决这个问题,上图已经给出了相当明确的答案.(你想修改任何地方,如计算方式,积分方式...等等,都不影响到他们之外的地方).
还有一个更加重要的好处是,它让我们更加的了解自己程序的领域,我们可以不断的完善,和扩展我们的领域.
对于后者的好处限于篇幅不一一举例.大家可以自己参悟(试想一下你想要加入的,或修改的新功能,分别在这两个设计中的方式,然后对比).
个人认为:领域模型与贫血模型,好处和坏处,大家都可以从其他地方看到,但是至于为什么要争论领域和贫血呢,原因是什么?
可扩展性,和可维护性估计是明显的问题.所以在程序中那些地方将来需要被扩展,那些地方不确定需要被频繁的修改,才是我们关注的.对于一个应用来说,全部贫血肯定妨碍扩展性和维护性,全部领域又显得过度设计.我们只能说是和谐的对待他们,让他们并存,那个占的多,那个占的少,维护性和扩展性也许是个决策的标准.
最后引用Kent Beck的一句话:
