Opentsdb的技术特点
1 客户端
opentsdb的hbase客户端,使用了他们自己编写的异步非阻塞 hbase客户端
据说比hbase自带的客户端性能好很多.
下面是一个评测结果
http://www.tsunanet.net/~tsuna/asynchbase/benchmark/viz.html
2 opentsdb的数据存储
2.1 hbase宽列存储
假设一般关系型数据库存储某指标ABX在2014年5月1日08时左右的如下数据
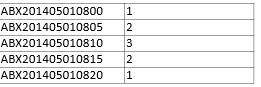
可以看出时间数据前缀有重复,在Hbase中可以通过提取共同前缀,达到减小存储空间,提高存储效率的目标.将上述时序数据在Hbase中以宽列形式存储,逻辑结构表示如下

Hfile中keyvalue的物理存储格式(略去column family和version部分)如下

宽列存储的优势在于Hfile中的row(相同rowkey的keyvalue是一个row)数量会大大减少,提高查询效率,原因如下:
1)Hfile中meta block中会存储bloom filter,用来判定特定的rowkey是否在Hfile中.随着row数量的减少,bloom filter的体积会显著减小,因为bloom filter entry的生成是以row为单位.
2)Hbase中除了rowkey作为检索条件,还可以利用filter在rowkey,keyvalue,keyvalue的集合上进行过滤.在filter执行的早期阶段进行rowkey的比较,如果发现整个row不符合条件,能迅速跳过大量keyvalue,减少filter比对的次数.
2.2 opentsdb的宽列存储的二次compact
宽列存储的硬盘空间节省非常有限,因为keyvalue的数量受column qualifier数量影响.因此可以在宽列存储的基础上进行二次compact,将同一个row的多个column qualifier存储为一个column qualifier.

其keyvalue物理存储格式(略去column family和version部分)为

进过二次compact的时序数据,在存储体积上也显著减小.配合其他压缩算法,可以极大的节省存储空间,提高访问效率.
Opentsdb在添加数据点的时候,把需要compact的row放到一个队列中,然后定时compact.
TSDB的addPointInternal方法中,调用scheduleForCompaction将row放入队列, CompactionQueue类中,启动Thrd这个线程来进行compact
但是有时候一个row已经被compact过了,这个row仍有可能插入数据,所以要对已经compact的row进行第二次compact,所以在scan的时候,仍然有可能进行compact.
ScannerCB类中,每次scan完成仍然调用compact方法进行数据compaction
下图表示一个已经compact的row,插入了新的数据后,又一次进行了compact

3 opents中的tree
Opents中的监控指标都是metric,每个metric都互相独立,带有tag,由用户自定义metric和tag,但是可以通过自定义规则,将metric,tag分解为树的形式进行结构化展现.

比如有上面的metric和tag,可以通过规则(提取tag value,正则表达式分解metric等),变换为如下的tree
先按照数据中心分级,然后按主机,然后按监控类型

opentsdb的hbase客户端,使用了他们自己编写的异步非阻塞 hbase客户端
据说比hbase自带的客户端性能好很多.
下面是一个评测结果
http://www.tsunanet.net/~tsuna/asynchbase/benchmark/viz.html
2 opentsdb的数据存储
2.1 hbase宽列存储
假设一般关系型数据库存储某指标ABX在2014年5月1日08时左右的如下数据
可以看出时间数据前缀有重复,在Hbase中可以通过提取共同前缀,达到减小存储空间,提高存储效率的目标.将上述时序数据在Hbase中以宽列形式存储,逻辑结构表示如下
Hfile中keyvalue的物理存储格式(略去column family和version部分)如下
宽列存储的优势在于Hfile中的row(相同rowkey的keyvalue是一个row)数量会大大减少,提高查询效率,原因如下:
1)Hfile中meta block中会存储bloom filter,用来判定特定的rowkey是否在Hfile中.随着row数量的减少,bloom filter的体积会显著减小,因为bloom filter entry的生成是以row为单位.
2)Hbase中除了rowkey作为检索条件,还可以利用filter在rowkey,keyvalue,keyvalue的集合上进行过滤.在filter执行的早期阶段进行rowkey的比较,如果发现整个row不符合条件,能迅速跳过大量keyvalue,减少filter比对的次数.
2.2 opentsdb的宽列存储的二次compact
宽列存储的硬盘空间节省非常有限,因为keyvalue的数量受column qualifier数量影响.因此可以在宽列存储的基础上进行二次compact,将同一个row的多个column qualifier存储为一个column qualifier.
其keyvalue物理存储格式(略去column family和version部分)为
进过二次compact的时序数据,在存储体积上也显著减小.配合其他压缩算法,可以极大的节省存储空间,提高访问效率.
Opentsdb在添加数据点的时候,把需要compact的row放到一个队列中,然后定时compact.
TSDB的addPointInternal方法中,调用scheduleForCompaction将row放入队列, CompactionQueue类中,启动Thrd这个线程来进行compact
但是有时候一个row已经被compact过了,这个row仍有可能插入数据,所以要对已经compact的row进行第二次compact,所以在scan的时候,仍然有可能进行compact.
ScannerCB类中,每次scan完成仍然调用compact方法进行数据compaction
下图表示一个已经compact的row,插入了新的数据后,又一次进行了compact
3 opents中的tree
Opents中的监控指标都是metric,每个metric都互相独立,带有tag,由用户自定义metric和tag,但是可以通过自定义规则,将metric,tag分解为树的形式进行结构化展现.
比如有上面的metric和tag,可以通过规则(提取tag value,正则表达式分解metric等),变换为如下的tree
先按照数据中心分级,然后按主机,然后按监控类型