nutch 搜索site dedup
这个版本发现有个大大的bug,就是搜索时同一页面出现重复,不同页面也出现重复。即使有check dedup功能,也不起作用。
后来把代码修改一个才行,被搞晕。。。
其实关键代码就在于NutchBean.search(query)中。以下来分析一下。
public Hits search(Query query) throws IOException {
if (query.getParams().getMaxHitsPerDup() <= 0) // disable dup checking
return searchBean.search(query);
final float rawHitsFactor = this.conf.getFloat("searcher.hostgrouping.rawhits.factor", 2.0f);
int numHitsRaw = (int)(query.getParams().getNumHits() * rawHitsFactor);
if (LOG.isInfoEnabled()) {
LOG.info("searching for "+numHitsRaw+" raw hits");
}
Hits hits = searchBean.search(query);
final long total = hits.getTotal();
final Map<String, DupHits> dupToHits = new HashMap<String, DupHits>();
final List<Hit> resultList = new ArrayList<Hit>();
final Set<Hit> seen = new HashSet<Hit>();
final List<String> excludedValues = new ArrayList<String>();
boolean totalIsExact = true;
int optimizeNum = 0;
for (int rawHitNum = 0; rawHitNum < hits.getLength(); rawHitNum++) {
// get the next raw hit
if (rawHitNum == (hits.getLength() - 1) && (optimizeNum < MAX_OPTIMIZE_LOOPS)) {
// increment the loop
optimizeNum++;
// optimize query by prohibiting more matches on some excluded values
final Query optQuery = (Query)query.clone();
for (int i = 0; i < excludedValues.size(); i++) {
if (i == MAX_PROHIBITED_TERMS)
break;
optQuery.addProhibitedTerm(excludedValues.get(i),
query.getParams().getDedupField());
}
numHitsRaw = (int)(numHitsRaw * rawHitsFactor);
if (LOG.isInfoEnabled()) {
LOG.info("re-searching for "+numHitsRaw+" raw hits, query: "+optQuery);
}
hits = searchBean.search(optQuery);
if (LOG.isInfoEnabled()) {
LOG.info("found "+hits.getTotal()+" raw hits");
}
rawHitNum = -1;
continue;
}
final Hit hit = hits.getHit(rawHitNum);
if (seen.contains(hit))
continue;
seen.add(hit);
// get dup hits for its value
final String value = hit.getDedupValue();
DupHits dupHits = dupToHits.get(value);
if (dupHits == null)
dupToHits.put(value, dupHits = new DupHits());
// does this hit exceed maxHitsPerDup?
if (dupHits.size() == query.getParams().getMaxHitsPerDup()) { // yes -- ignore the hit
if (!dupHits.maxSizeExceeded) {
// mark prior hits with moreFromDupExcluded
for (int i = 0; i < dupHits.size(); i++) {
dupHits.get(i).setMoreFromDupExcluded(true);
}
dupHits.maxSizeExceeded = true;
excludedValues.add(value); // exclude dup
}
totalIsExact = false;
} else { // no -- collect the hit
resultList.add(hit);
dupHits.add(hit);
// are we done?
// we need to find one more than asked for, so that we can tell if
// there are more hits to be shown
if (resultList.size() > query.getParams().getNumHits())
break;
}
}
final Hits results =
new Hits(total,
resultList.toArray(new Hit[resultList.size()]));
results.setTotalIsExact(totalIsExact);
return results;
}
一。概念
hitsPerPage:相当count of a page
hitsPerSite:that is how many elements in a site per whole searches by same keyword
totalIsExact:如果没有site dup,那么就是true
numHits:就是期望的topn
seen:dedulicated set
二。流程
首先外部有个大循环,根据length()进行;内㠌一个loop,表明如果是有dup site便进行扩展搜索。
其实
numHitsRaw
没用到,可以说是多余的。当
excludedValues
为空时,这样会产生dead loop。
maxSizeExceeded
是为了标记一次整站搜索时同一site的是否处理过,当然前提 是达到hitspersite.
最后,利用
getNumHits
判断是否达到停止范围,应该说是使用8/2原则来显示下一页了。
觉得自从cutting放开lucene系列产品后,都有些不尽人意的地方。比如就这个问题。其实这版本还在其它jsp中问题等 ,可以说是测试根本不到位 呀,只是简单的替换下libs,改改人家提出的bugs就算upgrade,而最后 的测试也没把关一下,唉。。谁叫你开源呢?话又说回来,如果不开源又有多少技术不扩散,多少人失业呢?矛盾!
=============================
上传几张google中类似效果的图片;baidu现在没做了。记得以前两个都有搞similarity功能,现在只看到gg在搜索最后才显示 。

其实这里的功能相当上图中的最后一行功能。

这就是similarity 功能了,与site相当,只是在最后显示而已。



无意中发现bing的搜索有这样的結果:每页只有一个url。。。
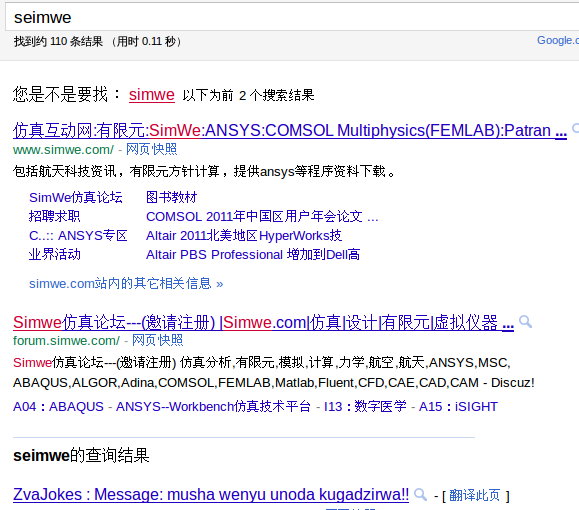
其实这个site功能的搜索总数是不固定的,就像上图一样,每次搜索結果都不一样,所以gg也是不同的页数显示数量不一样。但在nutch中,是故意将total先保存下来,最后和reset,就显得总数保持不变,其实这样做是不对的。应该向gg学习!