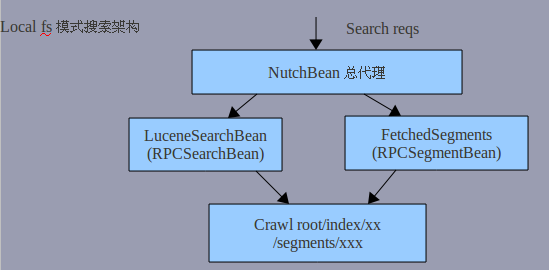
nutch搜索架构关键类
在整个crawl->recrawl后,其实作为搜索的文件夹只有两个:
* index(indexes) :提供搜索,和获取details信息(其实它也是通过 lucene doc fields来得到)。如title,url,last-modified,cache等等。
* segments : 提供summary即页面的描述,也就 是parse_text和cached(快照,content)
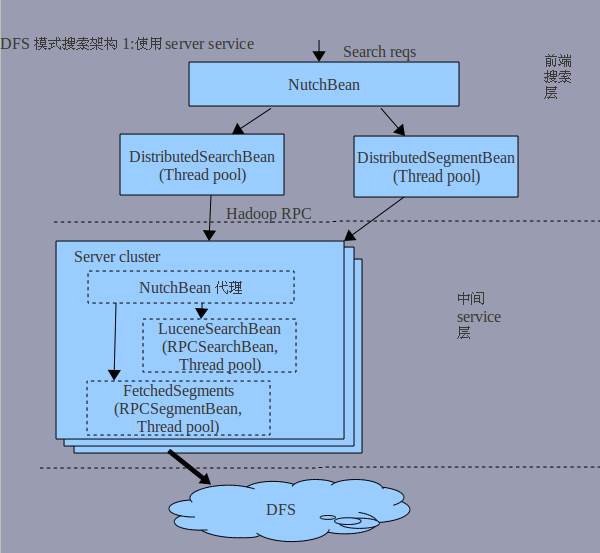
在类DistributedSearch中,是整个nutch提供RPC service的入口,其中有几个subclasses:
1.Server
此类是作为search 和summary的RPC service。如果启动它,将在server端先启动NutchBean作为代理。由于在server端search.dir property肯定配置为直接指定path的形式(因为search-servers.txt只在client端配置),所以经由它再转发到相应的RPCSearchBean(LuceneSearchBean)和RPCSegmentBean(FetchedSegments)来提供服务。
综上,它是提供以下要说的二个服务,只不过好处是不用单独启动one group threads。
2.IndexServer
专门供search的RPC service
3.SegmentServer
专门供summary的RPC service
以下是结合上述给出的流程图:
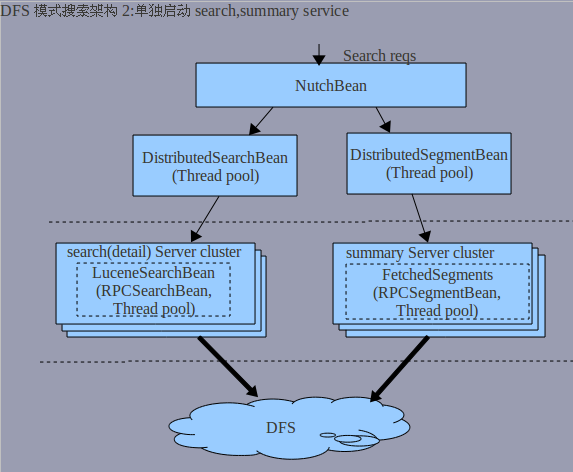
其实上图中的search,summary cluster可以组合在一起,但这样感觉回退到server service的局面了。
其中RPC调用参见 结合nutch解説hadoop的RPC
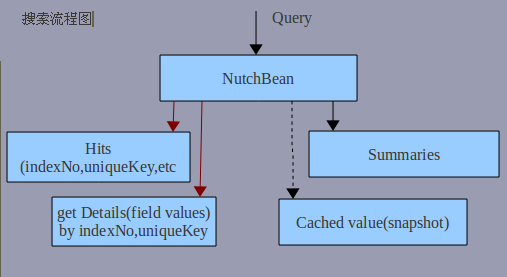
note:
* 红色部分个人认为是可以合并 ,因为它们读取的是同样的doc info;但不知道作者为什么将它分开来处理,特别是在分布式环境下,这样将造成更大的通信开销;
* 虚线部分表明这是原始的内容,即快照功能。
结合上述,这就是为什么我在 增量更新 时如果使用分布式搜索 不建议合并索引或合并到同一segment的原因了。
但是,这也是有前提 的,就是你的各台server应该单独处理自己的份内事。比如作为search server的,每台server应该只加载相应的index(或若干份索引 );作为segment server的,同样道理只负责自身的segment(或若干segs)
关键问题:
如果多个segs存在于一个server时,請求是怎样传递到该台server的?
对于这种情况,在开始时根据某个给定的seg name定位到相关的server,然后该server再根据相应的seg name定位到相应 的FetchedSegment.Segment。最后 此segment便利用MapFile来定位数据了。
同样道理,在搜索时,如果一个server上没有使用merge job来合并索引 ,即是说会有多份indexes,那么在搜索后根据uniqueKey来获取doc info时过程是怎样呢?
开始会利用indexNo来定位某个server,然后再利用之前search(Query)結果中的uniqueKey来定位某个doc。
刚开始时我也有点疑惑,因为如果多份索引来搜索时,很有可能有相同的doc id,为什么只根据一个uniqueKey(doc id)便可以知道是某个doc呢?其实只要番一下相关源码,看到如果使用indexes来搜索时,nutch处理使用了MultiReader,即合并 后的索引 doc id将累加各份索引 的max doc id,即是说合并后的逻辑索引是一个完整的索引 了,即doc id是唯一的。这样要后续的搜索只要给定uniqueKey但知道到哪份index(严格来说是reader)下搜索了。