简单DAG生成算法的一个性质
“简单”嘛说明肯定有更麻烦、效果可能更好的办法。这里提到的算法就是这样。
龙书第二版363页习题6.1.2有点意思。题目如下:
(c)原本在书上就是这么写的……很明显括号没配对是吧 = =
勘误表里没提到这项。莫非是国内的影印版的问题?我无法确认。正确的代码应该是:
a + a + (a + a + a + (a + a + a + a))
这样才对)
如何从表达式的源码生成DAG(Directed Acyclic Graph,有向无环图)呢?龙书在前面给出了一个算法:在解析源码并生成语法树的算法的基础上,如果在创建新的节点前先检查是否已存在相同的节点,若存在则返回已有节点,否则返回新建的节点。
假设DAG的节点是<op,left,right>形式的三元组,其中op是表示运算符的枚举类型的值,left和right是表示子节点的引用。那么在检查是否已存在相同的节点时,只需要分别检查op、left和right是否相同即可。
但是这个简单的算法很明显不保证生成最优(节点数最少)的DAG。以习题6.1.2中的a)和b)为例:
a)
AST:

DAG:
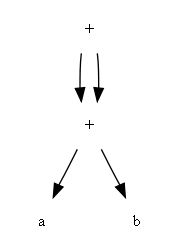
这个DAG的叶节点有2个,内部节点有2个。
对应到三地址代码,是:
b)
AST:

DAG:
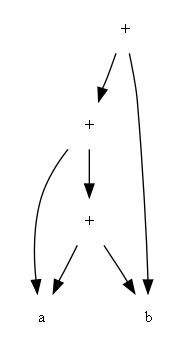
这个DAG的叶节点也是两个,但内部节点却有3个,比a)的多一个。
对应到三地址代码,则是:
问题是什么呢?习题里a)和b)的源码所代表的表达式的运算结果显然应该是一样的,但由于对应的AST的形状不同,导致生成的DAG也有所不同。
如果尝试对AST做等价变形然后再生成DAG,或许是可以选择出较优的版本,不过是否值得为了这个优化而使编译器变得复杂就是另一个问题了。对AST做了等价变形后,要比以某节点N1为根的子树与另一以N2为根的子树是否相同,就得专门写一个TreeComparer了。前面的简单算法是在生成节点的时候就做了比较,等于是做过了自底而上的比较,实现起来很简单。
===================================================================================
要写个简单的解析器来生成上面的图十分简单。
首先定义语言的语法,尽量定义得简单些:
或者化简掉左递归后以EBNF表示:
其中ID为单字符的英文字母。
那么可以简单的实现解析器如下:
使用方法是直接运行该程序,然后在一行上输入一个符合前面语法规则的表达式,或者是在运行该程序的时候提供一个参数作为这个表达式。运行程序后,如果解析正常结束,那么会在标准输出上先后输出对应AST和DAG的DOT代码。
输出的DOT代码通过 Graphviz的dot程序就能生成图片。
例如说运行程序后输入a + b + (a + b)回车,会看到:
和
用dot把它们分别转换成图片即可。假如对应DAG的这段DOT代码被保存到名为dag.dot文件里,则:
就可以得到名为dag.png的图片,跟本文顶上的第二张图是一样的。
Expression及其派生类是用来表示解析源码后得到的AST或DAG的节点。注意Expression类上的Add和Id这两个静态工厂方法中关于检查节点是否已经存在,并尽量返回已有节点的做法:这就是前面提到的简单DAG生成算法在上面这大堆代码里的实现。检测节点的相等性的代码主要是在BinaryExpression和IdExpression里实现的。
Cache本来我是想用HashSet的,不过.NET标准库里的HashSet在这里不好用:虽然很容易知道容器里是否已存在相同的节点,却没办法把那个节点迅速拿出来;要是最终还是得线性遍历的话,那还不如用线性容器。所以最后还是用了List。
Scanner和Parser分别最低限度的实现了词法分析器和递归下降语法分析器。只允许单字符变量名也就是为了方便Scanner的实现。不过这部分其实用ANTLR来生成更方便,也一样可以接上后面的程序运行。
DotGenerator用于根据AST或DAG生成DOT图,实现得有点乱。主要是原本为了保证生成的DOT代码中节点的顺序,而采用了广度优先的遍历顺序;可是后来用于强制指定顺序的代码反而带来了一些问题,所以注释掉了(第308行到第314行)。这样一来用两个Queue来记录着前一行与当前行的节点就不一定有必要了。不过懒得改,就这样吧……
编辑:嗯不行……前面的代码不改还是有问题。本来我是觉得DAG因为没有环所以只要记住“上一层”的节点就足以判断前面是否已经见过该节点,但熬夜写代码看来质量果然是不高啊,这想法是错的。还是乖乖的用一个HashSet来记着前面见到过的节点然后用深度优先遍历算了,免得麻烦。修改后的DotGenerator类如下:
对应习题里c)的DAG应该是:

上面的代码做出来的效果还有待改善就是了。对 a + b + (b + a) 这样的表达式,生成的DAG会是:

右侧中间的那个+下面的左节点与右节点的顺序反掉了。其实仔细留心的话,前面对习题的b)给出的DAG也有一个节点的左右关系是反了的。
要调整这个细节挺麻烦的,我还没想好怎么实现比较干净。不过暂时就这么凑合看看好了 = =
===================================================================================
顺带提一下.NET 3.5里的LINQ Expression Tree和DLR里的LINQ Expression Tree v2。
在 LINQ与DLR的Expression tree(1):简介LINQ与Expression tree一帖的 Expression tree与lambda表达式一节里,我简单的提到过“Expression Tree表示的是AST”这样的概念。当时只是为了说明方便,其实并不准确。
用那帖的例子来说,下面的lambda表达式:
在那帖里我给出了这样的AST图:
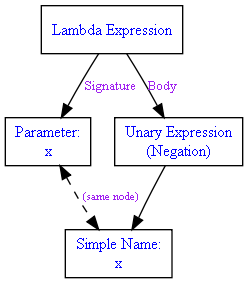
也说明了图中虚线连接的两个节点实际上是一个节点。
但我们都知道,树这种数据结构的重要性质就是它的每个节点都只有一个父节点(根节点除外)。上述lambda表达式对应的Expression Tree中的节点情况实际上应该这样画:

这样就可以看得比较清楚了。实际上这个图并不是一棵树,而是一个DAG。Expression Tree实际表示的也应该说是DAG才准确。不过用AST的概念来解释它还是比DAG方便一些就是了……
===================================================================================
Hmm,用Sun的javac 1.6.x和.NET Framework 3.5 SP1的csc编译习题里的那3个表达式,得到的结果都是没有用DAG做过优化的,即便给csc设置/o开关(近来Sun的javac会忽略-O,所以也不用设了)。因为对运行时里的JIT的高度优化能力有信心,这些编译器都不再做多少优化了,直接留给拥有更多信息因而能做出更多优化的JIT来解决问题。
对现在流行的托管高级语言来说,有一个问题是:语言规范中规定了很多细节,以致许多东西无法被优化,否则就保证不了语义。
例如,如果在C#里,用户对自己的一个类型重载了加法运算符,然后里面有副作用;则如果优化后减少了加法运算符调用的次数,这个行为就能带来用户可见的影响。因而不可以随便优化这样的运算。改变求值顺序也是不允许的,像Java和C#都规定要遵循从左向右的求值顺序,实现时必须保证其语义的正确性。
微软的csc应该通过分析定义-使用关系做了至少一趟优化,因为这段代码:
让csc编译过后就只剩下这么多了:
很明显如果继续用定义-使用关系来优化的话,整个Main()方法应该变成空的才对。
C#不允许用户对内建类型的运算符做重载,所以还好,至少System.Int32的加法运算符能保证没有可见的副作用,所以可以优化。不过试想一个这样的类:
然后要是foo是Foo的一个实例,我要是写:
要是被优化了的话,Console.WriteLine(_value)就只会发生一次,这就糟糕了。
GCC 4.3.0在编译这几个表达式的时候,使用-O2,对代码:
其中与i、j和k的初始化相关的表达式编译得到:
优化得相当彻底。此时i和j都由edx表示。
事实上不加上输出语句的话,整个foo()就没了 = =
================================================
LLVM通过 -reassociate和 -instcombine可以对这里的问题做优化,但有种歪打正着的感觉。
例如说对:
LLVM可以通过reassociate变成:
然后通过instcombine变成:
然后在后面lower到底层IR时再把* 3转换为机器相关的更高效形式,例如lea。
original IR
after reassociate:
after instcombine:
-reassociate的相关部分是Reassociate::OptimizeAdd()做的。
http://www.opensource.apple.com/source/clang/clang-137/src/lib/Transforms/Scalar/Reassociate.cpp
================================================
拿HotSpot 22.0也试了试上面的习题b)。发现HotSpot Server Compiler也没对这种情况优化嘛,哈哈

还是有3个加在这里,而不是理想的2个加
龙书第二版363页习题6.1.2有点意思。题目如下:
Compilers - Principles, Techniques, & Tools, Second Edition 写道
Exercise 6.1.2: Construct the DAG and identify the value numbers for the subexpressions of the following expressions, assuming + associates from the left.
a) a + b + (a + b)
b) a + b + a + b
c) a + a + ((a + a + a + (a + a + a + a))
a) a + b + (a + b)
b) a + b + a + b
c) a + a + ((a + a + a + (a + a + a + a))
(c)原本在书上就是这么写的……很明显括号没配对是吧 = =
勘误表里没提到这项。莫非是国内的影印版的问题?我无法确认。正确的代码应该是:
a + a + (a + a + a + (a + a + a + a))
这样才对)
如何从表达式的源码生成DAG(Directed Acyclic Graph,有向无环图)呢?龙书在前面给出了一个算法:在解析源码并生成语法树的算法的基础上,如果在创建新的节点前先检查是否已存在相同的节点,若存在则返回已有节点,否则返回新建的节点。
假设DAG的节点是<op,left,right>形式的三元组,其中op是表示运算符的枚举类型的值,left和right是表示子节点的引用。那么在检查是否已存在相同的节点时,只需要分别检查op、left和right是否相同即可。
但是这个简单的算法很明显不保证生成最优(节点数最少)的DAG。以习题6.1.2中的a)和b)为例:
a)
AST:
DAG:
这个DAG的叶节点有2个,内部节点有2个。
对应到三地址代码,是:
t1 = a + b t2 = t1 + t1
b)
AST:
DAG:
这个DAG的叶节点也是两个,但内部节点却有3个,比a)的多一个。
对应到三地址代码,则是:
t1 = a + b t2 = t1 + a t3 = t2 + b
问题是什么呢?习题里a)和b)的源码所代表的表达式的运算结果显然应该是一样的,但由于对应的AST的形状不同,导致生成的DAG也有所不同。
如果尝试对AST做等价变形然后再生成DAG,或许是可以选择出较优的版本,不过是否值得为了这个优化而使编译器变得复杂就是另一个问题了。对AST做了等价变形后,要比以某节点N1为根的子树与另一以N2为根的子树是否相同,就得专门写一个TreeComparer了。前面的简单算法是在生成节点的时候就做了比较,等于是做过了自底而上的比较,实现起来很简单。
===================================================================================
要写个简单的解析器来生成上面的图十分简单。
首先定义语言的语法,尽量定义得简单些:
E ->
E '+' ID
| ID
| '(' E ')'
或者化简掉左递归后以EBNF表示:
E ->
ID ( '+' ID )*
| '(' E ')'
其中ID为单字符的英文字母。
那么可以简单的实现解析器如下:
using System;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Linq;
public enum NodeKind {
Add,
Id
}
public abstract class Expression : IEquatable<Expression> {
// DAG node cache
static List<Expression> _cache;
// lazily initialize the cache for creating DAG nodes
protected static List<Expression> Cache {
get {
if ( null == _cache ) {
_cache = new List<Expression>( );
}
return _cache;
}
}
public virtual NodeKind NodeKind {
get { throw new NotSupportedException( ); }
}
// Create a BinaryExpression node representing an add operation
public static BinaryExpression Add( Expression left, Expression right, bool useCache ) {
var tempExpr = new BinaryExpression( left, right );
if ( useCache ) {
return LookupCache( tempExpr ) as BinaryExpression;
} else {
return tempExpr;
}
}
// Create an IdExpression representing an ID access
public static IdExpression Id( char id, bool useCache ) {
var tempExpr = new IdExpression( id );
if ( useCache ) {
return LookupCache( tempExpr ) as IdExpression;
} else {
return tempExpr;
}
}
static Expression LookupCache( Expression expr ) {
var cachedExpr = Cache.FirstOrDefault( e => e.Equals( expr ) );
if ( null == cachedExpr ) {
Cache.Add( expr );
cachedExpr = expr;
}
return cachedExpr;
}
#region IEquatable<Expression> members and related methods
public override bool Equals( object other ) {
if ( !( other is Expression ) ) return false;
return Equals( other as Expression );
}
public override int GetHashCode( ) {
return GetHashCodeCore( );
}
public abstract bool Equals( Expression other );
protected abstract int GetHashCodeCore( );
#endregion
}
public class BinaryExpression : Expression {
Expression _left;
Expression _right;
public BinaryExpression( Expression left, Expression right ) {
_left = left;
_right = right;
}
public override NodeKind NodeKind {
get { return NodeKind.Add; }
}
public Expression Left {
get { return _left; }
}
public Expression Right {
get { return _right; }
}
public override bool Equals( Expression other ) {
if ( ! ( other is BinaryExpression ) ) return false;
var otherExpr = other as BinaryExpression;
return otherExpr.Left == _left
&& otherExpr.Right == _right;
}
protected override int GetHashCodeCore( ) {
return _left.GetHashCode( ) * 37 + _right.GetHashCode( ) + 17;
}
public override string ToString( ) {
return string.Format( "(+ {0} {1})", _left.ToString( ), _right.ToString( ) );
}
}
public class IdExpression : Expression {
char _id;
public IdExpression( char id ) {
_id = id;
}
public override NodeKind NodeKind {
get { return NodeKind.Id; }
}
public string IdString {
get { return _id.ToString( ); }
}
public override bool Equals( Expression other ) {
if ( ! ( other is IdExpression ) ) return false;
return _id == ( other as IdExpression )._id;
}
protected override int GetHashCodeCore( ) {
return _id.GetHashCode( );
}
public override string ToString( ) {
return IdString;
}
}
public class SyntaxException : Exception {
public SyntaxException( ) {
}
public SyntaxException( string message )
: base( message ) {
}
}
public class Scanner : IEnumerable, IEnumerable<int> {
public const int EOS = -1;
string _input;
public Scanner( string input ) {
_input = input;
}
public IEnumerator GetEnumerator( ) {
return ( this as IEnumerable<int> ).GetEnumerator( );
}
IEnumerator<int> IEnumerable<int>.GetEnumerator( ) {
return EnumerateChars( ).GetEnumerator( );
}
static readonly int[ ] _punctuations = new int[ ] {
'+', '(', ')'
};
IEnumerable<int> EnumerateChars( ) {
var reader = new StringReader( _input );
int intChar;
while ( 0 < ( intChar = reader.Read( ) ) ) {
var c = Convert.ToChar( intChar );
if ( Char.IsWhiteSpace( c ) ) continue;
if ( _punctuations.Contains( intChar ) || Char.IsLetter( c ) ) {
yield return intChar;
} else {
throw new SyntaxException(
string.Format( "Invalid character: {0}", c.ToString( ) ) );
}
}
yield return EOS;
}
}
public class Parser {
Scanner _scanner;
IEnumerator<int> _input;
public Parser( Scanner scanner ) {
_scanner = scanner;
}
public Expression ParseToDag( ) {
_input = ( _scanner as IEnumerable<int> ).GetEnumerator( );
return Parse( true );
}
public Expression ParseToAst( ) {
_input = ( _scanner as IEnumerable<int> ).GetEnumerator( );
return Parse( false );
}
Expression Parse( bool useCache ) {
_input.MoveNext( );
var expr = ParseExpression( useCache );
Match( Scanner.EOS );
_input = null;
return expr;
}
Expression ParseExpression( bool useCache ) {
Expression expr = null;
// E -> ID | '(' E ')'
switch ( _input.Current ) {
case '(':
Match( '(' );
expr = ParseExpression( useCache );
Match( ')' );
break;
case Scanner.EOS:
throw new SyntaxException( "Unexpected end of string" );
default:
expr = Expression.Id( Convert.ToChar( _input.Current ), useCache );
_input.MoveNext( );
break;
}
// ( '+' ( ID | '(' E ')' ) )*
while ( _input.Current == '+' ) {
Match( '+' );
Expression right = null;
switch ( _input.Current ) {
case '(':
Match( '(' );
right = ParseExpression( useCache );
Match( ')' );
break;
case Scanner.EOS:
throw new SyntaxException( "Unexpected end of string" );
default:
right = Expression.Id( Convert.ToChar( _input.Current ), useCache );
_input.MoveNext( );
break;
}
expr = Expression.Add( expr, right, useCache );
}
return expr;
}
void Match( int charCodeToMatch ) {
if ( _input.Current == charCodeToMatch ) {
_input.MoveNext( );
} else {
throw new SyntaxException(
string.Format(
"Expecting {0}, but found {1}",
CharCodeToString( charCodeToMatch ),
CharCodeToString( _input.Current ) ) );
}
}
string CharCodeToString( int charCode ) {
return 0 < charCode ? Convert.ToChar( charCode ).ToString( ) : "End-Of-String";
}
}
class DotGenerator {
Queue<Expression> _lastRank;
Queue<Expression> _thisRank;
TextWriter _writer;
IEnumerator<string> _nameMaker;
Dictionary<Expression, string> _nameMap;
public DotGenerator( ) {
_lastRank = new Queue<Expression>( );
_thisRank = new Queue<Expression>( );
}
public string Generate( Expression root ) {
_lastRank.Enqueue( root );
_nameMap = new Dictionary<Expression, string>( IdentityComparer<Expression>.Instance );
_nameMaker = GetNameMaker( ).GetEnumerator( );
_writer = new StringWriter( );
_writer.WriteLine( "digraph {" );
_writer.WriteLine( " node [fontsize=12, font=Courier, shape=plaintext]" );
GenerateCore( );
_writer.WriteLine( "}" );
var dot = _writer.ToString( );
_nameMap.Clear( );
_nameMap = null;
_nameMaker = null;
_writer = null;
return dot;
}
// breadth-first traverse
void GenerateCore( ) {
while ( 0 < _lastRank.Count ) {
/*if ( 1 < _lastRank.Count ) {
string[ ] rank = _lastRank.Select( e => _nameMap[ e ] ).ToArray( );
_writer.WriteLine( " {0} [ordering=out, style=invis]",
string.Join( " -> ", rank ) );
_writer.WriteLine( " {{rank=same; {0} }}",
string.Join( " ", rank ) );
}*/
while ( 0 < _lastRank.Count ) {
var expr = _lastRank.Dequeue( );
DeclareNode( expr );
switch ( expr.NodeKind ) {
case NodeKind.Add:
var addExpr = expr as BinaryExpression;
var left = addExpr.Left;
var right = addExpr.Right;
if ( !_thisRank.Contains( left, IdentityComparer<Expression>.Instance ) ) {
DeclareNode( addExpr.Left );
_thisRank.Enqueue( left );
}
if ( !_thisRank.Contains( right, IdentityComparer<Expression>.Instance ) ) {
DeclareNode( addExpr.Right );
_thisRank.Enqueue( right );
}
_writer.WriteLine( " {0} -> {1}",
_nameMap[ expr ], _nameMap[ left ] );
_writer.WriteLine( " {0} -> {1}",
_nameMap[ expr ], _nameMap[ right ] );
break;
case NodeKind.Id:
// DO NOTHING
break;
}
}
// swap the two queues
var tempQueue = _lastRank;
_lastRank = _thisRank;
_thisRank = tempQueue;
}
}
void DeclareNode( Expression expr ) {
if ( !_nameMap.ContainsKey( expr ) ) {
_nameMaker.MoveNext( );
var name = _nameMaker.Current;
_nameMap.Add( expr, name );
switch ( expr.NodeKind ) {
case NodeKind.Add:
_writer.WriteLine( " {0} [label=\"+\"]", name );
break;
case NodeKind.Id:
var idExpr = expr as IdExpression;
_writer.WriteLine( " {0} [label=\"{1}\"]", name, idExpr.IdString );
break;
}
}
}
IEnumerable<string> GetNameMaker( ) {
for ( var count = 0; ; ++count ) {
yield return string.Format( "node_{0}", count.ToString( ) );
}
}
class IdentityComparer<T> : EqualityComparer<T> {
static IdentityComparer<T> _instance;
static IdentityComparer( ) {
_instance = new IdentityComparer<T>( );
}
public static IdentityComparer<T> Instance {
get { return _instance; }
}
public override bool Equals( T first, T second ) {
return object.ReferenceEquals( first, second );
}
public override int GetHashCode( T obj ) {
return obj.GetHashCode( );
}
}
}
static class Program {
static void Main( string[ ] args ) {
string input = null;
switch ( args.Length ) {
case 0:
Console.WriteLine( "Enter an expression on a line:" );
Console.WriteLine( "(or give the expression as " +
"the first argument in command prompt)" );
input = Console.ReadLine( );
break;
default:
input = args[ 0 ];
break;
}
var scanner = new Scanner( input );
var parser = new Parser( scanner );
var dotGen = new DotGenerator( );
var ast = parser.ParseToAst( );
var astDot = dotGen.Generate( ast );
Console.WriteLine( "// DOT script for AST:" );
Console.WriteLine( astDot );
var dag = parser.ParseToDag( );
var dagDot = dotGen.Generate( dag );
Console.WriteLine( "// DOT script for DAG:" );
Console.WriteLine( dagDot );
}
}
使用方法是直接运行该程序,然后在一行上输入一个符合前面语法规则的表达式,或者是在运行该程序的时候提供一个参数作为这个表达式。运行程序后,如果解析正常结束,那么会在标准输出上先后输出对应AST和DAG的DOT代码。
输出的DOT代码通过 Graphviz的dot程序就能生成图片。
例如说运行程序后输入a + b + (a + b)回车,会看到:
// DOT script for AST:
digraph {
node [fontsize=12, font=Courier, shape=plaintext]
node_0 [label="+"]
node_1 [label="+"]
node_2 [label="+"]
node_0 -> node_1
node_0 -> node_2
node_3 [label="a"]
node_4 [label="b"]
node_1 -> node_3
node_1 -> node_4
node_5 [label="a"]
node_6 [label="b"]
node_2 -> node_5
node_2 -> node_6
}
和
// DOT script for DAG:
digraph {
node [fontsize=12, font=Courier, shape=plaintext]
node_0 [label="+"]
node_1 [label="+"]
node_0 -> node_1
node_0 -> node_1
node_2 [label="a"]
node_3 [label="b"]
node_1 -> node_2
node_1 -> node_3
}
用dot把它们分别转换成图片即可。假如对应DAG的这段DOT代码被保存到名为dag.dot文件里,则:
dot -Tpng dag.dot -o dag.png
就可以得到名为dag.png的图片,跟本文顶上的第二张图是一样的。
Expression及其派生类是用来表示解析源码后得到的AST或DAG的节点。注意Expression类上的Add和Id这两个静态工厂方法中关于检查节点是否已经存在,并尽量返回已有节点的做法:这就是前面提到的简单DAG生成算法在上面这大堆代码里的实现。检测节点的相等性的代码主要是在BinaryExpression和IdExpression里实现的。
Cache本来我是想用HashSet的,不过.NET标准库里的HashSet在这里不好用:虽然很容易知道容器里是否已存在相同的节点,却没办法把那个节点迅速拿出来;要是最终还是得线性遍历的话,那还不如用线性容器。所以最后还是用了List。
Scanner和Parser分别最低限度的实现了词法分析器和递归下降语法分析器。只允许单字符变量名也就是为了方便Scanner的实现。不过这部分其实用ANTLR来生成更方便,也一样可以接上后面的程序运行。
DotGenerator用于根据AST或DAG生成DOT图,实现得有点乱。主要是原本为了保证生成的DOT代码中节点的顺序,而采用了广度优先的遍历顺序;可是后来用于强制指定顺序的代码反而带来了一些问题,所以注释掉了(第308行到第314行)。这样一来用两个Queue来记录着前一行与当前行的节点就不一定有必要了。不过懒得改,就这样吧……
编辑:嗯不行……前面的代码不改还是有问题。本来我是觉得DAG因为没有环所以只要记住“上一层”的节点就足以判断前面是否已经见过该节点,但熬夜写代码看来质量果然是不高啊,这想法是错的。还是乖乖的用一个HashSet来记着前面见到过的节点然后用深度优先遍历算了,免得麻烦。修改后的DotGenerator类如下:
class DotGenerator {
HashSet<Expression> _seenNodes;
TextWriter _writer;
IEnumerator<string> _nameMaker;
Dictionary<Expression, string> _nameMap;
public DotGenerator( ) {
_seenNodes = new HashSet<Expression>(
IdentityComparer<Expression>.Instance );
_nameMap = new Dictionary<Expression, string>(
IdentityComparer<Expression>.Instance );
}
public string Generate( Expression root ) {
_nameMaker = GetNameMaker( ).GetEnumerator( );
_writer = new StringWriter( );
_writer.WriteLine( "digraph {" );
_writer.WriteLine( " node [fontsize=12, font=Courier, shape=plaintext]" );
GenerateCore( root );
_writer.WriteLine( "}" );
var dot = _writer.ToString( );
_seenNodes.Clear( );
_nameMap.Clear( );
_nameMaker = null;
_writer = null;
return dot;
}
// depth-first traverse
void GenerateCore( Expression expr ) {
DeclareNode( expr );
_seenNodes.Add( expr );
switch ( expr.NodeKind ) {
case NodeKind.Add:
var addExpr = expr as BinaryExpression;
var left = addExpr.Left;
var right = addExpr.Right;
if ( !_seenNodes.Contains( left ) ) {
GenerateCore( left );
}
if ( !_seenNodes.Contains( right ) ) {
GenerateCore( right );
}
_writer.WriteLine( " {0} -> {1}",
_nameMap[ expr ], _nameMap[ left ] );
_writer.WriteLine( " {0} -> {1}",
_nameMap[ expr ], _nameMap[ right ] );
break;
case NodeKind.Id:
// DO NOTHING
break;
}
}
void DeclareNode( Expression expr ) {
if ( !_nameMap.ContainsKey( expr ) ) {
_nameMaker.MoveNext( );
var name = _nameMaker.Current;
_nameMap.Add( expr, name );
switch ( expr.NodeKind ) {
case NodeKind.Add:
_writer.WriteLine( " {0} [label=\"+\"]", name );
break;
case NodeKind.Id:
var idExpr = expr as IdExpression;
_writer.WriteLine( " {0} [label=\"{1}\"]", name, idExpr.IdString );
break;
}
}
}
IEnumerable<string> GetNameMaker( ) {
for ( var count = 0; ; ++count ) {
yield return string.Format( "node_{0}", count.ToString( ) );
}
}
class IdentityComparer<T> : EqualityComparer<T> {
static IdentityComparer<T> _instance;
static IdentityComparer( ) {
_instance = new IdentityComparer<T>( );
}
public static IdentityComparer<T> Instance {
get { return _instance; }
}
public override bool Equals( T first, T second ) {
return object.ReferenceEquals( first, second );
}
public override int GetHashCode( T obj ) {
return obj.GetHashCode( );
}
}
}
对应习题里c)的DAG应该是:
上面的代码做出来的效果还有待改善就是了。对 a + b + (b + a) 这样的表达式,生成的DAG会是:
右侧中间的那个+下面的左节点与右节点的顺序反掉了。其实仔细留心的话,前面对习题的b)给出的DAG也有一个节点的左右关系是反了的。
要调整这个细节挺麻烦的,我还没想好怎么实现比较干净。不过暂时就这么凑合看看好了 = =
===================================================================================
顺带提一下.NET 3.5里的LINQ Expression Tree和DLR里的LINQ Expression Tree v2。
在 LINQ与DLR的Expression tree(1):简介LINQ与Expression tree一帖的 Expression tree与lambda表达式一节里,我简单的提到过“Expression Tree表示的是AST”这样的概念。当时只是为了说明方便,其实并不准确。
用那帖的例子来说,下面的lambda表达式:
x => -x
在那帖里我给出了这样的AST图:
也说明了图中虚线连接的两个节点实际上是一个节点。
但我们都知道,树这种数据结构的重要性质就是它的每个节点都只有一个父节点(根节点除外)。上述lambda表达式对应的Expression Tree中的节点情况实际上应该这样画:
这样就可以看得比较清楚了。实际上这个图并不是一棵树,而是一个DAG。Expression Tree实际表示的也应该说是DAG才准确。不过用AST的概念来解释它还是比DAG方便一些就是了……
===================================================================================
Hmm,用Sun的javac 1.6.x和.NET Framework 3.5 SP1的csc编译习题里的那3个表达式,得到的结果都是没有用DAG做过优化的,即便给csc设置/o开关(近来Sun的javac会忽略-O,所以也不用设了)。因为对运行时里的JIT的高度优化能力有信心,这些编译器都不再做多少优化了,直接留给拥有更多信息因而能做出更多优化的JIT来解决问题。
对现在流行的托管高级语言来说,有一个问题是:语言规范中规定了很多细节,以致许多东西无法被优化,否则就保证不了语义。
例如,如果在C#里,用户对自己的一个类型重载了加法运算符,然后里面有副作用;则如果优化后减少了加法运算符调用的次数,这个行为就能带来用户可见的影响。因而不可以随便优化这样的运算。改变求值顺序也是不允许的,像Java和C#都规定要遵循从左向右的求值顺序,实现时必须保证其语义的正确性。
微软的csc应该通过分析定义-使用关系做了至少一趟优化,因为这段代码:
static class TestDAG {
static void Main(string[] args) {
int a = 0x001001;
int b = 0x010002;
int i = a + b + (a + b);
int j = a + b + a + b;
int k = a + a + (a + a + a + (a + a + a + a));
}
}
让csc编译过后就只剩下这么多了:
static class TestDAG {
static void Main(string[] args) {
int a = 0x001001;
int b = 0x010002;
}
}
很明显如果继续用定义-使用关系来优化的话,整个Main()方法应该变成空的才对。
C#不允许用户对内建类型的运算符做重载,所以还好,至少System.Int32的加法运算符能保证没有可见的副作用,所以可以优化。不过试想一个这样的类:
public class Foo {
int _value;
public int Value {
get {
Console.WriteLine( _value );
return _value;
}
set { _value = value; }
}
}
然后要是foo是Foo的一个实例,我要是写:
1 + foo.Value + (1 + foo.Value)
要是被优化了的话,Console.WriteLine(_value)就只会发生一次,这就糟糕了。
GCC 4.3.0在编译这几个表达式的时候,使用-O2,对代码:
void foo(int a, int b) {
int i = a + b + (a + b);
int j = a + b + a + b;
int k = a + a + (a + a + a + (a + a + a + a));
printf("%d, %d, %d, %d, %d\n", a, b, i, j, k);
}
其中与i、j和k的初始化相关的表达式编译得到:
mov ecx,dword ptr ss:[ebp+8] ; ecx = a mov ebx,dword ptr ss:[ebp+C] ; ebx = b lea edx,dword ptr ds:[ebx+ecx] ; edx = a + b shl edx,1 ; edx = 2 * edx lea eax,dword ptr ds:[ecx+ecx*2] ; eax = a + 2 * a lea eax,dword ptr ds:[eax+eax*2] ; eax = eax + 2 * eax
优化得相当彻底。此时i和j都由edx表示。
事实上不加上输出语句的话,整个foo()就没了 = =
================================================
LLVM通过 -reassociate和 -instcombine可以对这里的问题做优化,但有种歪打正着的感觉。
例如说对:
a + b + c + a + b + c + a + b + c
LLVM可以通过reassociate变成:
tmp1 = a * 3 tmp2 = b * 3 tmp3 = c * 3 tmp4 = tmp1 + tmp2 tmp5 = tmp4 + tmp3
然后通过instcombine变成:
tmp1 = a + b tmp2 = tmp1 + c tmp3 = tmp2 * 3
然后在后面lower到底层IR时再把* 3转换为机器相关的更高效形式,例如lea。
original IR
; Function Attrs: nounwind ssp uwtable
define void @foo(i32 %a, i32 %b, i32 %c) #0 {
%1 = add i32 %a, %b
%2 = add i32 %1, %c
%3 = add i32 %2, %a
%4 = add i32 %3, %b
%5 = add i32 %4, %c
%6 = add i32 %5, %a
%7 = add i32 %6, %b
%result = add i32 %7, %c
%8 = tail call i32 (i8*, ...)* @printf(i8* getelementptr inbounds ([20 x i8]* @.str, i64 0, i64 0), i32 %a, i32 %b, i32 %result, i32 %result, i32 %result) #2
ret void
}
after reassociate:
; Function Attrs: nounwind ssp uwtable
define void @foo(i32 %a, i32 %b, i32 %c) #0 {
%factor = mul i32 %c, 3
%factor1 = mul i32 %b, 3
%factor2 = mul i32 %a, 3
%1 = add i32 %factor1, %factor
%result = add i32 %1, %factor2
%2 = tail call i32 (i8*, ...)* @printf(i8* getelementptr inbounds ([20 x i8]* @.str, i64 0, i64 0), i32 %a, i32 %b, i32 %result, i32 %result, i32 %result) #2
ret void
}
after instcombine:
; Function Attrs: nounwind ssp uwtable
define void @foo(i32 %a, i32 %b, i32 %c) #0 {
%factor11 = add i32 %b, %c
%1 = add i32 %factor11, %a
%result = mul i32 %1, 3
%2 = tail call i32 (i8*, ...)* @printf(i8* getelementptr inbounds ([20 x i8]* @.str, i64 0, i64 0), i32 %a, i32 %b, i32 %result, i32 %result, i32 %result) #2
ret void
}
-reassociate的相关部分是Reassociate::OptimizeAdd()做的。
http://www.opensource.apple.com/source/clang/clang-137/src/lib/Transforms/Scalar/Reassociate.cpp
Reassociate::ReassociateExpression() -> Reassociate::LinearizeExprTree() -> Reassociate::OptimizeExpression() -> Reassociate::OptimizeAdd()
================================================
拿HotSpot 22.0也试了试上面的习题b)。发现HotSpot Server Compiler也没对这种情况优化嘛,哈哈
还是有3个加在这里,而不是理想的2个加