hiberante入门(十四):缓存
1.模拟缓存并简要说明缓存实现原理
在myhibernate项目下新建一个包com.asm.hibernate.test.cacheTest来说明与缓存有关的问题。首先看下面的一个模拟缓存程序,主要代码如下:
package com.asm.hibernate.test.cacheTest;
public class CacheSimulate {
static Map cache = new HashMap();
public static void main(String[] args) {
addUser();
//第一次查询,会去连接数据库查询
User u1 = getUser(1);
//第二次查询,直接从Map cache中取
User u2 = getUser(1);
//第三次查询,同样从cache中直接取
User u3 = getUser(1);
}
static User getUser(int id) {
String key = User.class.getName() + id;
User user = (User) cache.get(key);
if (user != null)
return user;
user = getUserFromDB(id);
cache.put(key, user);
return user;
}
static void addUser() {
省略代码,此方法的作用主要是向数据库添加一条记录,以方便查询操作
}
static User getUserFromDB(int id) {
省略代码,作用就是真正去查数据
}
}
分析:重点来看getUser方法:当我们查询一个数据时,会首先在cache中查找,如果是第一次查询某数据,cache中没有存这个数据,会去查数据库。但是如果已经查过数据,便会在cache中查找到此数据,然后直接返回。可以从控制台中看到:hibernate只与数据库交互一次。
为什么要提出缓存的概念:在前面已经多次说过与数据库建立连接是非常耗资源,而且相当耗时。为了保证高效的查询性能,才提出了缓存的概念。缓存的原理:当第一次查询时会从数据库中查,当查出数据后会把数据保存在内存中,以后查询时直接从内存中查。当然,实际的缓存要远比此模拟程序复杂,但整个缓存机制是大同小异得,只是它要考虑到更多的细节。下面来谈谈缓存机制要解决的三个主要问题:
(1)向缓存中放数据:一般是发生在查询数据库时,因为每当我们不能从缓存中得到所需数据,便会去数据库中查找,查找完成后我们自然要把它更新到数据库中。
(2)从缓存中取数据:涉及到一个key的设置问题,比如我们在模拟程序中,key的取值来自“id + 类的类型信息”,这样就能保证key值的唯一性,因为如果仅以id作为key,那么其它的类会有相同的id时,在缓存中就不能区分。
(3)清掉缓存中失效的数据:当有其它的操作更新此数据时,原数据将不再正确,这时我们可以选择更新的方式来重新把新的数据更新到缓存中,也可以直接移除原数据,即调用 remove(key)。
2.Hibernate中的一级Session缓存:
package com.asm.hibernate.test.cacheTest;
public class HibernateCacheTest {
public static void main(String[] args) {
addUser();
getUser(1);
}
static User getUser(int id) {
Session s = null;
User user = null;
try {
s = HibernateUtil.getSession();
user = (User) s.get(User.class, id);
System.out.println("userName:" + user.getName());
// session缓存,当session未关闭时,再查询直接从缓存中获得数据。
user = (User) s.get(User.class, id);
System.out.println("userName:" + user.getName());
// 如果我们清掉缓存,再查询时将会重新连库。
s.evict(user);// 清掉指定的数据
// s.clear();//清掉当前session缓存中的所有内容
user = (User) s.get(User.class, id);
System.out.println("userName:" + user.getName());
} finally {
if (s != null)
s.close();
}
// 当上面的session关闭后,如果想再获取前面查询的数据,必须重新查库。
try {
s = HibernateUtil.getSession();
user = (User) s.get(User.class, id);
System.out.println("userName:" + user.getName());
} finally {
if (s != null)
s.close();
}
return user;
}
static void addUser() {
User user = new User();
user.setName("genName");
HibernateUtil.add(user);
}
}
分析:经过上面的测试和相关说明我们可以得知如下结论:
(1)session的缓存只在session未关闭前有效,关闭后再查同的数据会重新连库
(2)我们可以手工清除session中的缓存:evict和clear
(3)如果我们清掉session中的缓存,或是第一次查询这个数据,都会引起连库
(4)save,update,savaOrUpdate,load,get,list,iterate,lock等方法都会将对象放在一级缓存中,具体可以在上例的基础上进行测试。
(5)session一级缓存不能控制缓存数量,所以在大批量操作数据时可能造成内存溢出,这时我们可以用evict,clear来清除缓存中的内容
(6)session在web开发应用中,一般只在一个用户请求时进行缓存,随后将会关闭,这个session的存活时间很短,所以它的作用不大,因此提出了二级缓存在概念。
3.二级缓存:
二级缓存通常是第三方来实现,而我们使用时只需要对它进行配置即可。下面演示使用二级缓存的具体步骤。
>>步骤一,在主配置文件中指明支持使用二级缓存:
<property name="hibernate.cache.use_second_level_cache">true</property>
我们也可以不配置此属性,因为默认就是打开二级缓存。
>>步骤二、配置第三方缓存机制:
<property name="hibernate.cache.provider_class">
org.hibernate.cache.OSCacheProvider
</property> 由于我们这里选择了OSCacheProvider(它貌似也是hibernate官方开发得缓存机制)来提供缓存,所以还需要把它的缓存配置文件放在src目录下以使配置能被读到,这里即是把hibernate解压下的etc目录中的oscache.properties文件复制到src目录下。
>>步骤三、两种方式指定要缓存的实体类,一种是在主配置文件中配置(注意class是完整的类名):<class-cache class="com.asm.hibernate.domain.User" usage="read-only"/>
另一种是在实体配置文件(映射文件)配置:比如在User.hbm.xml 的class元素下配置如下内容:<cache usage="read-only"/> 关于usage属性值的说明:
read-only:如果你的应用程序只需读取一个持久化类的实例,而无需对其修改,那么就可以对其进行只读缓存。这是最简单,也是实用性最好的方法。
read-write: 如果应用程序需要更新数据,那么使用“读/写缓存”比较合适。 如果应用程序要求“序列化事务”的隔离级别(serializable transaction isolation level),那么就决不能使用这种缓存策略。
nonstrict-read-write: 如果应用程序只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情况很不常见),也不需要十分严格的事务隔离,那么比较适合使用非严格读/写缓存策略。
transactional: Hibernate的事务缓存策略提供了全事务的缓存支持,例如对JBoss TreeCache的支持。这样的缓存只能用于JTA环境中,你必须指定为其hibernate.transaction.manager_lookup_class属性。
>>步骤四、测试二级缓存:现在仍用前面的类来测试,尽管第一个session关闭了,但是我们在第二个session查询时,仍不会连库,这也就是二级缓存的作用,通常情况下,hibernate查询时会首先在一级缓存中查询数据,再到二级缓存中查询,如果仍查不到才会连库。 这时请注意,尽管我们在一级缓存中清掉了数据,但是在二级缓存中还存有数据,所以在清掉数据后执行的查询操作也不会引起连库,这就是为什么我们最终只看到一条查询语句的原因。强调,前面说用evict或clear只是清掉一级缓存中的内容。
>>步骤五、感知二级缓存:经过上面的测试我们不能明确感知到二级缓存的作用效果,下面我们配置“统计信息”属性来进行二级缓存信息的获取。首先我们在主配置文件中配置以下属性:<property name="hibernate.generate_statistics">true</property>来打开统计信息,由于统计信息会耗资源,所以一般不打开。然后在测试类的main方法中增加如下代码:
Statistics st = HibernateUtil.getSessionFactory().getStatistics();
System.out.println(st);
System.out.println("put:" + st.getSecondLevelCachePutCount());
System.out.println("hit:" + st.getSecondLevelCacheHitCount());
System.out.println("miss:" + st.getSecondLevelCacheMissCount());
执行后结果为:
put:1
hit:2
miss:1 在进行代码结果分析前先来说两个概念:命中,miss。命中是指在二级缓存中查到数据,没有找到就称为miss. 命中率:在查询时有多少次是从缓存中得到。 下面我们看上面的执行结果put=1,说明hibernate放了一次数据到缓存中,这发生在第一次查询时,当不能在二级缓存中找到(这也是为什么会有一次miss的原因)时,会去连库并把数据放到缓存中去,使put变为1.随后进行的三次查找中:第一次仍是从一级缓存中查找到,后两次查找均在二级缓存中查到,所以命中hit=2。
4.二级缓存中的细节问题:
(1)体会save自动填充缓存,save填充缓存不支持id的native方式生成,所以我们先修改User的实体配置文件让id生成方式为:
<id name="id"> <generator class="hilo"/> </id>
后,这样修改后再来测试执行结果会发现执行结果为:
put:1
hit:3
miss:0 分析:当我们保存User对象到数据库时也会自动把此数据填充到缓存中,所以第一次put实质是发生在保存数据时。这样也就不难解释为什么hit=3,miss=0了。
(2)除了save外,update、saveOrUpdate、list、iterator、get、load(查询时从二级缓存中取数据的三个方法)、Query、Criteria都会填充二级缓存,且它们支持主键的nativa生成方式。
(3)让Query支持二级缓存:首先是主配置中配置如下属性:
<property name="#hibernate.cache.use_query_cache">true</property>因为Query命中率较低,所以默认此属性是关闭的。随后在Query方式查询时设置q.setCacheable(true);这两步执行后便完成了让Query支持二级缓存。
(4)怎样清除二级缓存:HibernateUtil.getSessionFactory().evict(User.class);这样将清除二级缓存中所有的User类相关的数据。
5.分步式缓存:
首先我们用图来模拟分步式缓存:
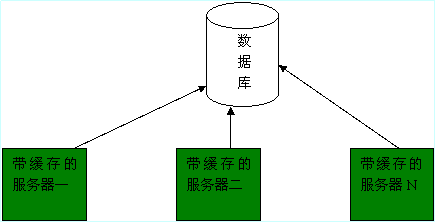
说明:在大型的web系统中,通常都会采用多个服务器来进行web服务,比如在上面的实例中,我们在服务器一存有“数据data”,在服务器二中也存有这个数据,但当我们在服务器N中更改这个数据时,如果我们继续访问在服务器一或二的数据,将不能得到正确的数据,这时采取的方式就是只要有服务器改变这个数据就在这些服务器组成的内网中广播这个信息来更新每个改变的数据。虽然服务器在内网中通讯,但是这种方式也是非常耗资源的,后来提出了“中央缓存”来解决此问题,如下图: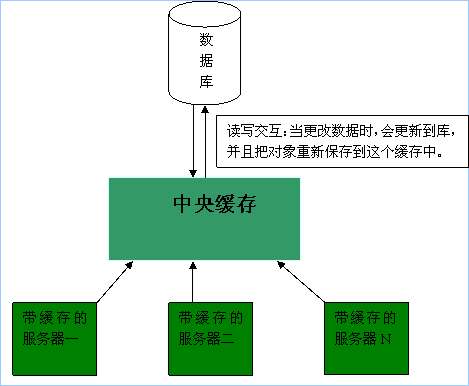
原理:当我们去某个服务器查询数据时,这个服务器会去中央缓存查询,同样如果下面的某个服务器修改数据时,中央缓存也会及时把数据更新到库并重新保存新数据。但是如果数据交互快的话,我们仍不能保证数据这些服务器访问中央缓存时是及时数据。比如在服务器一访问中央缓存修改数据时,其它的几个服务器也能访问修改,这样就不能保证及时获取正确信息。所以使用缓存的条件有如下几点:读取大于写入;数据量不能超过内存容量;对数据要有独立的控制;允许无效的数据存在。