读The Elements of Statistical learning
Chapter 2 Overview of Supervised learning
2.1 几个常用且意义相同的术语:
inputs在统计类的文献中,叫做predictors, 但经典叫法是independently variables,在模式识别中,叫做feature.
outputs,叫做responses, 经典叫法是dependently variables.
2.2 给出了回归和分类问题的基本定义
2.3 介绍两类简单的预测方法: Least square 和 KNN:
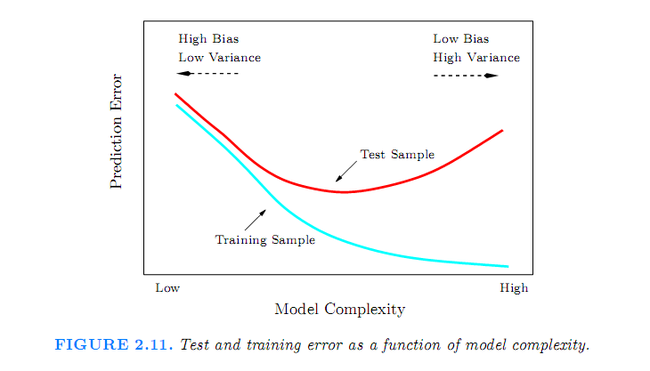
Least square产生的linear decision boundary的特点: low variance but potentially high bias;
KNN wiggly and unstabla,也就是high variance and low bias.
这一段总结蛮经典:
A large subset of the most popular techniques in use today are variants of these two simple procedures. In fact 1-nearest-neighbor, the simplest of all, captures a large percentage of the market for low-dimensional problems. The following list describes some ways in which these simple procedures have been enhanced:
~ Kernel methods use weights that decrease smoothly to zero with distance from the target point, ather than the e®ective 0=1 weights used by k-nearest neighbors.
~In high-dimensional spaces the distance kernels are modified to emphasize some variable more than others.
~Local regression fits linear models by locally weighted least squares rather than fitting constants locally.
~Linear models fit to a basis expansion of the original inputs allow arbitrarily complex models.
~Projection pursuit and neural network models consist of sums of non-linearly transformed linear models.
2.4 统计决策的理论分析
看不进去,没怎么看懂,明天看新内容前再看一遍,今天看的内容 p35-p43.
2.6节分为统计模型,监督学习介绍和函数估计的方法来介绍,统计模型给出一般问的统计概率模型,监督学习说明了用训练样例来拟合函数,函数估计介绍了常用的参数估计,选取使目标函数最大的参数作为估计.
2.7 介绍了structured regression methods,它能解决某些情况下不好解决的问题.