Trie树,又称前缀数,是一种有序树,经常用来做字典。所以又称字典树。
同样,在Glusterfs中,Trie树就作为字典树使用,完成两个功能:
1.判断用户输入的volume option是否存在
2. 若不存在,给出与用户输入最相似的选择,比较人性化。
下面一张来自维基百科 的图片形象的描述了这个数据结构
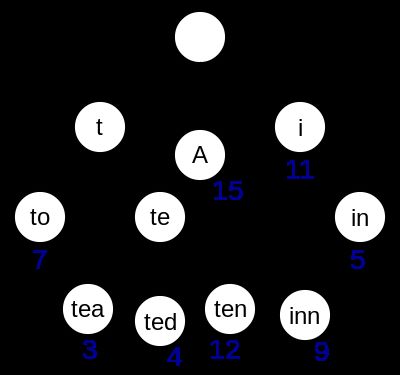
图中这颗树存储了"A", "to", "tea", "ted", "ten", "i", "in", and "inn" 共9个单词。
Trie树的实现源码在glusterfs/libglusterfs/src/trie.h&trie.c
其Trie Node的定义为:
struct trienode {
char id;
char eow;
int depth;
void *data;
struct trie *trie;
struct trienode *parent;
struct trienode *subnodes[255];
};
id 该节点的字母
eow = end of word 标识该节点是一个单词的结束。
depth 表示当前树高/树深
*data 指向用户数据
*trie 指向树本身
*parent指针 指向其父节点
*subnodes指针数组 指向其子节点,可见最多有255个子节点,和char id的取值范围对应。
Trie定义为:
struct trie {
struct trienode root;
int nodecnt;
size_t len;
};
root 根节点
nodecnt 总节点数
len
下面是相关函数:
trie_new 申请空间,创建一个trie
trie_add 添加word,调用trie_subnode, 逢山开路。
trie_subnode (trienode_t *node, int id) 创建node值为id的trienode
trie_destory 调用trienode_free释放所有节点空间。
trie_walk 调用trienode_walk递归遍历所有节点,对每个节点调用 fn函数。比如trienode_reset,collect_closest函数。
trienode_get_word 从trie树的叶子节点到根节点,获得word字符串。
trie_measure_vec,collect_closest
这两个函数是为了实现功能2,即当用户输入的option找不到,为其提供相似的option建议。
这里的代码写的比较乱,不值得看。想研究算法的不如看git 源代码中help.c:const char *help_unknown_cmd(const char *cmd)
核心算法是levenshtein distance(编辑距离)。参见算法导论 problem 15-3
最后其功能封装后的接口函数是glusterd_check_option_exists (char *key, char **completion) (in xlators/mgmt/glusterd/src/glusterd-volgen.c)