k-d tree
k-d树(k-dimensional tree)是一种空间数据分割结构,对于组织在d维空间的数据进行搜索,典型的应用如范围搜索(Range Search)和最邻近搜索(Nearest Search)。这两个术语有没有感觉很熟悉,在机器学习Clustering算法中经常用到这两个功能,如DBSCAN、OPTICS等算法。
在使用Range Query和Nearest Search过程中,如果使用遍历的方法也能完成数据空间的搜索功能,缺点很明显:穷举遍历会造成性能下降。穷举法对于数据集合本身的结构信息没有使用,大大浪费了数据的特性;如果能预先根据数据特点建立索引,能在查询过程中快速匹配,就能够加快数据检索的速度。k-d树的算法目的是对高维空间索引数据进行结果和近似查询,如快速的找到查询数据点的近邻;查找符合查询条件的范围(Range)等。
k-d树的查询有两种基本方式:
K-Neighbor Search:给定数据点及正整数K,从数据集合中查找到距离查询点最近的K个数据,kNN(K-Nearest Neighbor)算法对这种查询索引树数据结构是极其重要的。
Range Query:给定查询点和查询距离阀值,从数据集合中找到所有距离查询点小于阀值的数据点。
k-d树是一种特殊的二叉树,其中每个数据节点都是k维(k-dimensional)数据。其中每个非叶子节点都是对数据点在一个维度上一个划分:二维空间的划分是线,超过二维划分是一个超平面。如果你还是不熟悉的话,可以将K维数据缩减为1维数据,这样的话k-d树就收缩为1维平衡二叉树。再将1维数据扩张为k维,将每个非叶子节点看做是在多维数据中其中一维数据的划分,在这个维度上的数据点按照左小右大划分到子节点上。
k-d树的主要操作有:构建和查询。构建是预处理操作,将数据点构建成k-d树,方便后来的数据进行查询;查询时即时操作,在生成的k-d树中查找符合条件的数据点。下面的示例来自wiki,是二维数据点上的教程:
[(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)]
生成的k-d树如下图所示:

上图中的左侧的X和Y是划分的坐标,表示对右侧的数据点x纬度或者Y纬度进行划分,我们用一种更为简单的方式来表明这个过程:
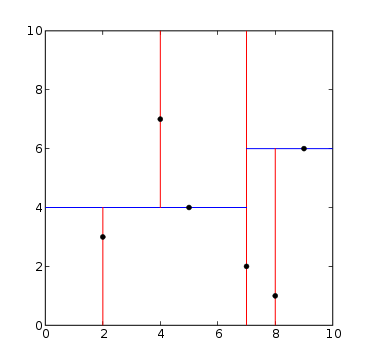
该图中的红线和蓝线就是我们的划分标准:其中红线是对于X轴划分,红线对应于Y轴划分。那么划分过程是怎样的呢?我们详细看下k-d树的构建过程,当然你也可直接参考wiki上的构建过程:

在k-d树构建过程中,depth为偶数按照x轴划分,depth为奇数的话从y轴划分,wiki上的划分是按照纬度依次划分,我们这里的举例是二维空间数据。划分是指选择从数据空间中选择一个维度,再对该纬度上的数据进行操作。这个操作比较简单,就是在该维度上对数据排序,选择中间点为锚点(Axis),将数据划分为锚点左(P1)右(P2),然后再重复迭代树的构建过程。
构建k-d树过程中有三个过程需要注意:
数据纬度选择:在上面中根据深度选择数据的纬度,这个其实并不好,通常的做法是将数据点按照纬度进行方差计算,选择方差最大的那个纬度进行纬度划分。方差越大,说明纬度分散性越好,越有利于数据划分。
数据纬度排序:将数据点在选定的纬度上进行排序,注意这个排序是数据点中的一个维度,在Python中很好实现。
数据划分:排序后将数据集合进行划分,分为Left和Right,在后面迭代计算(我为什么要写这个呢?如果优先考虑内存使用的话,这个该怎么做)。
k-d树的构建不难,我面我们看下k-d树的查找。k-d树的查找才是匹配的重要步骤,下面我们看下k-d树的最邻近查找算法。

算法中的region操作计算出数据点与周边数据点的关系,lc操作定位出数据点位置。
在wiki上有非常详细的Nearest Neighbor Search描述,建议大家仔细看下。如果感觉英文有问题的话,可以参考下https://github.com/ubilabs/kd-tree-javascript这里面的代码,交互学习。在这个链接里,有四个工程都使用了k-d树结构,推荐使用color那个项目,核心功能比较简单,能够快速入手。其实如果不在乎展示样式的话,可以直接看kdTree.js:http://ubilabs.github.com/kd-tree-javascript/kdTree.js,这里面的纬度选择也是根据深度(Depth)确定,大家可以选择自己的纬度选择实现。
复杂度分析:
查询过程中,如果查询点的邻域与分割面(由Axis确定)相交时,就需要查询分割面的另一面,导致检索过程比较复杂,效率下降。研究表明N个k维数据点形成的k-d树的搜索过程最差为:
![]()
k-d树是一种特殊的高维树结构,那么针对树节点的添加(Add)、删除(Delete)、树平衡(Rebalance)都是一个需要考虑的操作。根据上面的流程,添加或者删除树节点都会使得树平衡性受影响,如果每次都对树进行rebalance会使得代价过高。参考文献二中提出的延迟Rebalance倒是个不错的解决方法,就是将数据的添加直接附加到响应位置,删除只是标记删除字段,到树过于不平衡时再进行Balance操作。不过在平衡操作之前,树的这种非平衡结构对于Range Query和Nearest Search造成的影响需要评估下。
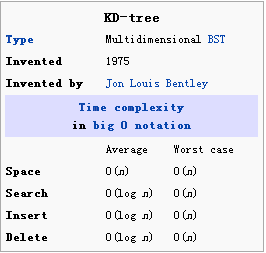
k-d树的平均时间复杂度如下图,这个不用仔细分析,在Average情况下要好于线性查找,最差情况下和线性查找相当;该图截取自wiki上:
在本文的最后,我们关于k-d树必须知道的内容:
在高维空间(High Dimensional Space,注意用词)中,k-d树并不能有效(Efficiently)的查找Nearest Neighbor数据。一般来说当N>>2**k时,k-d树的查找才会有优势,和穷举搜索(Exhaustive Search)相比;否则的话就应该使用近似最近搜索方法(Approximate Nearest Neighbour Methods)。关于近似最近搜索的进一步深入了解,请参考:Handbook of Discrete and Computational Geometry(2nd)的第29章:Nearest neighbours in high-dimensional spaces,这部分的内容我也没有深入学习过,需要找时间学习下。
关于k-d树的内容就到这里,熟悉k-d树对于机器学习来说是个很重要的内容,尽管现在的很多Machine Learning示例代码都不会涉及这个内容;实际在工程中,这些考虑都是很现实的内容。
参考文献:
http://www.cise.ufl.edu/class/cot5520fa09/CG_RangeKDtrees.pdf,该class包含许多跟计算几何相关的内容,推荐保存。
http://www.autonlab.org/autonweb/14665/version/2/part/5/data/moore-tutorial.pdf