基于词典的正向最大匹配算法(最长词优先匹配),算法会根据词典文件自动调整最大长度,分词的好坏完全取决于词典。
算法流程图如下:
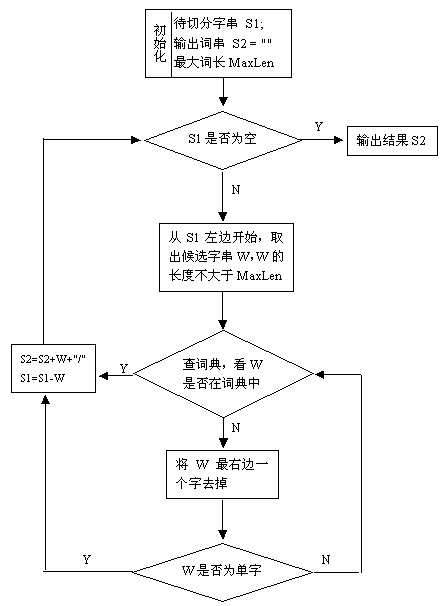
Java实现代码如下:
/**
* 基于词典的正向最大匹配算法
* @author 杨尚川
*/
public class WordSeg {
private static final List<String> DIC = new ArrayList<>();
private static final int MAX_LENGTH;
static{
try {
System.out.println("开始初始化词典");
int max=1;
int count=0;
List<String> lines = Files.readAllLines(Paths.get("D:/dic.txt"), Charset.forName("utf-8"));
for(String line : lines){
DIC.add(line);
count++;
if(line.length()>max){
max=line.length();
}
}
MAX_LENGTH = max;
System.out.println("完成初始化词典,词数目:"+count);
System.out.println("最大分词长度:"+MAX_LENGTH);
} catch (IOException ex) {
System.err.println("词典装载失败:"+ex.getMessage());
}
}
public static void main(String[] args){
String text = "杨尚川是APDPlat应用级产品开发平台的作者";
System.out.println(seg(text));
}
public static List<String> seg(String text){
List<String> result = new ArrayList<>();
while(text.length()>0){
int len=MAX_LENGTH;
if(text.length()<len){
len=text.length();
}
//取指定的最大长度的文本去词典里面匹配
String tryWord = text.substring(0, 0+len);
while(!DIC.contains(tryWord)){
//如果长度为一且在词典中未找到匹配,则按长度为一切分
if(tryWord.length()==1){
break;
}
//如果匹配不到,则长度减一继续匹配
tryWord=tryWord.substring(0, tryWord.length()-1);
}
result.add(tryWord);
//从待分词文本中去除已经分词的文本
text=text.substring(tryWord.length());
}
return result;
}
}
词典文件下载地址dic.rar,简单吧,呵呵
实现功能是简单,不过这里的词典中词的数目为:427452,我们需要频繁执行DIC.contains(tryWord))来判断一个词是否在词典中,所以优化这行代码能够显著提升分词效率(不要过早优化、不要做不成熟的优化)。
上面的代码是利用了JDK的Collection接口的contains方法来判断一个词是否在词典中,而这个方法的不同实现,其性能差异极大,上面的初始版本是用了ArrayList:List<String> DIC = new ArrayList<>()。那么这个ArrayList的性能如何呢?还有更好性能的实现吗?
通常来说,对于查找算法,在有序列表中查找比在无序列表中查找更快,分区查找比全局遍历要快。
通过查看ArrayList、LinkedList、HashSet的contains方法的源代码,发现ArrayList和LinkedList采用全局遍历的方式且未利用有序列表的优势,HashSet使用了分区查找,如果hash分布均匀冲突少,则需要遍历的列表就很少甚至不需要。理论归理论,还是写个代码来测测更直观放心,测试代码如下:
/**
* 比较词典查询算法的性能
* @author 杨尚川
*/
public class SearchTest {
//为了生成随机查询的词列表
private static final List<String> DIC_FOR_TEST = new ArrayList<>();
//通过更改这里DIC的实现来比较不同实现之间的性能
private static final List<String> DIC = new ArrayList<>();
static{
try {
System.out.println("开始初始化词典");
int count=0;
List<String> lines = Files.readAllLines(Paths.get("D:/dic.txt"), Charset.forName("utf-8"));
for(String line : lines){
DIC.add(line);
DIC_FOR_TEST.add(line);
count++;
}
System.out.println("完成初始化词典,词数目:"+count);
} catch (IOException ex) {
System.err.println("词典装载失败:"+ex.getMessage());
}
}
public static void main(String[] args){
//选取随机值
List<String> words = new ArrayList<>();
for(int i=0;i<100000;i++){
words.add(DIC_FOR_TEST.get(new Random(System.nanoTime()+i).nextInt(427452)));
}
long start = System.currentTimeMillis();
for(String word : words){
DIC.contains(word);
}
long cost = System.currentTimeMillis()-start;
System.out.println("cost time:"+cost+" ms");
}
}
#分别运行10次测试,然后取平均值 LinkedList 10000次查询 cost time:48812 ms ArrayList 10000次查询 cost time:40219 ms HashSet 10000次查询 cost time:8 ms HashSet 1000000次查询 cost time:258 ms HashSet 100000000次查询 cost time:28575 ms
我们发现HashSet性能最好,比LinkedList和ArrayList快约3个数量级!这个测试结果跟前面的分析一致,LinkedList要比ArrayList慢一些,虽然他们都是全局遍历,但是LinkedList需要操作下一个数据的引用,所以会多一些操作,LinkedList因为需要保存前驱和后继引用,占用的内存也要高一些。
虽然HashSet已经有不错的性能了,但是如果词典越来越大,内存占用越来越多怎么办?如果有一个数据结构,有接近HashSet性能的同时,又能对词典的数据进行压缩以减少内存占用,那就完美了。
前缀树(Trie)有可能可以实现“鱼与熊掌兼得”的好事,自己实现一个Trie的数据结构,代码如下:
/**
* 前缀树的Java实现
* 用于查找一个指定的字符串是否在词典中
* @author 杨尚川
*/
public class Trie {
private final TrieNode ROOT_NODE = new TrieNode('/');
public boolean contains(String item){
//去掉首尾空白字符
item=item.trim();
int len = item.length();
if(len < 1){
return false;
}
//从根节点开始查找
TrieNode node = ROOT_NODE;
for(int i=0;i<len;i++){
char character = item.charAt(i);
TrieNode child = node.getChild(character);
if(child == null){
//未找到匹配节点
return false;
}else{
//找到节点,继续往下找
node = child;
}
}
if(node.isTerminal()){
return true;
}
return false;
}
public void addAll(List<String> items){
for(String item : items){
add(item);
}
}
public void add(String item){
//去掉首尾空白字符
item=item.trim();
int len = item.length();
if(len < 1){
//长度小于1则忽略
return;
}
//从根节点开始添加
TrieNode node = ROOT_NODE;
for(int i=0;i<len;i++){
char character = item.charAt(i);
TrieNode child = node.getChildIfNotExistThenCreate(character);
//改变顶级节点
node = child;
}
//设置终结字符,表示从根节点遍历到此是一个合法的词
node.setTerminal(true);
}
private static class TrieNode{
private char character;
private boolean terminal;
private final Map<Character,TrieNode> children = new ConcurrentHashMap<>();
public TrieNode(char character){
this.character = character;
}
public boolean isTerminal() {
return terminal;
}
public void setTerminal(boolean terminal) {
this.terminal = terminal;
}
public char getCharacter() {
return character;
}
public void setCharacter(char character) {
this.character = character;
}
public Collection<TrieNode> getChildren() {
return this.children.values();
}
public TrieNode getChild(char character) {
return this.children.get(character);
}
public TrieNode getChildIfNotExistThenCreate(char character) {
TrieNode child = getChild(character);
if(child == null){
child = new TrieNode(character);
addChild(child);
}
return child;
}
public void addChild(TrieNode child) {
this.children.put(child.getCharacter(), child);
}
public void removeChild(TrieNode child) {
this.children.remove(child.getCharacter());
}
}
public void show(){
show(ROOT_NODE,"");
}
private void show(TrieNode node, String indent){
if(node.isTerminal()){
System.out.println(indent+node.getCharacter()+"(T)");
}else{
System.out.println(indent+node.getCharacter());
}
for(TrieNode item : node.getChildren()){
show(item,indent+"\t");
}
}
public static void main(String[] args){
Trie trie = new Trie();
trie.add("APDPlat");
trie.add("APP");
trie.add("APD");
trie.add("Nutch");
trie.add("Lucene");
trie.add("Hadoop");
trie.add("Solr");
trie.add("杨尚川");
trie.add("杨尚昆");
trie.add("杨尚喜");
trie.add("中华人民共和国");
trie.add("中华人民打太极");
trie.add("中华");
trie.add("中心思想");
trie.add("杨家将");
trie.show();
}
}
修改前面的测试代码,把List<String> DIC = new ArrayList<>()改为Trie DIC = new Trie(),使用Trie来做词典查找,最终的测试结果如下:
#分别运行10次测试,然后取平均值 LinkedList 10000次查询 cost time:48812 ms ArrayList 10000次查询 cost time:40219 ms HashSet 10000次查询 cost time:8 ms HashSet 1000000次查询 cost time:258 ms HashSet 100000000次查询 cost time:28575 ms Trie 10000次查询 cost time:15 ms Trie 1000000次查询 cost time:1024 ms Trie 100000000次查询 cost time:104635 ms
可以发现Trie和HashSet的性能差异较小,在半个数量级以内,通过jvisualvm惊奇地发现Trie占用的内存比HashSet的大约2.6倍,如下图所示:
HashSet:
Trie:

词典中词的数目为427452,HashSet是基于HashMap实现的,所以我们看到占内存最多的是HashMap$Node、char[]和String,手动执行GC多次,这三种类型的实例数一直在变化,当然都始终大于词数427452。Trie是基于ConcurrentHashMap实现的,所以我们看到占内存最多的是ConcurrentHashMap、ConcurrentHashMap$Node[]、ConcurrentHashMap$Node、Trie$TrieNode和Character,手动执行GC多次,发现Trie$TrieNode的实例数一直保持不变,说明427452个词经过Trie处理后的节点数为603141。
很明显地可以看到,这里Trie的实现不够好,选用ConcurrentHashMap占用的内存相当大,那么我们如何来改进呢?把ConcurrentHashMap替换为HashMap可以吗?HashSet不是也基于HashMap吗?看看把ConcurrentHashMap替换为HashMap后的效果,如下图所示:

内存占用虽然少了10M左右,但仍然是HashSet的约2.4倍,本来是打算使用Trie来节省内存,没想反正更加占用内存了,既然使用HashMap来实现Trie占用内存极高,那么试试使用数组的方式,如下代码所示:
/**
* 前缀树的Java实现
* 用于查找一个指定的字符串是否在词典中
* @author 杨尚川
*/
public class TrieV2 {
private final TrieNode ROOT_NODE = new TrieNode('/');
public boolean contains(String item){
//去掉首尾空白字符
item=item.trim();
int len = item.length();
if(len < 1){
return false;
}
//从根节点开始查找
TrieNode node = ROOT_NODE;
for(int i=0;i<len;i++){
char character = item.charAt(i);
TrieNode child = node.getChild(character);
if(child == null){
//未找到匹配节点
return false;
}else{
//找到节点,继续往下找
node = child;
}
}
if(node.isTerminal()){
return true;
}
return false;
}
public void addAll(List<String> items){
for(String item : items){
add(item);
}
}
public void add(String item){
//去掉首尾空白字符
item=item.trim();
int len = item.length();
if(len < 1){
//长度小于1则忽略
return;
}
//从根节点开始添加
TrieNode node = ROOT_NODE;
for(int i=0;i<len;i++){
char character = item.charAt(i);
TrieNode child = node.getChildIfNotExistThenCreate(character);
//改变顶级节点
node = child;
}
//设置终结字符,表示从根节点遍历到此是一个合法的词
node.setTerminal(true);
}
private static class TrieNode{
private char character;
private boolean terminal;
private TrieNode[] children = new TrieNode[0];
public TrieNode(char character){
this.character = character;
}
public boolean isTerminal() {
return terminal;
}
public void setTerminal(boolean terminal) {
this.terminal = terminal;
}
public char getCharacter() {
return character;
}
public void setCharacter(char character) {
this.character = character;
}
public Collection<TrieNode> getChildren() {
return Arrays.asList(children);
}
public TrieNode getChild(char character) {
for(TrieNode child : children){
if(child.getCharacter() == character){
return child;
}
}
return null;
}
public TrieNode getChildIfNotExistThenCreate(char character) {
TrieNode child = getChild(character);
if(child == null){
child = new TrieNode(character);
addChild(child);
}
return child;
}
public void addChild(TrieNode child) {
children = Arrays.copyOf(children, children.length+1);
this.children[children.length-1]=child;
}
}
public void show(){
show(ROOT_NODE,"");
}
private void show(TrieNode node, String indent){
if(node.isTerminal()){
System.out.println(indent+node.getCharacter()+"(T)");
}else{
System.out.println(indent+node.getCharacter());
}
for(TrieNode item : node.getChildren()){
show(item,indent+"\t");
}
}
public static void main(String[] args){
TrieV2 trie = new TrieV2();
trie.add("APDPlat");
trie.add("APP");
trie.add("APD");
trie.add("杨尚川");
trie.add("杨尚昆");
trie.add("杨尚喜");
trie.add("中华人民共和国");
trie.add("中华人民打太极");
trie.add("中华");
trie.add("中心思想");
trie.add("杨家将");
trie.show();
}
}
内存占用情况如下图所示:

现在内存占用只有HashSet方式的80%了,内存问题总算是解决了,进一步分析,如果词典够大,词典中有共同前缀的词足够多,节省的内存空间一定非常客观。那么性能呢?看如下重新测试的数据:
#分别运行10次测试,然后取平均值 LinkedList 10000次查询 cost time:48812 ms ArrayList 10000次查询 cost time:40219 ms HashSet 10000次查询 cost time:8 ms HashSet 1000000次查询 cost time:258 ms HashSet 100000000次查询 cost time:28575 ms Trie 10000次查询 cost time:15 ms Trie 1000000次查询 cost time:1024 ms Trie 100000000次查询 cost time:104635 TrieV1 10000次查询 cost time:16 ms TrieV1 1000000次查询 cost time:780 ms TrieV1 100000000次查询 cost time:90949 ms TrieV2 10000次查询 cost time:50 ms TrieV2 1000000次查询 cost time:4361 ms TrieV2 100000000次查询 cost time:483398
总结一下,ArrayList和LinkedList方式实在太慢,跟最快的HashSet比将近慢约3个数量级,果断抛弃。Trie比HashSet慢约半个数量级,内存占用多约2.6倍,改进的TrieV1比Trie稍微节省一点内存约10%,速度差不多。进一步改进的TrieV2比Trie大大节省内存,只有HashSet的80%,不过速度比HashSet慢约1.5个数量级。
TrieV2实现了节省内存的目标,节省了约70%,但是速度也慢了,慢了约10倍,可以对TrieV2做进一步优化,TrieNode的数组children采用有序数组,采用二分查找来加速。
下面看看TrieV3的实现:

使用了一个新的方法insert来加入数组元素,从无到有构建有序数组,把新的元素插入到已有的有序数组中,insert的代码如下:
/**
* 将一个字符追加到有序数组
* @param array 有序数组
* @param element 字符
* @return 新的有序数字
*/
private TrieNode[] insert(TrieNode[] array, TrieNode element){
int length = array.length;
if(length == 0){
array = new TrieNode[1];
array[0] = element;
return array;
}
TrieNode[] newArray = new TrieNode[length+1];
boolean insert=false;
for(int i=0; i<length; i++){
if(element.getCharacter() <= array[i].getCharacter()){
//新元素找到合适的插入位置
newArray[i]=element;
//将array中剩下的元素依次加入newArray即可退出比较操作
System.arraycopy(array, i, newArray, i+1, length-i);
insert=true;
break;
}else{
newArray[i]=array[i];
}
}
if(!insert){
//将新元素追加到尾部
newArray[length]=element;
}
return newArray;
}
有了有序数组,在搜索的时候就可以利用有序数组的优势,重构搜索方法getChild:

数组中的元素是TrieNode,所以需要自定义TrieNode的比较方法:

好了,一个基于有序数组的二分搜索的性能提升重构就完成了,良好的单元测试是重构的安全防护网,没有单元测试的重构就犹如高空走钢索却没有防护垫一样危险,同时,不过早优化,不做不成熟的优化是我们应该谨记的原则,要根据应用的具体场景在算法的时空中做权衡。
OK,看看TrieV3的性能表现,当然了,内存使用没有变化,和TrieV2一样:
TrieV2 10000次查询 cost time:50 ms TrieV2 1000000次查询 cost time:4361 ms TrieV2 100000000次查询 cost time:483398 ms TrieV3 10000次查询 cost time:21 ms TrieV3 1000000次查询 cost time:1264 ms TrieV3 100000000次查询 cost time:121740 ms
提升效果很明显,约4倍。性能还有提升的空间吗?呵呵......
参考资料:
1、中文分词十年回顾