用 Slice 扩展 OpenJPA 应用程序
Slice 将 OpenJPA 扩展用于一个分布式的、水平分区的数据库环境。一个使用单个数据库的基于 OpenJPA 的应用程序可以由 Slice 针对数据跨多个数据库分区存储的存储环境进行重新配置。这种升级不需要在应用程序代码或数据库模式方面做任何更改。
水平数据分区最直接的好处是在有大量数据时提升性能,尤其是对于那些作业或查询的事务单元通常都限于整个数据集的子集的应用程序(比 如,多租户 Software-as-Service 平台或按地理区域分区的客户数据库)。在这类场景下,像 Slice 这样的基于数据分区的解决方案会非常有用,因为 Slice 不仅可以跨多个分区并行执行所有的数据库操作来充分利用多核硬件以及 I/O 绑定操作的并发性,而且数据库查询还可以针对于分区的子集。
本文将介绍:
- 如何为 Slice 配置一个应用程序
- Slice 如何跨分区分配数据
- 它如何聚集和分类来自很多分区的查询结果
- 为了让分区能有效地并行操作应满足的条件
- 为了扩展 OpenJPA 运行时来适应分区的数据库,Slice 应解决的核心设计/架构挑战
Java™ Persistence API (JPA) 是关于管理对象持久化到系数据库的一个规范。JPA 内的核心概念构成是 Persistence Unit 和 Persistence Context,被认为是两个接口:javax.persistence 包内的 EntityManagerFactory 和 EntityManager 。一个持久单元表示:
- 一组持久 Java 类型
- 它们的映射规范
- 数据库连接属性
- 一组特定于供应商的定制属性
一个持久上下文表示的是一组管理的持久实例。持久性上下文也是持久操作的基础界面,比如:
- 创建新实例
- 通过实例的主 ID 找到实例
- 通过基于字符串或动态构建的查询选择实例
- 划分事务边界
一个持久上下文管理这些实例,应用程序对持久状态的任何变化均由 JPA 提供者监视。在事务完成或上下文清仓时,会自动更新有关的数据库记录。
总之,JPA 所倡导的是一种应用程序编程模型,其中持久性操作和查询涉及 Java 对象模型,而提供者负责将对象模型映射到数据库模式:一个 Java 类转变成一个或多个数据库表,Java 类型的持久性属性转变为数据库列、关系变成外键等;并且,持久性操作也变成了 SQL 语句:Java 的 new() 操作符映射为一个或多个 INSERT ,find() 映射为 SELECT ,持久实例的 setter 方法变为数据库的一个 UPDATE 语句。
核心的 JPA 规范是基于这样一个隐式且严格的假设,即持久对象和操作被映射到一个关系数据库。每个持久单元均连接到一个单一数据库,并且管里的持久性对象状态也存储到 同一个数据库。Slice 完全打破了单一数据库的这个假设。Slice 允许相同的 JPA 应用程序的执行,而同时底层的数据存储环境也已经从一个超大型的数据库变成了一组被水平分区的数据库。存储了整个数据集的子集的这些物理数据库被称为是分 区、碎片或片。
正式来讲,对数据集 D 的 P(D) 进行水平 分区 或划分就是将 D 分解成相互不相交的 N 个集 D i 且:
D = D1 ∪ D2 ∪ ⋯ ∪ Dn ,当 i ≠ j时,Di ∩ Dn = ∅ |
Slice 引入了抽象的虚拟数据库来绕过底层的物理数据库分区或划分。一个启用了 Slice 的应用程序内持久单元连接到的是单一的一个虚拟数据库,而这个虚拟数据库则可通过恰当的 JDBC 驱动器将所有的持久操作多路传输给实际的物理数据库。比如说,有一个启用了 Slice 的应用程序,它被配置成使用四个片或分区,然后在这四个片上并行执行一个 JPA 查询,比如 select c from Customer c where c.age > 20 order by c.age 。 每个片各自排序了的执行结果被合并,并且在内存内由虚拟数据库再次进行排序,之后才会呈现给此应用程序。由于从用户应用程序的角度看,这个虚拟数据库接口 提供了与单个数据库相同的 API,因而应用程序代码和数据库模式均不需要修改就能从一个单数据库调整到一个分布的、分区数据库环境。这是因为 Slice 内的虚拟数据库抽象遵循的是 复合设计模式 。这种无缝的特性是 Slice 最为强大的实用特性。
有一点值得注意,若是为每个持久单元配置一个单独的分区,或是一个持久单元,配置每个 EntityManager 来连接一个分区,这样的处理分区的方式是站不住脚的。
为什么呢?这是因为 JPA 规范对持久性上下文的管理实例施加的了一个类似组的行为。
使用 Slice 只需重新配置,一个应用程序就可以升级到一个分区的数据库环境。本节介绍了 Slice 的用户配置属性以及它们如何表示不同的功能。Slice 的配置使用了与配置任何标准 JPA 运行时(比如,让 META-INF/persistence.xml 资源对类路径可视)相同的机制。META-INF/persistence.xml 通常包含特定于提供者的属性,比如名称-值对,此外还有其他的一些 JPA 规范定义的属性,比如持久性类名或映射描述符。特定于 Slice 的属性在特定于提供者的属性节内提及,以 openjpa.slice.* 作为前缀。
配置属性可以被分成三大组:
- 用来整体配置存储环境的属性
- 用来配置单个片的属性
- 用来配置运行时行为的属性
让我们看看这些属性以及它们是如何影响行为的。
首先,考虑这样一个环境,其中数据被分区到三个 Apache Derby 数据库。这些数据库由它们的逻辑片标识 :One 、Two 和 Three 标识。逻辑片标识是一个简单可读懂的名称,可惟一(在某个持久单元的范围内)代表一个物理的数据库 URL 及其其他细节。为了针对分区数据库环境配置 Slice,此 persistence.xml 应如清单 1 所示。
<persistence-unit
name
="slice"
>
<properties>
<property
name
="openjpa.BrokerFactory"
value
="slice"
/>
<property
name
="openjpa.slice.Names"
value
="One,Two, Three"
/>
<property
name
="openjpa.slice.Master"
value
="One"
/>
<property
name
="openjpa.slice.Lenient"
value
="true"
/>
<property
name
="openjpa.ConnectionDriverName"
value
="org.apache.derby.jdbc.EmbeddedDriver"
/>
<property
name
="openjpa.slice.One.ConnectionURL"
value
="jdbc:derby:target/database/slice1"
/>
<property
name
="openjpa.slice.Two.ConnectionURL"
value
="jdbc:derby:target/database/slice2"
/>
<property
name
="openjpa.slice.Three.ConnectionURL"
value
="jdbc:some-bad-url"
/>
<property
name
="openjpa.slice.DistributionPolicy"
value
="acme.UserDistributionPolicy"
/>
</properties>
</persistence-unit>
|
激活 Slice 的首要属性是:
<property
name
="openjpa.BrokerFactory"
value
="slice"
/>
|
这个属性指导 OpenJPA 运行时创建一个专用持久单元,这个单元连接到与一组物理数据库相关的虚拟数据库。该属性是强制的。
下一个重要属性是逻辑片标识的一个列表。
<property
name
="openjpa.slice.Names"
value
="One,Two,Three"
/>
|
这个属性值以逗号分隔列表的形式列出所有可用的逻辑标识。一个逻辑的标识不 能与物理数据库的名称相同。逻辑标识是持久单元内某特定片的惟一标识。例如,特定于一个片的每个配置属性名均以一个逻辑标识开头,比如:
<property
name
="openjpa.slice.One.ConnectionURL"
value
="…"
/>
|
不过,不需要通过 openjpa.slice.Names 属性强制 列出逻辑标识。如果此属性是指定的,那么会扫描整个 persistence.xml 来识别所有的惟一逻辑片标识。建议明确地枚举这些逻辑标识。我稍候会对之做更多解释。
这个主片被用来在任何需要的时候为管理实例生成主标识。根据 JPA 规范,每个持久实例必须具有持久 id。这个 id 的值可以由应用程序指定或由数据库序列生成。在后者的情况下,为了维护多数据库环境内由数据库生成的主键的惟一性,这些片中必须有一个片被指定用来生成这 些键。这个被特别指定的片就被称为是主片 。
通过如下属性将一个片指定为主片:
<property
name
="openjpa.slice.Master"
value
="One"
/>
|
主片的显式指定并不是强制的。如果这个属性没有指定,第一个片将被指定为主片。当然这时的有效词是 first 。这里假设这些片需要进行排序。这些片的排序在 openjpa.slice.Names 显式指定时,由此列表施加。否则,这些片会按其标识的字母顺序进行排序(虽然是试探式的,但的确是一种排序)。为了避免这类隐式的试探,建议显式指定 openjpa.slice.Names 和 openjpa.slice.Master 。
在一个多数据库场景中,可能会有一个或多个数据库不可用。当 Slice 不能连接到一个或多个分区时,就由如下的属性支配行为:
<property
name
="openjpa.slice.Lenient"
value
="true"
/>
|
将这个属性设置为 true 就可以让 Slice 在一个或多个片不可用时仍可继续。默认情况下,这个值是 false ,并且如果这些已配置的片中有一个片是不可连接的,Slice 将不能启动。正如本例所展示的,第三个片指向的是一个无效的数据库 URL。这时,若将这个属性设为 true ,就能让 Slice 在有两个有效的片的情况下也能启动并会忽略那个不能获取的片。
每个由逻辑标识符标识的片必须指定其物理数据库 URL 和其他的一些属性。如下的例子显示了一个片的特定于片的配置,逻辑上标识为 One :
<property
name
="openjpa.slice.One.ConnectionURL"
value
="jdbc:derby:target/database/slice1"
/>
|
这个属性将逻辑上标识为 One 的分区分配给一个 URL 为 jdbc:derby:target/database/slice1 的 Derby 数据库的一个物理实例。
如前面所提到的,每个特定于片的配置属性名均以 openjpa.slice.<logical slice identifier> 开头,后跟原始 OpenJPA 属性键后缀,比如 ConnectionURL 。这种命名约定让用户可以用任意的 OpenJPA 属性独立配置每个片。另一方面,一些跨片常见的配置属性可以被简单地指定为原始的 OpenJPA 属性。这样一来,在这个示例配置中,此 JDBC 数据库驱动器就可以被指定为常见属性并应用到所有片,如下所示:
<property
name
="openjpa.ConnectionDriverName"
value
="org.apache.derby.jdbc.EmbeddedDriver"
/>
|
请注意,对于 Slice,完全可以安照如下所示指定逻辑标识为 Four 的第 4 个片,用来代表相同配置中的一个 MySQL 数据库:
<property
name
="openjpa.slice.Four.ConnectionURL"
value
="jdbc:mysql://localhost/slice4"
/>
<property
name
="openjpa.slice.Four.ConnectionDriverName"
value
="com.mysql.jdbc.Driver"
/>
|
在这个例子中,特定于片的那些属性将会覆盖这个特定的第 4 个片的常见属性。
Slice 的主要设计目标是封装存储环境,以便于应用程序代码能够与在典型的单数据库中使用的代码保持一致。而另一方面,用户应用程序将需要位于底层片上的信息以及 某种程度的控制,比如,将某些查询指向活动片的某个特定的子集。为了在不影响应用程序代码的情况下,保持激活 Slice 的这些多少有点矛盾的目标,同时又能允许某些控制,Slice 采用了一个内置的基于策略的方式。策略接口由用户应用程序实现并在配置中指定。在运行时期间,Slice 回调至用户实现并使用所返回的值来控制流程。可用的策略机制为:
- 数据分布策略 — 控制由哪个片存储新持久化了的实例
- 复制策略 — 控制由哪个片存储被复制的实例
- 查询定向策略 — 将查询定向为在片的一个子集上执行
- 查找定向策略 — 将根据主键操作的查找定向为在片的一个子集上执行
本节将依次就这些可配置的策略详细介绍 Slice 与分布式数据库环境相关的运行时行为。
Slice 不要求任何的数据库模式的变更。而基于分区的类似的持久性解决方案通常都需要向数据库模式添加一个特殊的列来识别分区标识。Slice 不 需要这类额外的模式层的信息,因为它根据持久性实例的逻辑名维护了实例和其原始数据库分区间的关联。这种关联是在从一个特定的片读出持久性实例时建立的。 但当新的实例正在持久化时,Slice 并不能决定哪个数据库分区应与这个新实例相关联。因此,应用程序必须指定与新实例相关联的那个片。应用程序就是通过数据分布策略指定与新实例相关联的片 的。这个策略可以在 persistence.xml 内根据如下所示配置:
<property
name
="openjpa.slice.DistributionPolicy"
value
="acme.UserDistributionPolicy"
/>
|
这个属性值指定 org.apache.openjpa.slice.DistributionPolicy 接口的一个用户实现的全限定类名。这个接口协议允许用户应用程序决定这个新持久项的逻辑片。
package org.apache.openjpa.slice;
public interface DistributionPolicy {
String distribute(Object pc, List<String> slices, Object context);
}
|
输入参数:
-
pc是要被持久化的实例。这个实例与作为输入参数传递至EntityManager.persist(pc)的是同一个实例。 -
slices是逻辑片标识的一个不可变列表。这个列表不包含目前不可连接的那些片。 -
context是一个保留为未来使用的不透明对象。一般地,就实现而言,这个上下文与当前的持久性上下文相同。这个隐式语义并不能保证未来的使用。
该实现必须返回一个给定的逻辑片标识符中。
Slice 在被持久化的每个根对象实例上调用这个用户实现。此根对象实例是被此应用程序调用的 EntityManager.persist(Object r) 的显式输入参数。有一点值得注意的是单独一项 r 上的一个显式 persist(r) 操作可间接地持久化其他的相关项。JPA 注释(或映射描述符)可用一个持久操作,比如 persist() 、refresh() 、merge() 或 remove() 将如何顺该关系路径层叠来修饰一个 Java 引用关系。因此,如果一个实例 r 与另一个实例 q 相关,并且 r 和 q 间的关系是由层叠 PERSIST 注释的,那么 q 作为持久化 r 的副作用也将被持久化。这个行为也被称为是传递持久化。
Slice 在持久化一个新的根实例 r 时所作的关键决定是:所有从 r 可获得的相关项均存储在相同的片内。因而,数据分布策略的用户实现只 为根项 r 调用。根据当前的分布策略,Slice 自动地为根实例计算传递闭包 C(r) 并将 C(r) 的每个成员分配到 r 的同一个片。传递闭包的并置是必须的,因为这个虚拟数据库不能执行跨物理数据库的连接,因此,如果逻辑关联的记录位于不同的数据库,那么就不能急于获取关系。这个限制就被称为是并置限制 。稍后,我们将讨论如何处理并置限制(比如,一个懒惰关系可跨分区存在或同一个项实例如何能在多片间复制)。
对于大多数应用程序,数据分布策略由用户应用程序提供,但 Slice 自身为初学者或实验原型也提供了几个开箱即用的实现策略。默认的开箱即用的策略会向每个新实例分配一个随机的片。
分布策略被用于在单片内存储项,但并置限制要求所有相关实例都被存储在同一个片内。对于某些常用的数据使用模式,这个限制太过严格(例 如,像 Stock Ticker Symbol 或 Country Code 或 Customer Type 这样的被很多其他类型引用的主数据)。在这种情况下,一个类型可被指定为跨多片复制。persistence.xml 配置必须以逗号分隔列表的形式枚举类型的名称:
<property
name
="openjpa.slice.ReplicatedTypes"
value
="acme.domain.Foo,acme.domain.Bar"
/>
|
持久化一个类型被复制过的实例会调用复制策略而非数据分布策略。由于一个复制了的项可被存储在多个片内,此策略接口类似于数据分布策略,但在返回类型方面有所差异。
package org.apache.openjpa.slice;
public interface ReplicationPolicy {
String[] replicate(Object pc, List<String> slices, Object context);
}
|
虽然输入参数的语义与数据分布策略内的相同,返回值现在包含一个片标识的数组,而非单一一个片标识。空返回值意味着所有片都是活动的, 而空数组则会引发一个异常。同样地,Slice 会跟踪所有存储了被复制项的片标识并会在被复制实例发生改变时,将相同的更新反映到所有的这些片。因而,一个复制项实例可被视为是在几个数据库内有多个相 同副本的单个逻辑项。默认的复制策略会将此项复制给所有的活动片。
若一个查询调用了一个复制了的类型,那么 Slice 会为这些复制项从这些片中过滤出单个结果以便类似 'select count(o) from CountryCode o ' 这样的合计查询不会因计数来自多个片的重复 CountryCode 实例而返回不正确结果。
默认情况下,Slice 会跨所有的活动片执行查询并在需要的时候在内存中合并结果。而用户则可以将每个要执行的查询定向给片的一个子集。用户应用程序可以通过查询定向策略接口控制这类查询定向。
package org.apache.openjpa.slice;
public interface QueryTargetPolicy {
String[] getTargets(String query, Map<Object,Object> \
params, List<String> slices, Object context);
}
|
输入参数有:query ,它是一个 JPQL 字符串;以及 params ,它是此查询的绑定参数值,每个按键索引。余下的参数与数据分布或复制策略中的参数具有同样的语义。
返回值会指定给定查询将要在其上执行的那些片。空的或 null 数组不是一个有效的返回值。在执行每个查询前,会调用此接口。没有默认的查询定向原则。
查找定向策略与查询定向策略相似,只不过,这里没有 find() 调用的绑定参数。这个接口如清单 5 所示。
package org.apache.openjpa.slice;
public interface FinderTargetPolicy {
String[] getTargets(Class<?> cls, Object oid, List<String> slices, Object context);
}
|
输入参数有:cls ,它是正在被查询的这个项类;以及 oid ,它是正在被查询的持久性标识。余下的参数与其他策略的参数具有相同的语义。
返回值的协议也有着与查询定向策略相似的语义。
由于没有默认的查找定向策略,因此,find() 会默认地在所有片内查找一个实例。
Slice 会在每片的并行线程中执行数据库操作。这些线程根据每个持久性单元保存在线程的缓存池内。这个池依应用程序对并行的需求而增长,并且那些已完成执行的线程会被返回到这个池。
此虚拟数据库会协调这些查询在物理数据库上的执行,并会在内存内置后处理各个查询的结果用以准备一个合并结果。如下会给出一些典型的查询以进一步说明。
图 1 是一个简单的查询,其中来自各个片的结果无需在内存中做进一步的处理。

select e from Employee e where e.age < 30
|
这个查询谓词根据每个片情况加以评估。最终的结果列表是来自各片的结果列表的串接。逻辑片标识的排序很重要,并能有效决定所选元素的排序。这个排序是由查询定位策略返回的片标识的排序决定的,或是如前面提到的通过显式的 openjpa.slice.Names 配置排序,或隐式的字母排序。假定有 {slice1, slice2, slice3} 这样的一个排序,合并结果清单中的元素将以同样的顺序出现。请注意,第三个片没有返回任何选项。
我们的下一个例子,如图 2 所示,是一个含有 ORDER BY 子句的查询,它使用了下面的代码:
select e from Employee e where e.age < 30 order by e.name
|
图 2. 含有 ORDER BY 子句的查询需要内存内的合并 
各个查询结果在内存中被合并然后排序。如果 L i 是来自第 i 个片的排序列表,那么这个合并结果列表 L 就是:
L = sort(ΣLi)
|
如果每个列表 L i 由自已排序,那么内存内的排序操作(从存储和计算的角度)可以变得很有效。
在这个示例中,结果列表是每个片各自排序的列表的合并版本。因此,如果根据片的自然排序,来自第一个片的应该是 "Mary",但在这个结果列表中首先出现的却是 "Bill",这是由于它们是按照其名称的字母顺序排序的。
在图 3 中是我们的第三个例子,其中,查询结果被限制在头 N 个元素。

Top-N 查询在 JPA 中是通过该查询中的 ORDER BY 子句与对结果设定限制的结合实现的。下面的这个查询要找出 5 个最年轻的员工:
em.createQuery(“select e from Employee e order by e.age”)
.setMaxResults(5)
.getResultList();
|
在一个分布式的查询环境中,这个查询会在每个片上分别执行,并且这些合并列表顶部的两个元素的评估发生在内存内的虚拟数据库层。同样地,内存内的 Top-N 计算使用了这样一个事实,即如果一个元素 x 出现在最后的列表 L 内,那么 x 必须也出现在各列表 L i 中的一个列表内。
设 A(D) 是一个在数据集 D 上被求值的聚集操作(例如 SUM() 或 MAX() )。
聚合操作符被定义为可互换分区(commutative to partition) 如果 A(D) = A(R) 其中 R 是在每个分区上的 A() 求值集合 — R = {A(D i ), i=1 N) 。
图 4 展示了一个分区可互换的聚集操作。
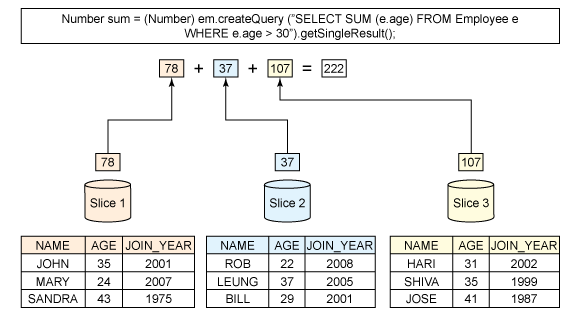
这个样例查询是来自 Employee e 的 select SUM(e.age),其中 e.age > 30 。如果 S 指定所有片上的年龄在 30 岁以上员工的年龄总和并且如果 S i 是第 i 片内的总和,那么很简单,S 就是 S i 的总和。因而,SUM() 就是可互换分区。Slice 可以计算所有可互换分区的聚集操作,比如 MAX() 、MIN() 、 SUM() 或 COUNT() 。
并不是所有常见的聚集操作都是分区可互换的,比如 AVG() 。目前,Slice 可以正确地估计一个聚集查询,不是分区可互换的。
涉及 EntityManager 的事务可以由 Java Transaction API (JTA) 控制,也可以由应用程序通过 EntityTransaction API 控制,它映射到底层数据库资源上的一个资源事务。对于 JTA EntityManager,JTA 事务被传递到底层的资源管理器(即虚拟数据库,由它将这个事务中继到物理数据库)。一个具有 3 个 JNDI 注册的数据资源的 JTA 事务的容器环境是一种典型的配置。
<persistence-unit name=”slice” transaction-type=”JTA”>
<property name="openjpa.slice.Names" value="One,Two,Three"/>
<property name="openjpa.slice.Master" value="One"/>
<property name="openjpa.slice.One.ConnectionFactoryName"
value="jdbc/slice-ds1"/>
<property name="openjpa.slice.Two.ConnectionFactoryName"
value="jdbc/slice-ds2"/>
<property name="openjpa.slice.Three.ConnectionFactoryName"
value="jdbc/slice-ds3"/>
</persistence-unit>
|
对于一个本地资源 EntityManager ,底层的资源管理器充当了物理数据库上的一个事务管理器,但 使用的是一种较弱的事务保证,而不是合适的两阶段落实协议。在一个资源本地的事务中,首先分析作业单元来将管理实例分区到每个底层片的子集。然后每个子集 被清仓到对应的数据库。如果一个片的子集是空的,它将被忽略。如果清仓对于所有数据库均失败,那么整个事务就会被回滚。
之前,我们看到了,数据分布策略描述了 Slice 在级联 PERSIST 后 如何自动计算根实例 r 的传递闭包 C(r) ,并将整个闭包存储于单个片内的。值得注意的一点是闭包是在 persist() 调用的时候计算的。因而,在 persist() 后添加的关系不是此显式闭包的一部分。
在通过在根项的关系被分配好后持久化根项来确保满足并置限制的同时,也需要注意在不同的片存储相关的实例会故意违背并置限制的事实。让我们用一个实际例子来阐释这一点。
考虑这样一个例子:Person 和 Address 间存在简单的 1:1 的双向关系。Person.address 由 PERSIST 级联。在映射的术语中,Person 是此关系的所有者(即 ADDRESS 表的外键存在于 PERSON 表内)。
假设我们有两个片 — One 和 Two — 并且我们的分布策略是这样的:如果 Person 的名字以字母 A 到 M 开头,那么它就存储在片 One 内。否则,就存储在片 Two 内。同样地,如果 Address 的 ZIP 代码以偶数结尾,那么它就存储在片 One 内。否则,它存储在片 Two 内。
在这些简单的规则下,让我们创建一个 Person p 和一个 Address a 实例并存储它们。
Person p = new Person();
p.setName(“Alan”); // slice One as name starts with letter A
Address a = new Address();
a.setZipCode(12345); // slice Two as zip code is odd digit
em.getTransaction().begin();
p.setAddress(a);
em.persist(p); // relation to address is set before persist
// Address persisted by transitive persistence
em.getTransaction().commit();
|
在清单 7 中,Person p 与 Address a 相关,当调用 em.persist(p) 时,Address a 将被作为 Person p 存储在相同的片 One 中。根据分布策略,Address 实例 a 本应该存储在片 Two 内,因为该实例的 ZIP 代码以奇数结尾。但根本不会为 Address a 调用这个策略,这个策略只会为根实例 Person p 调用。Slice 觉察到 a 处在 p 的传递闭包内并且,随着 p 被分布策略分配给片 One ,那么同一个片 One 也会自动分配给 Address a 。
清单 8 内的代码展示了如果持久化调用排序不同时将会如何。
em.getTransaction().begin();
em.persist(p); // relation to address is not set before persist
p.setAddress(a);
em.persist(a); // a has to be persisted explicitly
em.getTransaction().commit();
|
分布策略将为 person p 和 Address a 单独调用,而二者位于两个不同的片中。
这样,尽管可能会违背并置限制,并将相关的示例存储在不同的片中,但这种存储策略的实用性很有限。当 Person 及其相关的 Address 位于不同的数据库时,能执行的操作只有几个。例如,可以从拥有侧迟钝加载此关系(即,如果这个关系是迟钝的,那么 Person.getAddress() 即便是从其他的数据库也可以获取正确的地址)。如果关系是迫切需要的或从非拥有侧导航来的或者是要求类似像 'select p from Person p where p.address.zipcode = 12345' 这样的连接的一个查询,那么它将生成一个错误结果。
数据分区是在有大量数据时进行扩展的一种有效策略,特别是在有自然分区存在的情况下(例如,根据名称的客户账号,按地区的家庭列表)或 是在应用程序语义要求数据分离的情况下(例如,多租户托管平台)。标准 JPA 没有处理分区或分配的有效方式,因为规范已经隐式地假定单个数据库作为存储库。Slice 扩展了 OpenJPA 实现,使其能够无缝地支持数据分区。与其他的分区解决方案不同,Slice 并不需要向现有模式中添加任何额外的列以支持分区。使用 Slice 的分布和查询目标锁定是通过一个基于策略的插件接口提供的,确保了现有的 JPA 的应用程序无需进行代码修改(只需添加新的策略接口以及重新配置 persistence.xml )。
学习
- 更多地了解 OpenJPA 及其功能。
- 参见有关 Java Persistence API Specification V2.0 的规范。
- 在 Wikipedia 上更多地了解数据分区概念 。
- 要收听面向软件开发人员的有趣访谈和讨论,请查看 developerWorks 播客 。
- 查阅最近将在全球举办的面向 IBM 开放源码开发人员的研讨会、交易展览、网络广播和其他 活动 。
- 访问 developerWorks Open source 专区 获得丰富的 how-to 信息、工具和项目更新以及最受欢迎的文章和教程 ,帮助您用开放源码技术进行开发,并将它们与 IBM 产品结合使用。
- 随时关注 developerWorks 技术活动 和网络广播 。
- 查看免费的 developerWorks 演示中心 ,观看并了解 IBM 及开源技术和产品功能。
原文:http://www.ibm.com/developerworks/cn/opensource/os-openjpa/index.html?ca=drs-