http://dubing.blog.51cto.com/3911153/757518
跳出一致性Hash算法 打造更高效的分布式缓存
http://dubing.blog.51cto.com/3911153/757518
跳出一致性Hash算法 打造更高效的分布式缓存
背景
谈到分布式缓存,大家首先想到的是memcached。确实memcached是目前最流行的方案之一。不过很多互联网公司不用memcached,例如新蛋。为什么不选择memcached呢,命中率?热插拔?还是性能。这里先不放结论,用事实来说话。
算法篇 -1.除余法
如果你手上有老版本的memcache官方文档。你会发现他们用的是除余法来保持节点的一致性。假如你有N台缓存服务器,你需要将某个对象set进某一台节点上。用hash取模这样可以很均匀的保证每台的负载。那么,作为最基本的轮询算法,是否适合分布式缓存我们来看实例。

这里假设有4台缓存节点,先设置除余方案。
自动设置999条键值。
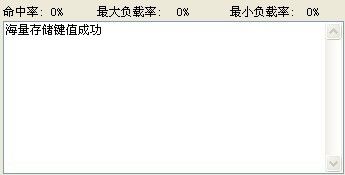
下面来看下除余方案的各种综合结果
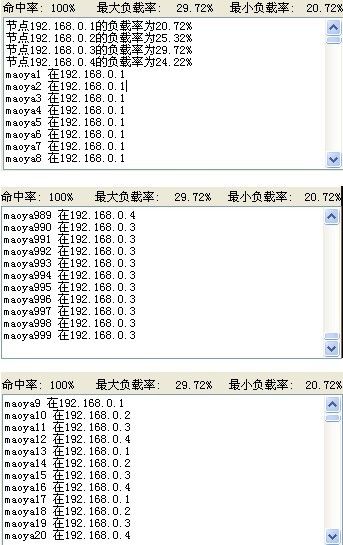
总的来说如果是相对稳定的环境 这种方案还是相当不错,至于性能我会单独开篇幅来说。
但是如果添加一台新节点 192.168.0.5
再来重新获取键值
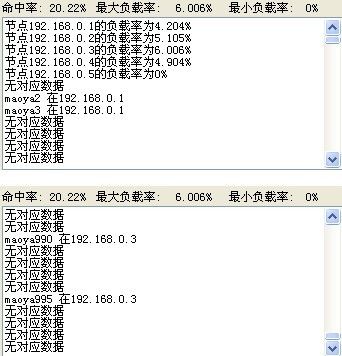
再随机追加200条键值
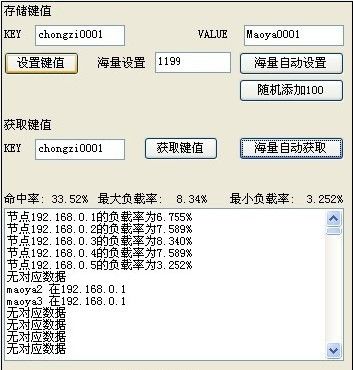
注意看数据中的命中率数据 新节点会投入环境 参与新的取模运算 但是之前因为模运算变化的键值就丢失了
算法篇 -2 普通hash算法
既然取模运算没办法保证我们的键值一致性,那么就要考虑新的方案了。不过设计我们自己的方案之前,我们可以继续看看memcache的使用者们进行了哪些改进。
通常的 hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2的32-1 次方的数值空间;
我不喜欢画图,大家就想象一下吧,一个首尾相接的圆。用hash算法将节点分布在圆的不同部位,同样对key值进行hash算法,通过
public static int BinarySearch<T>(T[] array, T value)方法,匹配到对应位置。
还是找了几张图过来.... 嘴拙 讲不清楚 直接看图吧
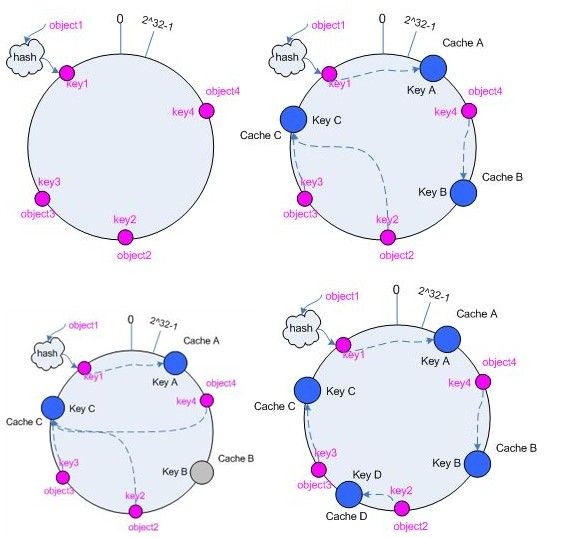
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。左下表示移除节点的情况,右下表示添加节点的情况
继续看图看结果

在稳定状态下 发现负载不是很平衡 不过还能接受 继续看看添加节点的情况
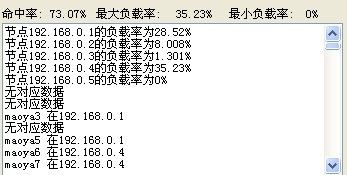
命中率变70多了 能hold住了 低要求的话 应该还是不错的,再看看新节点的利用情况,随机再生成200条
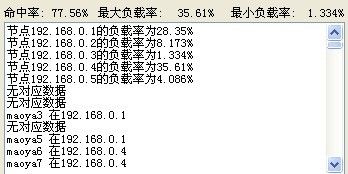
马马虎虎吧 负载偏差比较大 命中率一般
算法篇 -3 一致性hash算法 _ 虚拟节点 (consistent hashing)
相对普通hash算法 多了一个虚拟节点的概念 这也是目前memcache最主流的算法。
长话短说 就是我把一个节点虚拟成N多个虚节点 这些虚节点指向同一个物理节点 但是key值hash参照虚节点来设置
直接上图
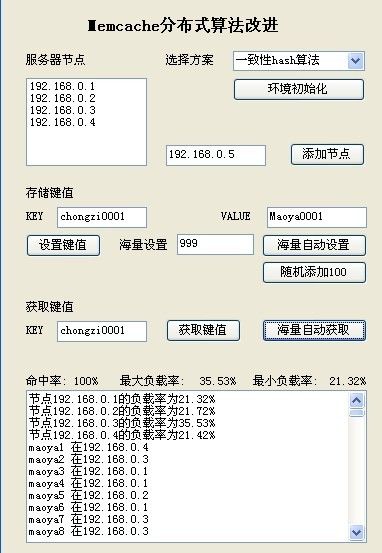
稳定状态下不错 同样我们在新添一个节点
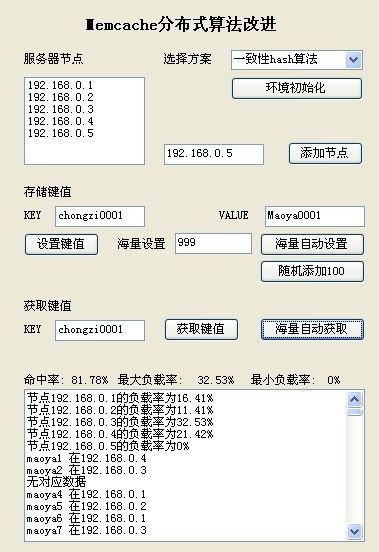
命中率提高了不上 不过负载还不是很平衡 随机再加300条
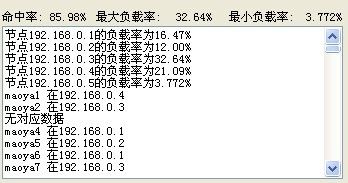
对比普通hash算法好多了
算法篇 -4 一致性hash算法改进
针对一致性hash算法的虚拟节点 说白了就是一个50大小的坑被拆成 5个10大小的坑而已,不过缝隙小了 对于比较聚集的数据来说还是很有好处的
如何改进 将50大小的坑就变成10大小 对于新增的节点 我们不进虚拟节点化或者个性配置节点化
前面效率和一致性hash比较类似 我们直接看添加节点的情况
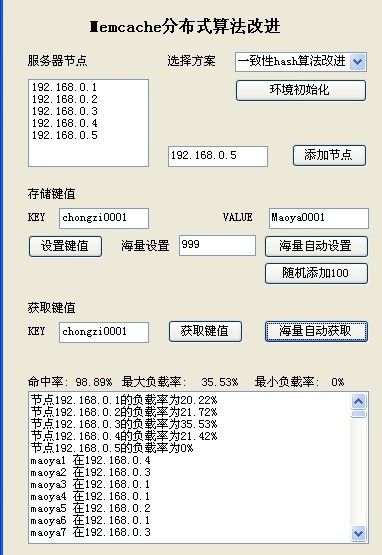
98% 有木有 有木有!!! 负载也还不错 你是不是已经被hold住了。
不过作为不良改进者 虫子还是要告诉大家这个改进一个很大的弊端 就是新节点的利用率
我们再随机新建600条键值
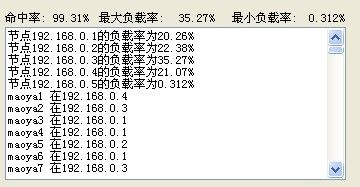
对于命中率的提高 是以新节点利用率为代价 至于之间怎么平衡 就看各自把握了
算法篇 -5 完美改进
上一种改进还是基于memcache现有的基础之上,跳出这个圈子为何要用一致性hash。
大家可以猜想一下这个方案的实现办法。关于这个方案的设计会单独开个篇幅来讲。
言归正传直接上图看结果
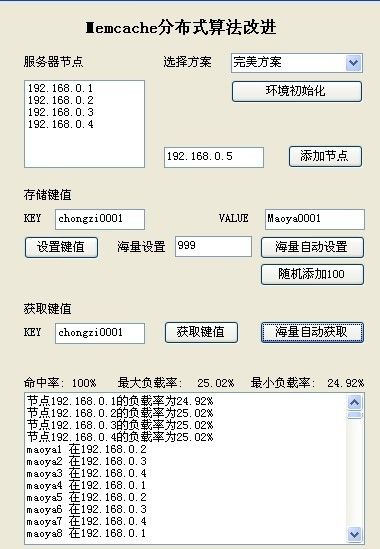
添加一台新服务器
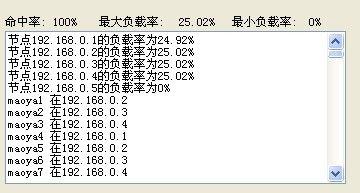
命中率还是100% hold住 还有更精彩的 我们随机添加500条键值

本篇先到此 希望对大家有帮助