版权所有, 如需转载请保留链接 http://wangbt5191-hotmail-com.iteye.com/blog/1734160
业务需求:
在仓库管理系统WMS中, 在订单发货前, 有一个发货拣单作业, 对订单进行分拣, 根据订单中的品类数量从货区获取商品, 在大量订单作业的过程中, 需要对产品品类相似的订单进行聚合, 也就是根据订单间货物的信息进行预先分组以方便分拣人员分拣。
问题分析
假如我们有数据:
Order1 : [Sku1: 2件 , Sku2: 1件] Order2 : [Sku2: 2件 , Sku3: 1件, Sku4: 1件] Order3 : [Sku2: 1件 , Sku4: 2件, Sku5: 1件]
我们假设现场有两个分拣线, 那么要分成两组, 那么我们该把Order1 和Order2 合并为一个Group 呢还是Order2 和Order3 合并? 那么合并的依据是什么? 我们怎么评价这个合并的方式比其他方式较优?
我们假设从采购车上来货的时候, 单品相商品在分捡过程中的数目对分拣复杂度不产生影响, 那么其实我们把每个Order 看成一个Set
Order1 ==> Set: [Sku1, Sku2] Order2 ==> Set: [Sku2, Sku3, Sku4] Order3 ==> Set: [Sku2, Sku4, Sku5]
那么问题就转变成, 如何为对已知的有一个个的Set 进行分组聚合。
对这个分组聚合我们又分为两个子问题:
1. 如何衡量两个Set 之间的相似度。
我们假设以函数Similarity(x, y)表示两个集合的相似度。
比如有以下4组集合
X={1, 2, 3} ; Y={1,2,3,4}; A = {1,2}; B= {1,2,3};
我们从感性上会认为 Similarity(X, Y) > Similarity(A, B);
那么比如以下4组集合
X= {1, 2, 3}; Y={1,2,3,4}, A = {1,2,3,5}, B= {1,2,3,4}
我们感性上认为 Similarity(X, Y) > Similarity(A, B)
2. 知道相似度算法后, 我们如何根据相似度进行聚合。
前一个问题涉及的是相似度算法, 后一个问题涉及到的是聚合算法。
数学建模
到这一节我们会涉及到很多数学集合运算的概念, 有关概念如果不清楚需要自行Google 之。到这一节我们会涉及到很多数学集合运算的概念, 有关概念如果不清楚需要自行Google 之。
1. 相似度算法建模
这里经典的有两种算法
Jaccard similarity
我们假设两个集合X和Y, 这两个集合的相似度在不考虑加权的情况下只和如下两个因素相关
A, B 的交集: A∩B
A, B 的并集: A ∪B
Jaccard similarity = |A ∩ B |/|A ∪ B |, 意思就是A,B 交集中的元素个数与A,B并集中个数的比值。
vector space similarity
我们假设两个集合A和B , 这两个集合的相似度在不考虑加权的情况下只和如下三个因素相关
A, B的交集: A∩B
A与B 的差集: A-B
B 与A的差集: B-A
({x∣x∈A,且x∉B}叫做A与B的差集)
我们假设 x = A∩B 元素数,y=A-B 元素数,z = B-A 元素数
vector similarity = x/sqrt( x *x + y*y + z*z ) . 
从空间向量上看就是, 有点的坐标是(x, y, z), 去度量该向量与x 轴的余弦值。 所以这个算法又得名空间向量相似度算法。
PS:
通过这个我们可以类推下如果一个计算结果和n 个因素相关, 而这n 个因素互相独立又互相关联, 我们可以认为第x 个因素在整个度量体系中算占的权重就是在N维空间里面的向量与第X维夹角的余弦值。
2. 聚合算法建模
聚合算法目前只找到中位算法比较适合我们的这个场景。
网上搜到的复杂的数学公式我就不上了, 这里就以图表加文字描述下它的原理。
假设我们现在 A--> R 18 个元素落在了一个二维平面上。我们要求把他们分成三个组;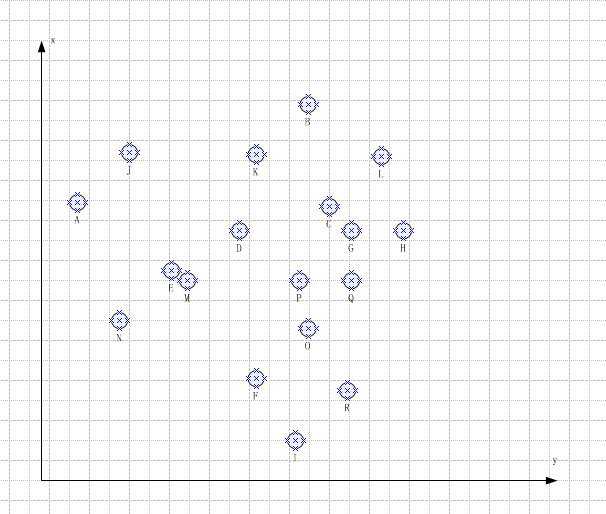
1. 随机选择N个元素作为特征种子元素
这里我们假设选择到了J, L, O 这三个元素作为特征种子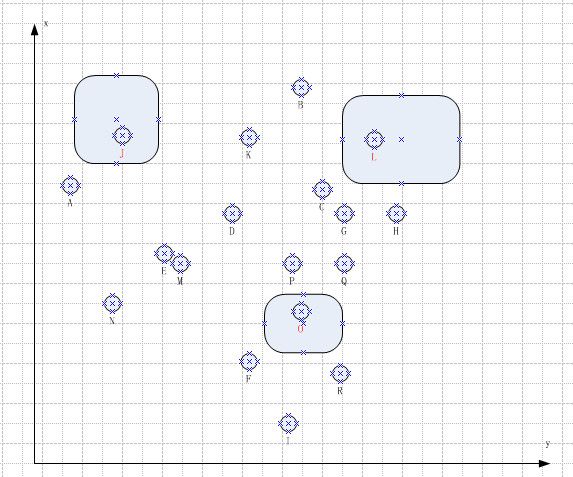
2.根据特征种子分划子集
遍历集合中除种子以为的元素, 计算当前元素与选择的三个种子的距离。 找到与当前节点距离最短的种子, 然后我们把当前元素划归到这个种子元素所在的子集合,
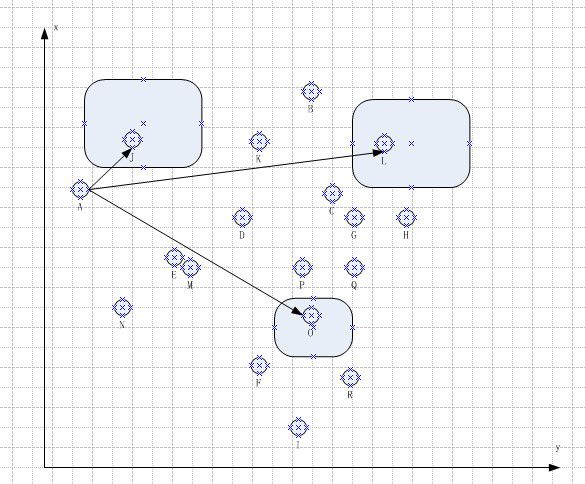
经过一轮的遍历和计算, 我们划出第一轮分组可以如下表示:
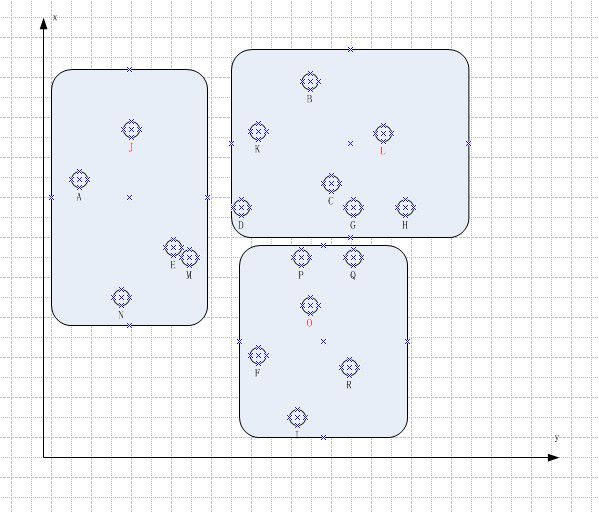
3. 为每个子集寻找特征种子
他的做法是在每个子集内部, 计算每个元素到子集内其他元素的距离总和, 然后我们可以找到这样一个元素, 以它为原点, 到其所在子集其他节点的距离最短;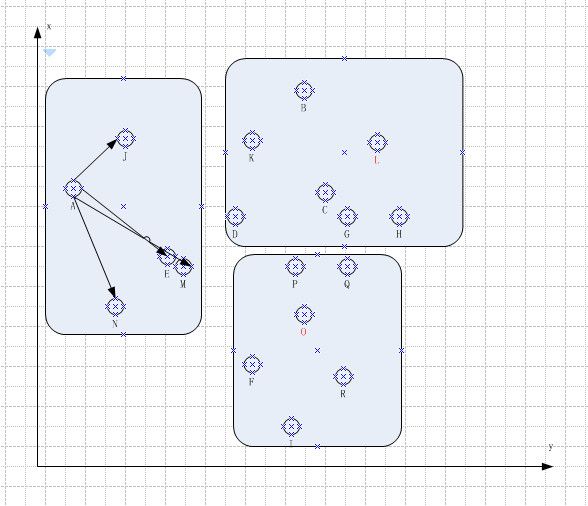
从这里我们可以看到E, C, O目测应该是新的特征种子。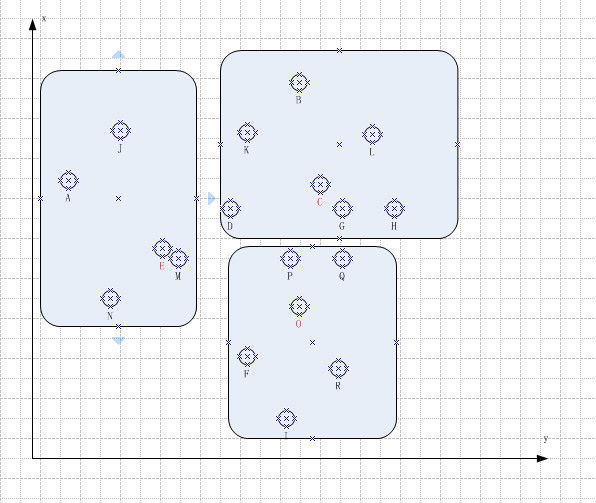
然后我们重复第二步到第三步的循环。
收敛判定:
这里我们可以看到我们从第二次划分子集开始, 就开始进行了循环, 那这里有个问题: 我们如何判断我们应该结束循环返回结果了?
这里有两个方案:
1. 暴力指定循环次数
2. 总种子距离比值比较
我们在子集中寻找种子的时候, 记录下每个子集中种子到其他元素的距离和,上图中, 我们这个数值就是 (E分别到A, J, M和N的距离和) + (C 分别到D, K, B, L, G 和H的距离和) + ( O 分别到P, Q , F , R 和I 的距离和)
每轮循环分划子集结束后, 如果这个值和上次的比值小于某个给定的阀值, 将停止循环
代码模拟
见附件